


SPEC
NVIDIA HGX B200のスペック
| 構成 |
シングルノード構成 |
|---|---|
| 特徴 | HGX B200 x1ノード |
| GPU/ノード | NVIDIA B200 SXM x8 |
| GPUメモリ/ノード | 総計1440 GB |
| GPUメモリ帯域幅 | 総計62TB/s(7.7TB/s x8) |
| GPU間通信(NVLink) | 総計14.4 TB/s(1.8TB/s x8) |
|
vCPU/ノード |
112コア相当 |
| システムメモリ/ノード | 4TB |
| ストレージ/ノード | 30TB NVMe |
|
演算性能 (FP16 Tensorコア) |
総計36PFLOPS (4.5PetaFLOPS x8) |
|
演算性能 (FP8 Tensorコア) |
総計72PetaFLOPS (9PetaFLOPS x8) |
|
演算性能 (FP4 Tensorコア) |
総計144PetaFLOPS (18PetaFLOPS x8) |
| リージョン | 日本 |


FEATURES
GPUSOROBANが選ばれる理由
| 選ばれる理由 01 |
NVIDIA H200を
すぐに使える
最新のNVIDIA H200をはじめとする高性能GPUを、申し込み後すぐに利用可能。AI開発やシミュレーションに最適な環境を、待ち時間なく提供します。
※B200予約受付中


| 選ばれる理由 02 |
自社データセンター運用で、
安定&高セキュリティ
国内に自社運営のデータセンターを構築し、安定した稼働と高いセキュリティを実現。大切なデータを安心してお預けいただけます。


| 選ばれる理由 03 |
国内最適価格。
クラウドなのにオンプレよりもお得
自社運用によるコスト削減を活かし、国内最適価格を実現。オンプレや他社クラウドサービスと比較して、圧倒的なコストパフォーマンスを提供します。

| 選ばれる理由 04 |
企業・研究機関を中心に
2,000件以上の利用実績
IT業界、製造業、建設業、大学研究機関まで幅広くご利用いただいています。高い性能とサポート体制で、プロフェッショナルのニーズに応えます。

こんなシーンで使われています

AIモデルの学習
(ロボット、画像生成など)
ロボットの視覚認識や画像生成AIのトレーニングには、大量のデータと高い計算能力が求められます。GPUSOROBANの高性能GPUは、これらのニーズに応え、迅速なモデル開発を可能にします。

LLMの基盤モデル開発
大規模言語モデル(LLM)のトレーニングには、膨大な計算リソースが必要です。GPUSOROBANは、LLMの開発やファインチューニングを行う企業や研究機関に、必要なGPU環境を提供します。

大学や企業での
短期研究プロジェクト
ロボットの視覚認識や画像生成AIのトレーニングには、大量のデータと高い計算能力が求められます。GPUSOROBANの高性能GPUは、これらのニーズに応え、迅速なモデル開発を可能にします。

専有可能な
生成AIインフラの構築
大規模言語モデル(LLM)のトレーニングには、膨大な計算リソースが必要です。GPUSOROBANは、LLMの開発やファインチューニングを行う企業や研究機関に、必要なGPU環境を提供します。
SECURITY SUPPORT
セキュリティ・サポート体制

ABOUT
GPUSOROBAN
「AIスパコンクラウド」とは?
「GPUSOROBAN」は、株式会社ハイレゾが提供するAI開発専用のGPUクラウドサービスです。
大量のデータを処理し、複雑なAIモデルを高速にトレーニング・実行できる、“スパコン並み”の計算性能をクラウドで手軽に使えるのが最大の特徴です。
MERIT
クラウド×B200の主なメリット
| 01 |
初期投資ゼロ&スケーラブル
- オンプレの場合、B200搭載マシンには数千万円規模の初期投資が必要となります。
- クラウドであれば、必要なときに必要な分だけ利用することができます。
- プロジェクトの内容やピークに応じて、スケールアップ・スケールダウンを柔軟に行うことが可能です。

| 02 |
すぐに開発をスタートできる
- NVIDIAドライバ、CUDA、Docker、Python、PyTorch、JupyterLabなどの環境をプリインストールした状態でご提供することが可能です。
- DockerHUBやNGC(NVIDIA GPU Cloud)などのリポジトリから取得したDockerイメージを用いて、コンテナを簡単に作成できるため、環境構築にかかる時間を大幅に削減できます。
| 03 |
AIトレーニング速度がH100の最大3倍
-
B200は、H100に比べて「最大3倍の速度」でLLMのトレーニングが可能です。
-
特にAI学習やディープラーニングといった計算負荷の大きな処理において、高い演算性能と効率性を発揮します。

| 04 |
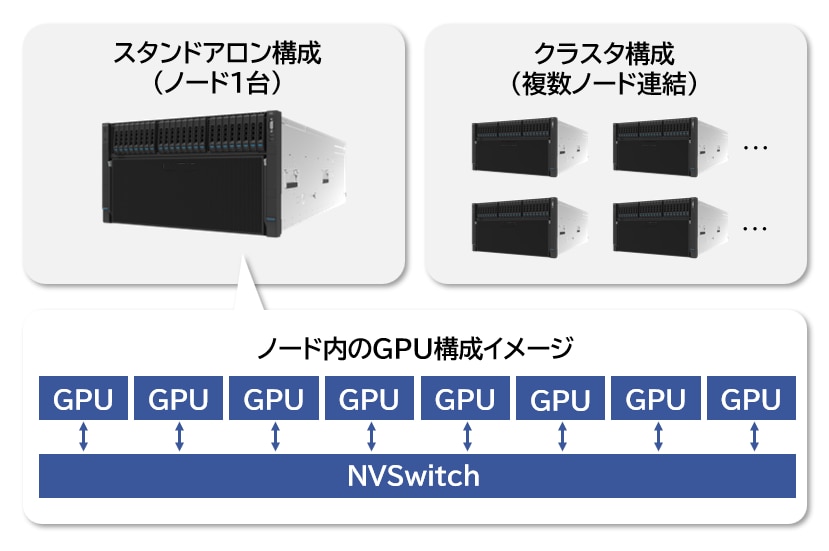
構築不要でGPUクラスタが使える
- インターネットさえあればアクセスして利用を開始でき、導入や管理の負担を大幅に減らすことが可能です。
- GPUインスタンス、ネットワーク、高速分散ストレージ、OS、ジョブスケジューラまで構築済みの状態から利用開始できます。

