
【画像生成AI】CycleGANによる画像のスタイル変換
本記事ではGPUSOROBANのインスタンスを使ったCycleGANによる画像のスタイル変換を紹介します。
GPUSOROBAN(高速コンピューティング)は高性能なGPUインスタンスが低コストで使えるクラウドサービスです。
サービスについて詳しく知りたい方は、GPUSOROBANの公式サイトを御覧ください。
目次[非表示]
CycleGANとは
CycleGANは、"Cycle-Consistent Generative Adversarial Networks"の略で、異なるドメイン間で画像のスタイルを変換するための技術です。スタイル変換とはデータの外見的特徴を変換することです。ドメインとはある特定の特徴を有するデータの集合を指します。例えば馬の画像やシマウマの画像は異なる特徴をもつドメインになります。画像のスタイル変換とは、あるドメインの画像をインプットし異なるドメインの画像へ変換することです。本記事では馬の画像をシマウマの画像に変換するタスクを行います。

出典:https://arxiv.org/abs/1703.10593 Zhu, J., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.
CycleGANのアーキテクチャには、「敵対的損失(Adversarial Loss)」「サイクル一貫性損失(Cycle Consistency Loss)」「自己同一性損失(Identity Mapping Loss)」の3つの特徴があります。
敵対的損失(Adversarial Loss)
CycleGANのアーキテクチャは、画像生成モデルGANのGenerator(生成器)とDiscriminator(判別器)という2つのネットワークをベースにしています。Generatorは、ランダムなノイズを入力として、Discriminatorが本物と誤認するデータを生成できるように学習します。一方でDiscriminatorは、本物のデータとGeneratorが生成した偽物のデータを正しく識別できるように学習します。これらのGeneratorとDiscriminatorは、互いに競わせるように学習していきます。これらの学習プロセスで使用される損失を「敵対的損失(Adversarial Loss)」と呼びます。
敵対的損失の例を図で解説します。図の緑の矢印に注目すると、馬(A)の本物画像を入力し、シマウマ(B)の偽物画像を生成しています。生成したシマウマ(B)の偽物画像をDiscriminatorBに入力し、シマウマの画像として偽物[0]か本物[1]かの判別をします。この判別結果による損失がGenerator Bにフィードバックされ(緑の点線)、本物に近い偽物を生成できるように学習をします。
一方のDiscriminatorBは、シマウマ(B)の偽物画像とシマウマ(B)の本物画像が入力され、シマウマの画像として偽物[0]と本物[1]かを判別します。この判別結果による損失をDiscriminatorBにフィードバックし(緑の点線)、偽物と本物をただしく判別できるように学習します。
通常のGANでは、図の緑の矢印で示した一つのネットワークのみになりますが、CycleGANでは青の矢印で示すように別のネットワークがあります。青の矢印では、緑の矢印で説明したことの逆を実行しています。シマウマ(B)の本物画像のインプットから始まり、最終的にそれぞれのGenerator AとDiscriminator Aが学習する流れになります。
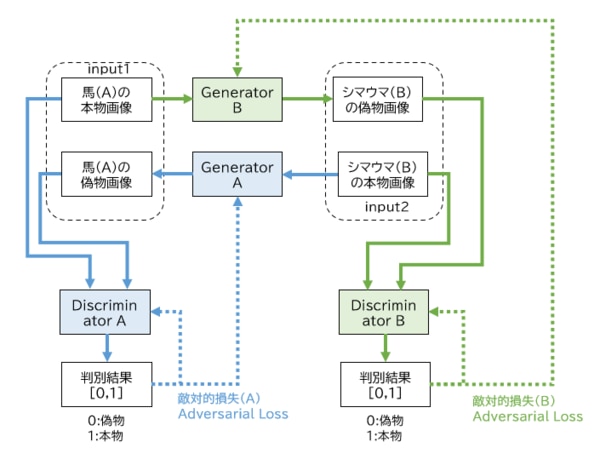
(図)敵対的損失のしくみ
Generator A = 馬(A)の偽物画像を生成するGenerator
Generator B = シマウマ(B)の偽物画像を生成するGenerator
Discriminator A = 馬(A)の本物画像と偽物画像を判別するDiscriminator
Discriminator B = シマウマ(B)の本物画像と偽物画像を判別するDiscriminator
サイクル一貫性損失(Cycle Consistency Loss)
「サイクル一貫性損失(Cycle Consistency Loss)」はCycleGANにおいて、主要な特徴になります。
サイクル一貫性損失を図の例に説明します。図の緑の矢印に注目してみると、馬(A)の本物画像をGenerator Bに入力し、シマウマ(B)の偽物画像を生成しています。次にこのシマウマ(B)の偽物画像をGenerator Aに入力し、馬(A)の偽物画像を生成します。
このプロセスをまとめると、「馬(A)の本物画像 → シマウマ(B)の偽物画像 → 馬(A)の偽物画像」となり、馬(A)の本物画像から馬(A)の偽物画像を再構成したことになります。途中でシマウマに変換されているものの、馬から生成された馬になりますので、このプロセスにおける馬(A)の本物画像と馬(A)の偽物画像は、同じになるべき(一貫性があるべき)というのがサイクル一貫性損失の根幹になります。この考えに基づいて、馬(A)の本物画像と馬(A)の偽物画像のピクセル間の差を損失として計算し(緑の点線)、この損失をフィードバックし、Generator BおよびGenerator Aを学習します。
青の矢印は、緑の矢印の逆のプロセスを実行しています。シマウマ(B)の本物画像から始まり、シマウマ(B)の偽物画像を再構成し、この損失をGenerator BとGenerator Aにフィードバックし学習しています。再構成された画像が元の入力画像に近づくように学習され、画像の一貫性をもつことで変換の品質が向上します。
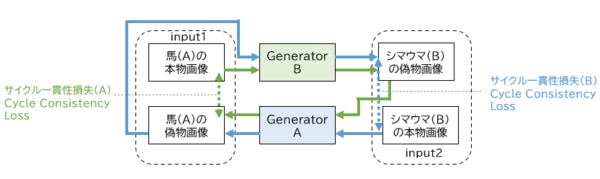
(図)サイクル一貫性損失のしくみ
Generator A = 馬(A)の偽物画像を生成するGenerator
Generator B = シマウマ(B)の偽物画像を生成するGenerator
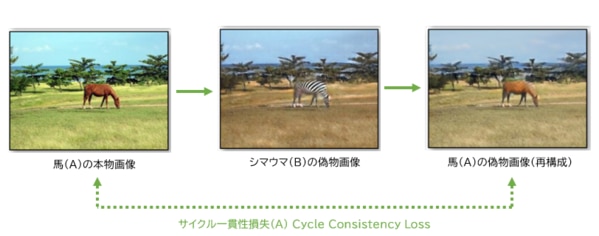
参考:https://arxiv.org/abs/1703.10593
Zhu, J., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.
自己同一性損失(Identity Mapping Loss)
CycleGANの3つめの特徴の「自己同一性損失(Identity Mapping Loss)」について説明します。
図の緑の矢印に注目してみると、馬(A)の本物画像をGenerator Aに入力し、馬(A)の偽物画像を生成しています。Generator Aは、馬を生成するGeneratorになりますので、馬を入力した場合は、馬から馬がそのまま生成されることになります。馬から馬を生成するため、入力と出力に差異はないという考えのもと、馬(A)の本物画像と馬(A)の偽物画像のピクセル画像の差を損失として計算し、Generator Aにフィードバックして学習します。
一方で青の矢印では、緑の矢印の逆を実行しています。シマウマ(B)の本物画像の入力から始まり、シマウマ(B)の偽物画像を生成し、2つの画像差を損失として計算し、Generator Bにフィードバックしています。
なぜこのような損失計算をするかというと、元の画像を変更する必要がないときは、Generatorに変更を加えさせないよう学習させるためです。論文では、自己同一性損失を使うことで、入力画像の色を保持する効果があったと言われています。(自己同一性損失がない場合は、色が大幅に変化していた)
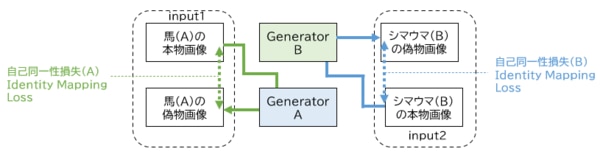
(図)自己同一性損失のしくみ
Generator A = 馬(A)の偽物画像を生成するGenerator
Generator B = シマウマ(B)の偽物画像を生成するGenerator
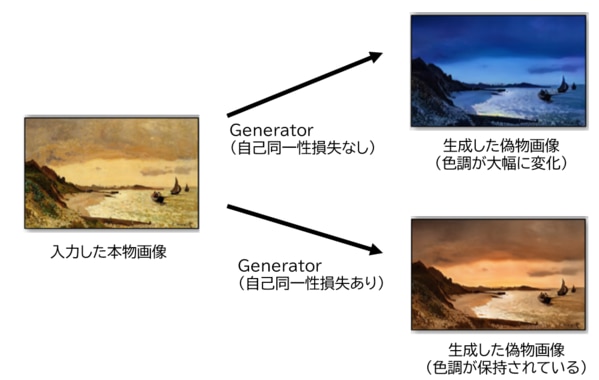
(図)自己同一性損失を使用した場合に生成画像の色調が保持される例
出典:https://arxiv.org/abs/1703.10593 Zhu, J., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.
環境構築
環境はGPUSOROBANのnvd4-80-1ulインスタンスを使用します。
nvd4-80-1ulは、NVIDIA A100を搭載した高性能GPUインスタンスです。機械学習を高速化するTensorコアや大容量GPUメモリ(80GB)が特徴です。後にGoogle ColaboratoryのNVIDIA T4との学習時間を比較してみます。
GPUSOROBANのインスタンスの作成方法、秘密鍵の設置方法については、会員登録~インスタンス作成手順の記事をご覧ください。
インスタンスの作成と秘密鍵の設定が完了しましたら、アクセスサーバーおよびインスタンスに接続をします。
本記事ではJupyterLabを使用するため、上記の手順書のインスタンス接続のコマンドと異なりますので、ご注意ください。
アクセスサーバーへの接続
インスタンスへの接続方法
インスタンス接続が完了しましたら、PyTorch、JupyterLabをインストールします。
(参考)PyTorchのインストール(Ubuntu)の記事
(参考)Jupyter Labのインストール(Ubuntu)の記事
Jupyterを起動後に、各種ライブラリをインストールします。
パッケージをアップデートします。
各種ライブラリをインストールおよびインポートします。
データセットのダウンロード・前処理
一般公開されている馬とシマウマのデータセットをダウンロードし、解凍します。
データを格納するディレクトリを作成し、ダウンロードしたデータセットを移動します。
格納したデータセットを確認します。
バッチサイズおよびデータローダーの設定をします。
論文を踏襲しバッチサイズを1に設定しています。バッチサイズが小さい方がCycleganの画像変換の精度が向上すると言われています。
画像を表示する関数を定義します。
学習に使用する画像の表示します。


Generatorの定義
Generatorで使用するResidual blockを定義します。
Residual blockは、複数のResNetをまとめたものになります。ResNetを使用する目的は、深い層のネットワークを構築する際の勾配消失問題に対処するためです。通常の畳み込みニューラルネットワークでは、層が深くなるにつれ勾配がゼロに近づく勾配消失の問題があります。ResNetでは、入力データが層のブロック(Convolution block)をスキップして出力に直接接続します。これにより配消失問題を緩和します。
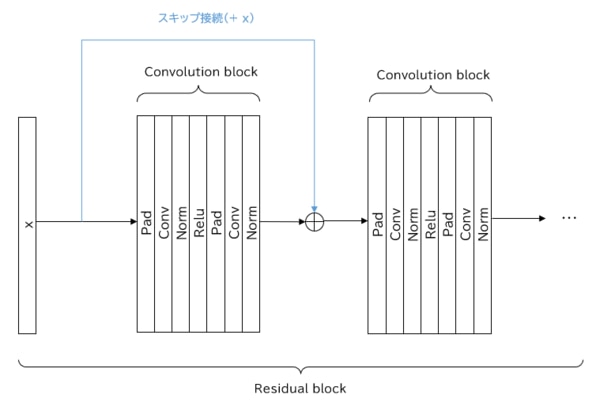
データの正規化において、バッチノーマライゼーションではなく、インスタンスノーマライゼーションを使用しています。
バッチノーマライゼーションはミニバッチごとに平均・分散で正規化することから、ミニバッチのサイズが小さいと推定される平均・分散が正確ではなくなり、学習が安定しないことがあります。一方でインスタンスノーマライゼーションは、各サンプルごと(例えば、画像内のピクセルごと)に正規化します。この手法は、各サンプルにおいて平均・分散に正規化するため、ミニバッチ中のサンプル数が少なくても問題ありません。
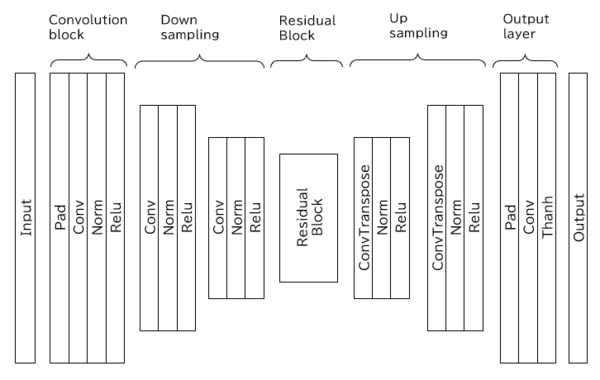
Generatorを定義します。Generatorは5つのブロックで構成されています。それぞれのブロックの説明は次のとおりです。
1.Convolution block:畳み込みによって、入力画像から特徴を抽出します。
2.Down sampling:ダウンサンプリングは、特徴マップのサイズを縮小し、画像の情報を階層的に抽象化し、高次の特徴を抽出します。
3.Residual block:畳み込みと入力のスキップ接続を繰り返し、細かい特徴を抽出します。
4.Up sampling:ダウンサンプリングによって縮小した特徴マップを元のサイズに戻し、解像度を上げて画像を生成します。
5.Output layer:パディングと畳み込みでチャンネル数に合わせた画像を生成し、Tanhを使用して-1から1の範囲で出力しています。
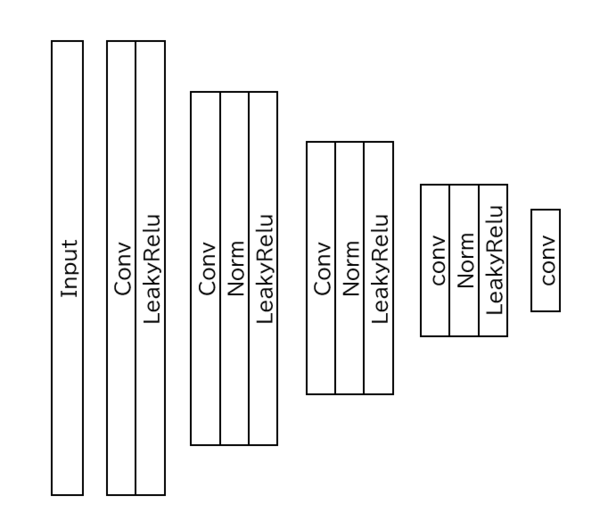
Discriminatorの定義
Discriminatorでは、主に畳み込み→正規化→LeakyReLuを繰り返すダウンサンプリングをして、特徴量の抽出を行っています。
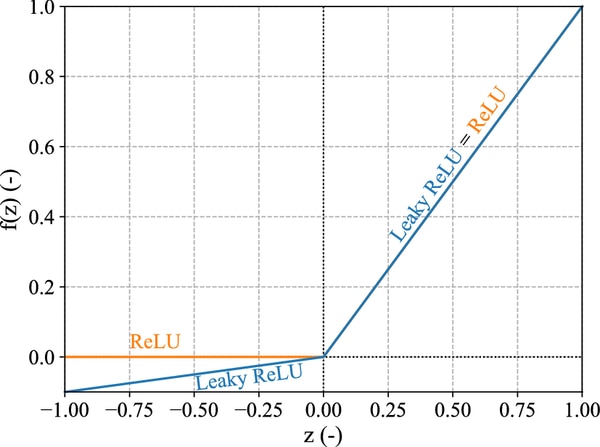
逆伝播での勾配消失問題に対処するために、活性化関数にLeakyReLUを使用しています。通常のReLUでは負の入力で、0が出力されるため、微分ができず勾配消失に陥る可能性があります。LeakyReLUは負の入力に対し、微小な負の値を出力することができます。微分値が常に0にならないので、勾配消失問題の対処が可能です。図はReLUとLeaky ReLuの違いを示しています。
出力画像のサイズについては、下記の式で計算されます。
O = (I - F + 2P)/S + 1
O:出力画像のサイズ(高さ or 幅)
I:入力画像のサイズ(高さ or 幅)
F:カーネル(フィルタ)のサイズ(高さ or 幅)
P:パディング幅
S:ストライド幅
重みの初期化を行う関数について定義します。
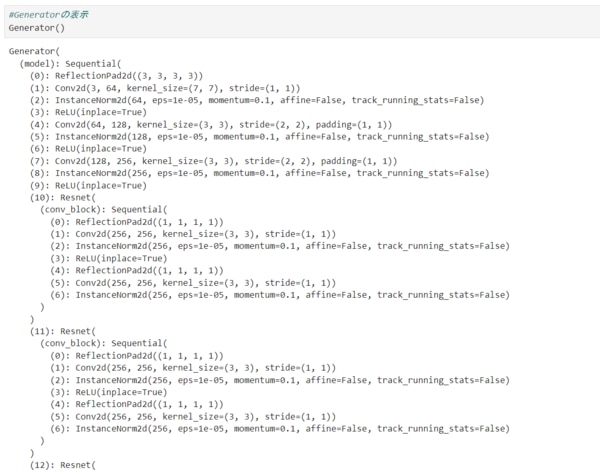
定義したGeneratorを表示します。
定義したDiscriminatorを表示します。

各関数の定義
学習率のスケジューリングを定義します。
一度生成した画像を再利用するクラスを定義します。
学習中のログを表示する関数を定義します。
チェックポイントのパスを生成する関数を定義します。
学習に関する情報を保存する関数を定義します。
学習中に生成されたデータやモデルの状態を保存する関数を定義します。
保存されたモデルの状態を読み込む関数を定義します。
学習のステップを定義します。
クラスのインスタンス化
モデルをインスタンス化し、重みの初期化設定を適用します。
損失関数をインスタンス化します。
敵対的損失の計算においては、平均二乗誤差(MSE)を使用しています。通常使用されるBinaryCrossEntropy(BCE)と比べ、MSEのほうがGeneratorとDiscriminatorの乖離が小さく、学習が安定しやすいと言われています。
サイクル一貫性損失、自己同一性損失の計算においては、L1ノルムを使用します。L1ノルムを使うことで、ピクセル間の差の絶対値として表現し、小さな誤差にも対応します。
敵対的損失を計算するためのターゲットを設定します。
ハイパーパラメータの設定と学習の実行
論文を参考に学習率、エポック、学習率の減衰について指定しています。
保存データの利用確認をします。

オプティマイザと学習スケジューラーの設定をします。
学習に関する情報を保存します。
学習を実行します。

(↑GPUSOROBAN nvd4-80-1インスタンスでの学習時間:1epoch平均2.7分, 200epoch合計で約9時間)
GPUSOROBANのnvd4-80-1インスタンスで、200epochの学習で約9時間(550分)ほどの時間がかかりました。1epochあたりの学習時間は平均2.7分になります。
一方でGoogle ColaboratoryのNVIDIA T4インスタンスでは、約3時間を経過した19epochの段階で自動的にランタイムが切断され、途中停止していました。Google Colaboratoryでは1epochあたりの学習時間は平均11.4分になりましたので、単純計算でGPUSOROBANが4倍速い結果になりました。
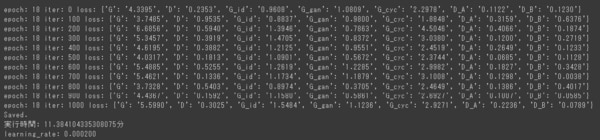
(↑Google ColaboratoryのNVIDIA T4インスタンスの学習時間:1epoch平均11.4分, 200epoch合計は不明 ※学習が途中で停止していたため)
学習済みモデルのテスト
ここからは学習済みモデルのテストを行います。
テスト用データの前処理およびデータローダーでデータセットを読み込みます。
生成した画像を保存する関数を定義します。
学習済みモデルのデータをロードします。
load_model_dataの関数を実行します。
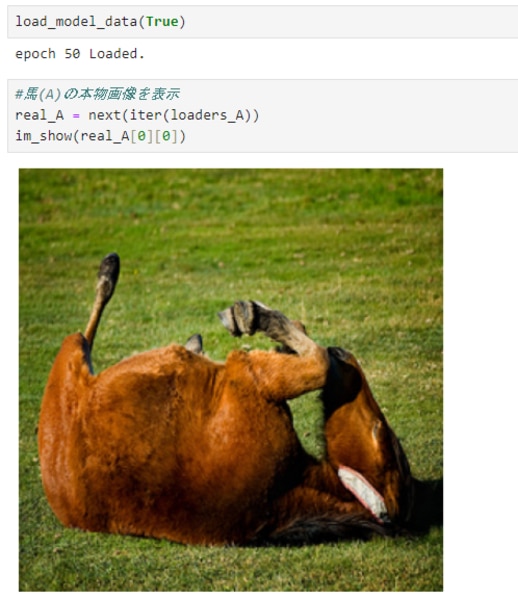
馬(A)を学習済みモデルにインプットして、シマウマ(B)に変換されるかepochごとに確認していきます。
10epochまで学習したモデルでは、部分的にシマウマに変換されていることが分かります。


50epochまでの学習したモデルでは、全体的にシマウマの模様に変換されましたが、変換前の馬の色味が一部残っています。

200epochまでの学習では、全体的にシマウマに変換され、元の馬の色味もほぼ残っていません。


CycleGANによるスタイル画像変換の説明は以上になります。
本環境には、GPUSOROBAN(高速コンピューティング)のインスタンスを使用しました。
高速コンピューティングは、高性能なGPUインスタンスが低コストで使えるクラウドサービスです。
サービスについて詳しく知りたい方は、公式サイトをご覧ください。


