

Windows+WSL2+DockerでGPUの環境構築
Windows PCでGPUを使用する際に、Dockerを使うと簡単に環境を構築できます。
この記事では、Windows PCにWSL2、Docker、NVIDIAドライバ、CUDAをインストールして、GPUを使う方法を紹介します。
目次[非表示]
実行環境
この記事では以下のスペックのローカル環境のWidows PCを使用しました。
- OS:Windows 11
- GPU:NVIDIA A4000
- GPUメモリ(VRAM):16GB
NVIDIAドライバのアップグレード
NVIDIA Driverを最新版にアップグレードします。(NVIDIAドライバ515以上)
NVIDIAドライバダウンロードのページを開きます。
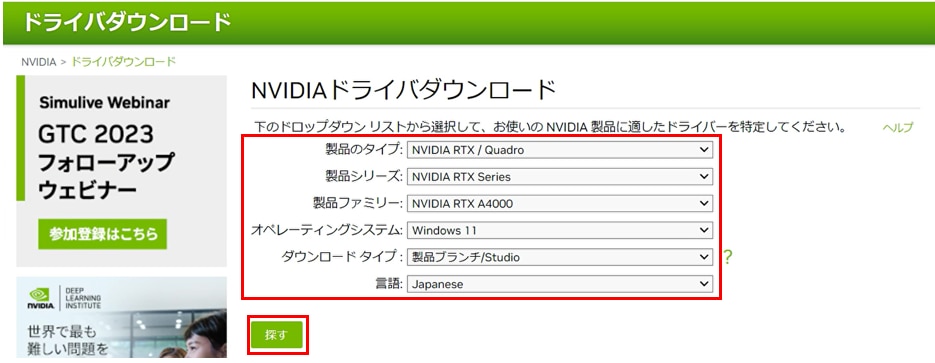
ご使用のGPUのタイプにあわせて項目を選択します。
[オペレーティングシステム]はお使いのOSを選択してください。
[ダウンロードタイプ]は”Studio”が含まれる項目を選択してください。
項目を選択したら、[探す]ボタンを押します。
以下はGPUがNVIDIA RTX A4000の場合の例です。
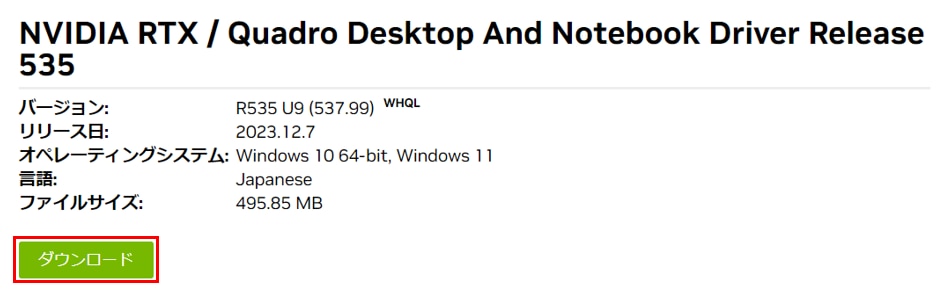
続けて[ダウンロード]ボタン、[ダウンロードの同意]をクリックし、インストーラーをダウンロードします。
ダウンロードした[インストーラー]を実行し、インストールを開始します。
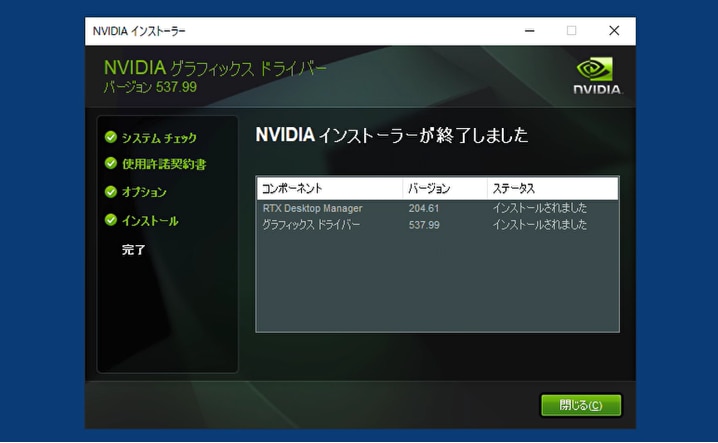
[NVIDIAインストーラーが終了しました]の表示がでたら、NVIDIAドライバのインストールが完了です。
WSL・Ubuntuのインストール
[スタート]から[コマンドプロンプト]を開きます。

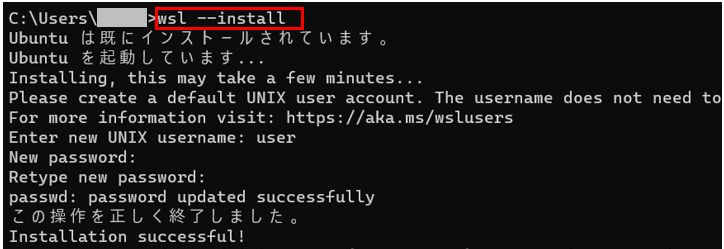
コマンドプロンプトで次のコマンドを実行し、wsl2およびUbuntuをインストールします。
[Enter new UNIX username:] と表示がされるのでユーザー名を設定します。
この記事では”user”をユーザー名として設定します。
[New password:] と表示がされるので任意のパスワードを設定します。
Windowsを再起動し、変更を有効化します。
コマンドプロンプトで次のコマンドを実行し、WSLのバージョンを確認します。

VERSIONが[1]の場合は、次のコマンドを実行し、既存のディストリビューションをWSL2 に変更します。
※VERSIONが既に[2]の場合は、このステップは飛ばしてください。
Wiindowsの[スタート]から”Ubuntu”を検索し、起動します。
Dockerのリポジトリを設定する
Ubuntuのコマンドラインからapt パッケージを更新します

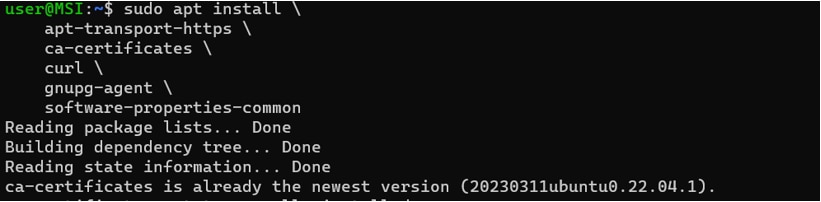
必要なパッケージをインストールします。
DockerのGPGキーを保存するためのディレクトリを作成します。
Dockerの公式GPGキーをダウンロードし、ディレクトリに格納します。
ファイルのアクセス許可を変更して、読み取り可能にします。
DockerのAPTリポジトリを /etc/apt/sources.list.d/docker.listファイルに追加します。
aptパッケージをアップデートします。
Dockerをインストールする
docker最新版をインストールします。
NVIDIA Container Toolkit(CUDA)のインストール
リポジトリとGPGキーのセットアップをします。

パッケージをアップデートします。
nvidia-container-toolkitをインストールします。
Dockerデーモンの設定
NVIDIA コンテナー ランタイムを認識するように Docker デーモンを構成します。
デフォルトのランタイムを設定した後、Docker デーモンを再起動してインストールを完了します。
Dockerを使用するためにユーザーをDockerグループに追加する
新しいグループにユーザーを切り替えます。
再度Dockerを再起動します。
ここまででDockerの環境構築が完了です。
動作確認
ここからは構築したDockerの動作確認を行います。
docker-composeファイルの作成
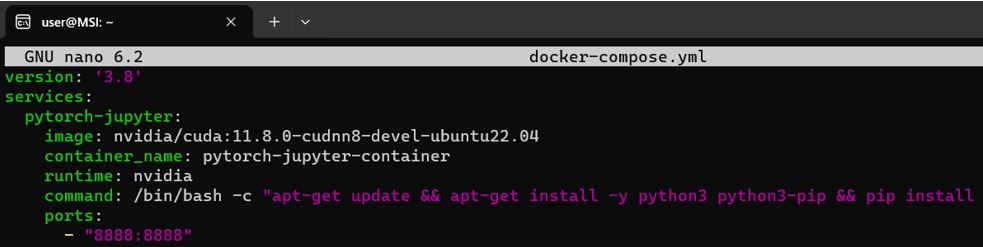
次をインストールするdocker-composeのファイルを作成します。
- cuda11.8
- cuDNN8
- ubuntu22.04
- Pytorch2.1.0
- JupyterLab
docker-compse.ymlファイルを新規作成し、開きます。
開いたdocker-compose.ymlファイルに次のコマンドをコピペします。
編集が完了したら、[Ctrl]+[S]で変更を保存し、[Ctrl]+[X]で編集モードから抜けます。
次のコマンドを実行し、docker-composeをインストールします。
次のコマンドを実行し、dockerイメージのビルドとコンテナの起動を行います。


[Jupyter Server is running at : http://localhost:8888/lab]の表示ができたら、Jupyter Serverの起動完了です。
ブラウザの検索窓に”localhost:8888”を入力すると、Jupyter Labをブラウザで表示できます。
停止するときは、コマンドプロンプトの画面で[Ctrl] + [C]を押すとコンテナが停止します。
もしくは次のコマンドでコンテナを停止します。
コンテナを再起動するときは次のコマンドを実行します。
必要なパッケージをインストール
Jupyter Labのホーム画面で[Python3 ipykernel]を選択し、Notebookを開きます。
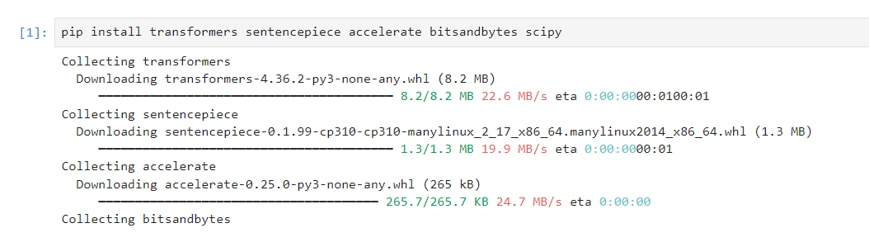
Jupyter Labのコードセルで次のコマンドを実行し、必要なパッケージをインストールします。
次のコマンドを実行し、必要なライブラリをインポートします。

次のコマンドを実行し、"True"が返るとPyTorchからGPUを認識できています。
LLMならGPUクラウド
LLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Windows PCにWSL2、Docker、NVIDIAドライバ、CUDAをインストールして、GPUを使う方法を紹介しました。
GPU環境を構築する際は、各ソフトウェアのバージョンの不整合によりエラーが発生しやすいですので、ご注意ください。



