
クラウドGPUの料金、見直しませんか?H200で検証するAWS・GCP・Azure vs GPUSOROBAN コスト徹底比較

AIワークロードのインフラを設計するとき、多くのエンジニアはまずAWS・GCP・Azureのマネージドサービスを検討します。
しかし、GPUインスタンスの料金ページを見ると、想定以上に高額だと感じるケースも少なくありません。
AWS p5.48xlarge(H100 x8):約$33/hr ≈ ¥5,082/hr
この料金は、AWSの「p5.48xlarge」というGPUサーバーを1時間使った場合の料金です。さらに見落としがちなのが、表示されている時間単価はあくまで「コンピュート料金のみ」という点です。
そこで本記事では、AWS・Azure・GCPのコスト構造を分解し、国産GPUクラウド「GPUSOROBAN」との比較を通じて、インフラ担当・デベロッパーエンジニアが知っておくべきGPU選定の判断軸を整理し解説します。
NVIDIA H200を搭載したGPUが、業界最安値で使える!
最先端のNVIDIA H200を、業界最安値クラスでご提供。学習・推論のスピードはそのままに、GPUコストを大幅圧縮。生成AI・LLM学習・シミュレーションなど大規模計算に最適。オンプレミスや他社クラウドと比べても圧倒的に低コストで、最新GPUを手軽に利用できます。



目次[非表示]
- 1.なぜ今、企業のGPUコストが経営課題になっているのか
- 2.メガクラウド 主要GPU料金(2026年4月時点・USD建て)
- 2.1.AWS p5e.48xlarge(H200×8)の月額換算コスト
- 2.2.GCP A3 Ultra(H200×8)の月額換算コスト
- 2.3.Azure ND H200 v5(H200×8)の月額換算コスト
- 2.4.GPUSOROBAN AIスパコンクラウド(H200×8)の月額費用
- 3.AWS/GCP/AzureのH200インスタンスが高い5つの構造的理由
- 3.1.理由1 世界的なGPUの供給逼迫とプレミアム価格
- 3.2.理由2 ドル建て課金 × 円安のダブルパンチ
- 3.3.理由3 データ転送料が見えないコストを生む
- 3.4.理由4 EBS・S3など周辺サービスとの抱き合わせ課金構造
- 3.5.理由5 グローバル冗長性・SLAコストが料金に上乗せされている
- 4.ケース別|どのGPUクラウドを選ぶべきか
- 4.1.LLMファインチューニング/事前学習:GPUSOROBANが最適
- 4.2.マルチモーダルAI開発:GPUSOROBAN+メガクラウドのハイブリッド
- 4.3.グローバル展開・既存AWS資産との連携が必須:AWS継続+一部GPUSOROBAN移行
- 4.4.スモールスタートのPoC → GPUSOROBAN無料トライアルから
- 5.コストだけじゃない!企業インフラ担当者がGPUSOROBANを選ぶ理由
- 5.1.30日間無料トライアルで本番移行前に検証可能
- 5.2.日本人エンジニアによる無料技術サポート
- 5.3.ドライバ・CUDA・PyTorchプリインストールで構築工数削減
- 5.4.国内データセンターによるデータ主権・コンプライアンス対応
- 6.よくある質問(FAQ)
- 7.GPU高騰時代を乗り切る現実解はGPUSOROBAN
なぜ今、企業のGPUコストが経営課題になっているのか

生成AIの活用が本格化する中で、企業にとってGPUはもはや一部の研究開発部門だけの資源ではなくなりました。
独自LLMの開発や推論環境の整備、マルチモーダルAIの実装が進むほど、高性能GPUの利用量は増え、コストはIT部門だけでなく経営判断に直結するテーマになっています。
ここでは、事前想定が崩れがちな要因を3つ紹介します。
- 生成AI/LLM内製化の波と急増するGPU需要
- H100からH200へ 必要スペックのインフレ
- PoC止まりを招く「クラウドGPU料金ショック」の実態
経営課題 | 01 |
生成AI/LLM内製化の波と急増するGPU需要
ChatGPTの登場以降、企業のAI活用は「使う」から「作る」フェーズへと急速に移行しました。
例えば、
社内データを学習させた独自LLMの開発
画像生成AIによる業務効率化
マルチモーダルAIを活用した新サービス
などの取り組みには、いずれも高性能GPUが不可欠です。
特に2025年から2026年にかけては、Llama 4をはじめとする70Bクラス以上のオープンソースLLMが台頭し、ファインチューニングや推論に必要なGPUメモリ要件が急上昇しました。
つまり、生成AIを本格的に活用しようとする企業ほど、GPUを「一部の研究開発コスト」ではなく、「事業を動かすための基盤コスト」として考える必要が出てきています。
経営課題 | 02 |
H100からH200へ——必要スペックのインフレ
H200はH100の後継機として2023年末に発表されたHopper世代の最新GPUで
HBM3eメモリを141GB搭載(H100比で1.7倍)
メモリ帯域幅は4,800GB/s(H100比1.4倍)
を誇ります。LLMでは「モデルがメモリに乗るか」が性能を決定づけるため、この差は決定的です。
問題は、この高性能GPUを各クラウドベンダーがどれだけのコストで提供しているか。そして、その料金が日本企業の予算と噛み合っているか、です。
経営課題 | 03 |
PoC止まりを招く「クラウドGPU料金ショック」の実態
実際、多くの企業ではこんな現象が起きています。
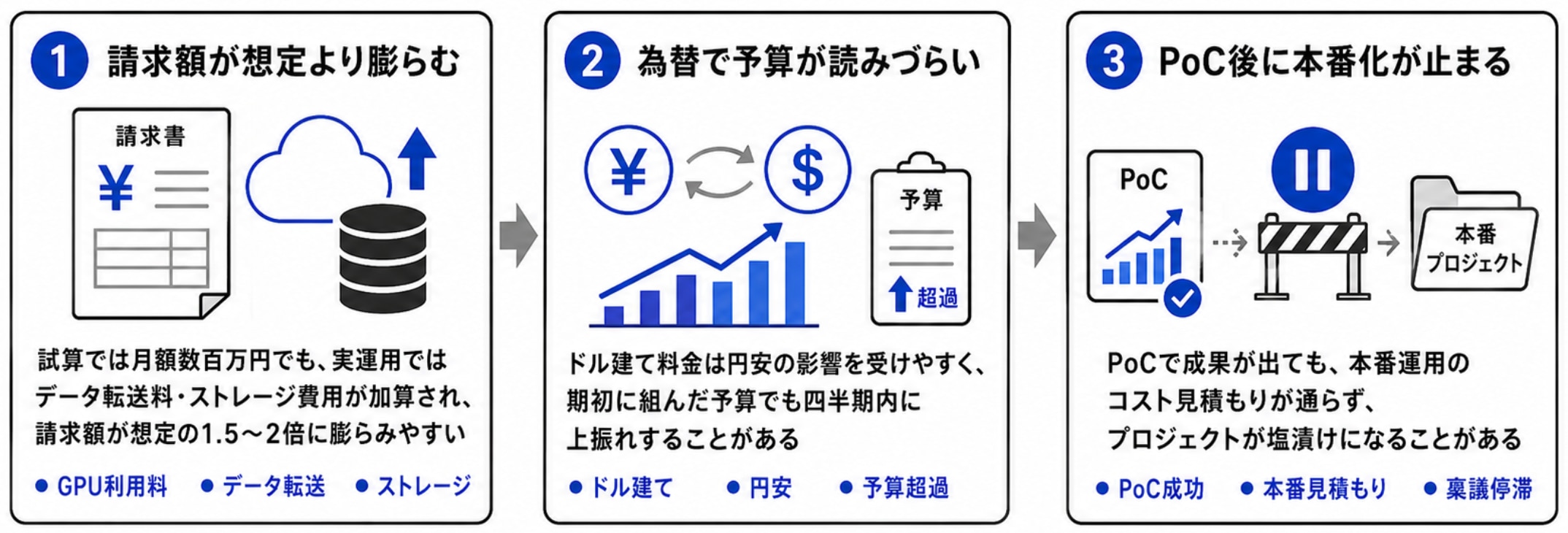
- 試算では月額数百万円のはずが、実運用してみるとデータ転送料・ストレージ費用が加算され、請求額が想定の1.5〜2倍に膨れ上がる
- 円安進行でドル建て料金が上振れし、期初の予算が四半期で枯渇
- PoCで成果が出ても、本番運用のコスト見積もりが通らずプロジェクトが塩漬け
これは個別企業の問題ではなく、メガクラウドのGPU料金が抱える「構造」が引き起こしている問題です。
メガクラウド 主要GPU料金(2026年4月時点・USD建て)

以下のデータは主要クラウドプロバイダーのオンデマンド料金です。いずれも米ドル建てで、為替レートによって円換算コストが変動します。
ここからは具体的な数字で比較します。条件は以下に統一しています。
- 構成: NVIDIA HGX H200 × 8基(GPUメモリ計1,128GB)
- 稼働: 1ヶ月720時間フル稼働
- 為替: 1ドル=159円(2026年4月時点)
- データ転送: 月1TB送信を仮定
AWS p5e.48xlarge(H200×8)の月額換算コスト
p5e.48xlargeはNVIDIA H200を8基搭載したハイエンドGPUインスタンスで、EC2 Capacity Blocksでの実効時間料金は多くのリージョンで39.799 USD/時(GPU1基あたり約4.975 USD/時)です。
時間単価は2026年1月の値上げ後で$39.80(US East基準)。
内訳 | 金額 |
|---|---|
インスタンス料金($39.80×720h) | $28,656 |
データ転送(1TB) | 約$92 |
EBS(1TB gp3) | 約$80 |
合計(USD) | 約$28,828 |
円換算 | 約458万円/月 |
東京リージョンや US West はさらに高額で、月額500万円超えるケースも見られます。
GCP A3 Ultra(H200×8)の月額換算コスト
GCPはH200搭載インスタンス「A3 Ultra」を提供しています。
1GPU時間あたり約$10.60、Spotで$3.72。8GPU構成のオンデマンドで時間あたり約$84です。
内訳 | 金額 |
|---|---|
インスタンス料金(8GPU×720h) | 約$60,000 |
データ転送(1TB) | 約$120 |
Persistent Disk(1TB) | 約$170 |
合計(USD) | 約$60,290 |
円換算 | 約959万円/月 |
※ GCPはオンデマンド料金が高めで、Committed Use Discount(1年/3年契約)で大幅割引が前提となる料金体系。短期PoCには割高です。
※ GCPの正確な料金は Google Cloud Pricing で最新情報をご確認ください。
Azure ND H200 v5(H200×8)の月額換算コスト
Azureも1GPU時間あたり約$10.60と、AWSやGCPと同水準の価格帯です。
内訳 | 金額 |
|---|---|
インスタンス料金 | 約$61,000 |
帯域 + ストレージ | 約$300 |
合計(USD) | 約$61,300 |
円換算 | 約975万円/月 |
※ Azureの正確な料金は Azure GPU VM Pricing で最新情報をご確認ください。
GPUSOROBAN AIスパコンクラウド(H200×8)の月額費用
GPUSOROBANは円建て・税込・データ転送料込みの完全パッケージ。
通常価格は月額2,783,000円。5年契約・20台以上で1台あたり月額1,391,500円となり、最大50%OFFが適用されます。
プラン | 月額(税込) |
|---|---|
通常プラン | 2,783,000円 |
長期割(最大50%OFF) | 1,391,500円〜 |
※それぞれの料金は需給に基づき定期的に更新されます。
GPUSOROBAN「高速コンピューティング」と他社GPUクラウド(AWS、GCP、Azure)の料金・性能比較の資料は、こちらからダウンロードできます。
AWS/GCP/AzureのH200インスタンスが高い5つの構造的理由

企業がGPUクラウドの選定でつまずきやすいのは、表面上のインスタンス単価と実際の総コストに差があるためです。
特にAWS、GCP、Azureでは、GPU調達コストの高騰に加え、為替、ネットワーク課金、周辺サービス費用、想定以上の負担につながります。
ここでは、その高コスト構造の理由を5つに分けて解説します。

理由1 世界的なGPUの供給逼迫とプレミアム価格
NVIDIAが2026年向けに受注したH200は約200万基、対して実際の出荷可能在庫は約70万基——3倍以上の需給ギャップが存在します。
メガクラウドはこの希少なGPUを大量調達する代わりに、ユーザー料金にプレミアムを乗せて回収する構造になっています。
理由2 ドル建て課金 × 円安のダブルパンチ
2026年4月時点で、米ドル/円相場は1ドル159円台で推移しています。AWSのp5e.48xlarge(H200×8)は2026年1月の値上げ後で時間あたり$39.80。これを円換算すると、1時間あたり約6,330円、1ヶ月(720時間)で約456万円です。
円安と値上げの掛け算で、日本企業の負担は加速度的に増大しているのです。

理由3 データ転送料が見えないコストを生む
AWS、GCP、Azureはいずれもインターネットへのデータ転送に課金します。AWSの場合、月100GB以上の転送には1GBあたり約$0.09が発生。
LLMの学習データ送信や推論結果の配信が頻繁に行われるユースケースでは、月数十万円〜数百万円規模の追加コストになります。

理由4 EBS・S3など周辺サービスとの抱き合わせ課金構造
GPUインスタンスを動かすには、ストレージ、ネットワーク、ロードバランサー、CloudWatchによる監視——と、複数のサービスを組み合わせる必要があります。
それぞれが従量課金されるため、「GPU時間単価」だけでは全体コストが見えないのがメガクラウドの特徴です。

理由5 グローバル冗長性・SLAコストが料金に上乗せされている
AWS、GCP、Azureは世界中にリージョンを持ち、99.99%級のSLAを保証する高度な冗長構成を組んでいます。
これは大規模Webサービスには必須の機能ですが、社内開発・研究用途のGPU計算には過剰スペックです。にもかかわらず、その運用コストは全ユーザーに薄く広く転嫁されています。
ケース別|どのGPUクラウドを選ぶべきか
GPUクラウドは、どのサービスが一律に優れているというものではありません。
LLMの学習やファインチューニング、マルチモーダルAI開発、既存クラウド資産との連携、PoCの立ち上げなど、用途や要件によって最適な選択肢は変わります。
ここでは代表的なケースごとに、どのGPUクラウドが適しているかを整理します。
CASE
01
LLMファインチューニング/事前学習:GPUSOROBANが最適
社内データでLlama 4やQwenをファインチューニングしたい、独自LLMを事前学習させたい——こうした長時間×高負荷×コスト最重要のワークロードは、GPUSOROBANの圧勝です。月額固定でデータ転送料も気にせず学習を回せるため、研究開発の試行回数を増やせます。
CASE
02
マルチモーダルAI開発:GPUSOROBAN+メガクラウドのハイブリッド
学習はGPUSOROBANのH200で、推論APIの配信はAWSやAzureで——という使い分けが現実的です。学習(=高GPU負荷・長時間)と推論(=低レイテンシ・グローバル配信)では最適なインフラが異なるためです。
CASE
03
グローバル展開・既存AWS資産との連携が必須:AWS継続+一部GPUSOROBAN移行
すでにAWSでサービス展開していて、IAM・VPC・S3などの資産がある場合は、無理に全面移行せず、GPU負荷の重い学習・研究用途だけGPUSOROBANに切り出すのが効率的です。
データ転送料込みのGPUSOROBANで学習を回し、結果モデルだけAWSに転送するパターンが定着しつつあります。
CASE
04
スモールスタートのPoC → GPUSOROBAN無料トライアルから
まず動かしてみたい、コスト感を掴みたい——という段階なら、GPUSOROBANの30日間無料トライアルから始めるのが最もリスクの低い選択です。
AWSで月数十万円のクレジットを切るより、無料枠で本番に近い検証ができます。
GPUSOROBAN「高速コンピューティング」と他社GPUクラウド(AWS、GCP、Azure)の料金・性能比較の資料は、こちらからダウンロードできます。
コストだけじゃない!企業インフラ担当者がGPUSOROBANを選ぶ理由

企業インフラ担当者にとって重要なのは、導入後に“困らない”ことです。GPUSOROBANは、無料での事前検証、国内エンジニアによる技術支援、セットアップ工数を抑える標準環境、国内完結のデータ管理体制を通じて、導入時と運用時の不安を大きく減らせるGPUクラウドです。
ここでは、以下に具体的な理由を4つにまとめました
- 30日間無料トライアルで本番移行前に検証可能
- 日本人エンジニアによる無料技術サポート
- ドライバ・CUDA・PyTorchプリインストールで構築工数削減
- 国内データセンターによるデータ主権・コンプライアンス対応
選ぶ理由 | 01 |
30日間無料トライアルで本番移行前に検証可能
GPUSOROBANでは、最新のNVIDIA H200搭載インスタンスを30日間無料で利用できるトライアルキャンペーンが実施されています。
LLM学習やマルチモーダルAI開発の検証はもちろん、他社クラウドからの移行前に性能・運用感を実機でチェックできるのは、メガクラウドにはない強みがあります。
選ぶ理由 | 02 |
日本人エンジニアによる無料技術サポート
GPUSOROBANでは、GPUエンジニアによる技術サポートが無料で受けられます。
基本的なレクチャーから環境構築の相談まで、日本語で対応してくれるため、英語ドキュメントとサポートチケットの往復に消耗することがありません。
選ぶ理由 | 03 |
ドライバ・CUDA・PyTorchプリインストールで構築工数削減
サーバー構築のメインであるNVIDIAドライバ、CUDA、Docker、Python、PyTorch、JupyterLabなどの環境がプリインストールされており、インスタンスを起動した時点で開発を始められます。
トライアル中なのに数日かけてセットアップが必要…というロスがなくなります。
選ぶ理由 | 04 |
国内データセンターによるデータ主権・コンプライアンス対応
学習データに個人情報や機密情報を含む場合、データを国外サーバーに置かない要件が発生するケースが増えています。
GPUSOROBANは、国内データセンターで運用されているため、データの国内完結が保証され、コンプライアンス・ガバナンスの面でも有利です。
よくある質問(FAQ)

Q. | AWSのSavings PlanやGCPのCUDを使えばもっと安くなりませんか? |
|---|---|
A. | 1年・3年コミットメントで30〜55%の割引が適用されます。ただし、コミットメントした分が未使用でも課金されるため、ワークロードの予測精度が重要です。GPUSOROBANの月額定額プランと組み合わせた場合のTCO比較は、無料トライアル後のご相談で対応できます。 |
Q. | AWSのEKS(Kubernetes)と連携できますか? |
|---|---|
A. | GPUSOROBANのインスタンスはSSHアクセス可能なLinux環境です。EKSのワーカーノードとしての直接組み込みは構成によりますが、GPUSOROBANで学習したモデルをS3に保存してAWSの推論インフラで利用する、といった構成は技術的に実現可能です。詳細は技術サポートにご相談ください。 |
Q. | データを国内に保存できますか?AWS東京リージョンと同等ですか? |
|---|---|
A. | はい。GPUSOROBANのデータセンターは国内にあります。ISO 27001・ISO 27017・Pマーク取得済みで、ISMS管理体制のもとデータを保護します。 |
Q. | 移行にどのくらいの工数がかかりますか? |
|---|---|
A. | Dockerベースの環境であれば、GPUSOROBANへのコンテナデプロイは数時間〜1日程度が目安です。GPUSOROBANの日本語技術サポートチームが環境構築を支援しますので、移行工数を最小化できます。 |
GPU高騰時代を乗り切る現実解はGPUSOROBAN

メガクラウドのGPU料金が高い理由は、需給逼迫、円安、データ転送料、抱き合わせ課金、過剰SLAという5つの構造的要因にあります。これらは個別企業の交渉や運用工夫では解決できません。
一方、GPUSOROBANは国内自社データセンター × AI特化型サービス × 円建て明朗会計という設計で、H200を業界最安級の月額278万円(長期割で139万円〜)で提供しています。AWS比で約4割、GCP/Azure比で約7割安——この差は3年運用すれば数千万円〜数億円規模になります。
「GPUコストが経営課題になっている」と感じているインフラ担当者の方は、まず30日間無料トライアルで現行ワークロードを動かしてみることを強くおすすめします。



