
RAGの構築とは?実装方法・精度向上のポイントまで解説

「RAGの構築・実装方法がわからない」という方も多いでしょう。そもそも、RAGとは、社内外に蓄積されたドキュメントやデータベースを検索し、その結果をもとに生成AIが回答を作成する仕組みのことを指します。
従来の生成AIは学習済みデータに依存するため、最新情報や自社特有の情報への対応が難しいという課題がありましたが、RAGを活用することで、こうした弱点を補いながら、より正確で実用的な回答を生成できるようになります。
そこで本記事では、
- RAGの基本的な仕組み
- 具体的な構築・実装方法
- 精度を高めるためのポイント
までを体系的に解説します。これからRAGの導入を検討している方や、すでに運用しているが精度に課題を感じている方は、ぜひ参考にしてください。
RAGの構築では、検索対象となるデータ整備や回答精度の設計だけでなく、実際に生成AIを安定稼働させるためのGPU基盤選びも欠かせません。特に、PoC段階で試したい企業や、できるだけ初期投資を抑えながらRAG環境を実装したい企業にとっては、どのようなGPUクラウドを選ぶかが、開発スピードや運用コストに直結します。
そこで、確認しておきたいのが「GPUSOROBAN まとめて資料ダウンロード」です。サービス概要だけでなく、ユースケース、他社比較、セキュリティ、導入実績までまとまっているため、RAGの実装基盤を具体的に検討したい方に適しています。構築方法の理解に加えて、実運用まで見据えて情報収集したい方は、あわせて確認してみてください。
目次[非表示]
- 1.そもそもRAGの構築とは?
- 1.1.RAGの仕組み
- 2.RAGの構築でできること・活用シーン
- 2.1.社内マニュアル・FAQ検索
- 2.2.技術資料・設計書・PDFの活用
- 2.3.カスタマーサポート業務への応用
- 3.RAGの実装・構築5ステップ
- 3.1.適切な情報の収集
- 3.2.チャンキングで精度を向上
- 3.3.テキストの埋め込み
- 3.4.セマンティック検索の実施
- 3.5.LLMによる応答生成
- 4.RAGの構築におすすめのフレームワーク
- 4.1.LlamaIndex
- 4.2.LangChain
- 4.3.Haystack
- 5.RAGの実装・構築における注意点
- 6.RAG構築を成功させるなら「GPUSOROBAN」
そもそもRAGの構築とは?
RAG(Retrieval-Augmented Generation)の構築とは、大規模言語モデル(LLM)が回答を生成する際に、外部の信頼できる情報源をリアルタイムで参照する仕組みをシステムに組み込むことです。
LLMに加えて社内データベースや特定の文書ファイルなど、指定したデータの中から関連情報を検索し、その内容を根拠として回答を生成することができます。
これにより、LLMで起こりがちなハルシネーションを抑制し、情報の正確性を担保した応答が可能になります。
RAGの仕組み
RAGの仕組みは「検索」と「生成」を組み合わせて回答精度を高める流れで成り立っています。下図のようにまず、ユーザーが「就業規則の在宅勤務ルールを教えて」のような質問を入力すると、AIはいきなり回答を作るのではなく、最初に社内文書・FAQ・マニュアル・データベースなどの中から関連情報を検索します。質問に関係する情報だけを抽出し、その内容を根拠として生成AIが回答を作成します。RAGの重要なポイントは、AIが事前学習した知識だけで答えるのではなく、検索して得た情報を参照して答える点にあります。
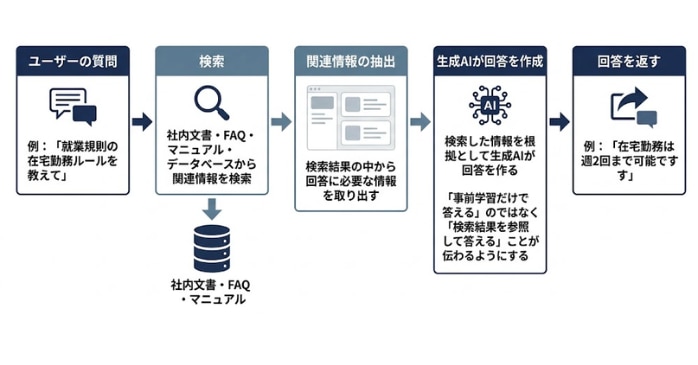
この仕組みによって、通常の生成AIだけでは対応しにくい社内独自のルールや最新情報にも答えやすくなります。たとえば、就業規則が更新されていた場合でも、検索対象の文書が最新化されていれば、その内容を踏まえた回答を返しやすくなります。
構築のハードルが高く感じた方は無料ツールから始めるAIエージェントのプログラム設計がおすすめです。
以下の記事で詳しく解説しています。
RAGの構築でできること・活用シーン

RAGを構築することで、企業が保有する膨大な独自データを有効活用し、業務の効率化や高度化を実現できます。ここでは、実際にRAGを導入して活用するシーンの代表的な例を3つ紹介します。
- 社内マニュアル・FAQ検索
- 技術資料・設計書・PDFの活用
- カスタマーサポート業務への応用
活用シーン | 01 |
社内マニュアル・FAQ検索
RAGは、社内に散在するマニュアルや規定集、過去の問い合わせ履歴などを集約したナレッジベースの検索システムとして活用できます。従業員が知りたいことをプロンプトで入力するだけで、AIが関連文書を探し出し、質問の意図に沿った的な回答を要約して提示します。
これにより、情報を探す手間が大幅に削減され、バックオフィス部門への問い合わせ対応工数の削減や、従業員の生産性向上に直結します。
活用シーン | 02 |
技術資料・設計書・PDFの活用
専門知識が詰まった技術資料や過去の設計書、研究論文といった非構造化データ(PDFやWord文書)の活用は、RAGの得意分野です。
特定の仕様や過去のプロジェクトで採用された技術について質問すると、RAGは何百ページにもわたる資料の中から該当箇所を瞬時に特定し、要点をまとめて回答することができます。
技術者や開発者は膨大なドキュメントを読み込む時間を節約でき、スムーズな開発フローが実現します。
活用シーン | 03 |
カスタマーサポート業務への応用
カスタマーサポートの現場では、顧客からの問い合わせに対して、製品マニュアルや過去の対応事例を基に回答案を自動生成するシステムを構築できます。
RAGを導入することで、オペレーターは参照すべき情報を即座に入手でき、回答作成の時間を短縮することが可能です。これにより、顧客の待ち時間が減り満足度が向上し、サポート品質の均一化が図れます。
RAGの実装・構築5ステップ

RAGシステムの実装は、大きく5つのステップに分けられます。
- 適切な情報の収集
- チャンキングで精度を向上
- テキストの埋め込み
- セマンティック検索の実施
- LLMによる応答生成
No.1 | 適切な情報の収集
最初のステップは、RAGの知識源となるデータを収集することです。 対象となるのは、社内サーバーに保管されているPDF、Word、Excelファイル、社内Wiki、データベース内の情報など、組織が保有するあらゆるデジタルデータです。 この段階で重要なのは、回答の根拠として信頼できる、正確かつ最新の情報源を選ぶことです。 収集したデータの質が最終的な回答の質に直接影響するため、誤った情報や古いデータは可能な限り排除し、整理しておく必要があります。 |
No.2 | チャンキングで精度を向上
収集したデータは、そのままでは効率的に処理できないため、「チャンキング」というプロセスで意味のある小さなチャンクに分割します。チャンクとは、文書を検索しやすく、かつ生成AIが参照しやすい単位に細かく区切ったテキストのまとまりのことです。 例えば、数千ページあるマニュアルを段落ごとやセクションごとに区切る作業です。 チャンクのサイズが小さすぎると文脈が失われ、大きすぎると検索のノイズが増えてしまいます。 そのため、検索精度と回答品質のバランスを考慮しながら、適切なサイズに分割する工夫が精度向上の鍵となります。 |
No.3 | テキストの埋め込み
RAGでチャンキングした後の「埋め込み(embedding)」は、検索品質の土台です。
で精度が大きく変わります。 チャンキングで分割した各テキストは、「埋め込み」と呼ばれる技術を用いて、意味を表現する数値のベクトルに変換されます。 この処理により、コンピュータは単語の文字列としてではなく、その意味内容としてテキストを捉えることが可能になります。 「PC」と「パソコン」のように表記が異なっていても、意味が近いためベクトル空間上で近い位置に配置されます。 |
No.4 | セマンティック検索の実施
ユーザーから質問が入力されると、その質問文も同様にベクトル化されます。 そして、その質問ベクトルとベクトルデータベースに保存されている全てのチャンクのベクトルを比較し、意味的に最も類似度が高いチャンクを複数選び出します。 これが「セマンティック検索」です。 従来のキーワード検索とは異なり、同義語や関連語も考慮した柔軟な検索が可能なため、ユーザーの意図を汲み取った精度の高い情報抽出が実現できます。 |
No.5 | LLMによる応答生成
最終ステップでは、セマンティック検索によって選び出された関連性の高いチャンクの情報と、ユーザーの元の質問文を組み合わせ、一つのプロンプトとしてLLMに入力します。 LLMは、提供されたチャンクの内容を「根拠」として、ユーザーの質問に回答する文章を生成します。 この仕組みにより、LLMが自身の内部知識だけで回答するのではなく、外部の正確な情報源に基づいて応答するため、ハルシネーションを効果的に防ぐことができるのです。 |




RAGの構築におすすめのフレームワーク

RAGの構築プロセスは複雑であるため、開発を効率化するためのオープンソースフレームワークを利用するのがおすすめです。
ここでは、その中でも代表的な3つのフレームワークを紹介します。
- LlamaIndex
- LangChain
- Haystack
LlamaIndex
 出典:LlamaIndex
出典:LlamaIndex
LlamaIndexは、LLMに外部データを取り込むことに特化したデータフレームワークです。 PDF、PowerPoint、各種APIなど、多様なデータソースからの情報取り込みを容易にする「データコネクタ」が豊富に用意されている点が強みです。
データの取り込みからインデックス化、検索クエリの実行まで、RAGの「Retrieval(検索)」部分のパイプラインをシンプルに構築したい場合におすすめ。主にデータ指向のLLMアプリケーション開発に適しています。
LangChain
 出典:LangChain
出典:LangChain
LangChainは、LLMを用いたアプリケーション開発のための汎用的なフレームワークです。
RAGの構築はもちろん、チャットボット、自律型エージェントなど、より複雑で多機能なアプリケーションを開発するための豊富なコンポーネントを提供しています。
複数のツールやLLMを組み合わせることで、高度な処理フローを柔軟に構築できるのが特徴です。 自由度が高い分、学習コストはやや高めですが、幅広い応用が可能で人気が高いフレームワークです。
Haystack
 出典:Haystack
出典:Haystack
Haystackは、特に大規模なテキストデータセットに対する自然言語での質問応答システムの構築に重点を置いたフレームワークです。
データの処理、検索、回答生成といったコンポーネントをパイプラインとして組み合わせるアーキテクチャが特徴で、システムのパフォーマンス評価やデバッグを支援する機能も充実しています。
エンタープライズレベルでの利用を想定しており、本番環境での運用を見据えた堅牢なRAGシステムを構築する際に適しています。
RAGの実装・構築における注意点

RAGシステムを構築し、実運用で価値を生むためには、 以下の点に注意して、期待した成果が得られるようにしましょう。
- パフォーマンスを維持するための工夫が必要
- データの質を最重視する
- RAG×LLMの性能向上はGPUが重要
注意点 | 01 |
パフォーマンスを維持するための工夫が必要
RAGは、ユーザーから質問を受けるたびに関連情報を検索し、必要な文書を抽出したうえで、LLMに内容を参照させて回答を生成する仕組みです。そのため、シンプルに見えて実際には複数の処理が連続して動いており、利用者の増加やデータ量の拡大にともなって、システム全体に負荷がかかりやすくなります。特に、
- 検索対象の文書が増える
- 同時にアクセスするユーザー数が多くなる
と、回答の生成までに時間がかかり、使い勝手が低下することがあります。
また、検索に時間がかかる、必要以上に多くの文書を読み込んでコストが膨らむ、処理を軽くしようとして検索条件を粗くした結果、回答精度が落ちるといったように、速度・費用・精度のすべてに影響が及ぶ可能性があります。RAGを安定して運用するためには、どの処理がボトルネックになりやすいのかを事前に把握し、先回りで設計しておきましょう。
注意点 | 02 |
データの質を最重視する
RAGシステムの回答品質は、参照させるデータの質に左右されます。どれほど性能の高いLLMを使っても、検索して取り出す情報そのものが古かったり、内容に誤りが含まれていたり、表現が曖昧だったりすれば、最終的な回答の品質も不安定になります。つまり、RAGではモデル性能だけでなく、検索対象となる文書やデータベースの整備状況が、そのまま回答品質に直結すると考えるべきです。
たとえば、
- 社内規程が改訂されているのに古い版の資料が残っている
- FAQごとに表現がばらばらで同じ内容を異なる言い方で記載している
と、検索時に不要な情報が混ざりやすくなります。その結果、AIが誤った情報を根拠に回答してしまうリスクが高まります。RAGの精度を高めたい場合には、その前段階にあるデータ整備のほうが重要になるケースも少なくありません。
注意点 | 03 |
RAG×LLMの性能向上はGPUが重要
RAGでは、文書を検索しやすい形に変換するためのベクトル化処理や、検索結果をもとにLLMが文章を生成する処理など、多くの計算が発生します。単なるテキスト処理に見えるかもしれませんが、実際には大量のデータを同時並行で処理する場面が多く、計算負荷は決して小さくありません。
こうした処理を効率よくこなすうえで重要になるのがGPUです。GPUは並列計算に強く、LLMの推論やベクトル生成のように、多数の計算を一度にさばく処理と相性が良いため、より高速かつ安定した運用を実現しやすくなります。実運用を見据えて応答速度や同時接続数を重視するなら、GPUの活用はおすすめです。
RAGは、検索対象のデータ量が増えるほどベクトル化や推論処理の負荷が高まりやすく、実運用では「精度」だけでなく「応答速度」や「安定性」まで含めて基盤を設計することが重要になります。
とくに、PoCから本番運用へ進む段階では、どの程度のGPUリソースを確保すべきか、他社サービスと比べて何が違うのか、導入後にどのような運用イメージになるのかを事前に整理しておきたいところです。そこで参考になるのが、GPUSOROBANのまとめて資料ダウンロードです。
ユースケース、他社GPUクラウドとの比較、セキュリティ、導入実績までまとめて確認できるため、RAG×LLMの基盤選定を進めたい方に適しています。構築後の性能面まで見据えて情報収集したい方は、ぜひ一度ご確認ください。
RAG構築を成功させるなら「GPUSOROBAN」

RAGの構築は、単に生成AIへ文書を読ませれば実現できるものではありません。信頼できる情報を集め、適切な単位でチャンキングし、埋め込みやセマンティック検索を通じて必要な情報を正しく取り出し、そのうえでLLMに回答を生成させるという一連の設計がそろって初めて、実務で使える仕組みになります。
PoC段階では動いていても、本番環境では速度やコスト、精度のバランスが崩れるケースもあるため、早い段階から実装後の運用まで見据えて設計することが重要です。
また、RAGの導入を具体的に進めたい場合は、仕組みの理解だけでなく、どのようなGPU基盤を選ぶべきか、他社GPUクラウドと比べて何が違うのか、実際にどのような導入事例があるのかまで整理しておくと判断しやすくなります。GPUSOROBANの「まとめて資料ダウンロード」では、基本的なサービス説明に加え、ユースケース、他社GPUクラウドとの比較、セキュリティ、導入実績までまとめて確認できます。
以下のリンクからダウンロードしてみてください。




