

【LLM】Ollama+Open WebUIでローカルLLM環境を構築
Ollamaは、様々なLLMモデルをローカルPCで動かすことができる無料のツールです。
この記事では、OllamaとOpen WebUIを使用して、ChatGPTのようなインターフェースでテキストを生成する方法を紹介します。
目次[非表示]
Ollama・Open WebUIとは
Ollamaは、LLMモデルをローカルPCで動かすことができる無料のツールです。
MetaのLlama3やGoogleのGemmaなど様々なLLMモデルをOllamaにダウンロードしてローカル環境で利用できます。
Open WebUIは、Ollama用のWebインターフェースです。
Ollama単体ではコマンドラインでプロンプトを入力することになりますが、Ollama+Open WebUIを使用することで、ChatGPTのようなインターフェースでテキスト生成が可能です。
ローカルPC(Windows)を使用する場合
ローカルPC(Windows)の実行環境は以下のとおりです。
ハードウェア
- GPU:NVIDIA A4000
- GPUメモリ(VRAM):16GB
ソフトウェア
- Windows OS
- WSL2+Ubuntu
- NVIDIAドライバ
- CUDA
- Docker
詳しくは以下の記事で解説しています。
クラウド環境(GPUSOROBAN)を使用する場合
GPUSOROBANはメガクラウドの50%以上安いGPUクラウドサービスです。
手元のPCにGPUを搭載していなくても、インターネット経由でGPUを搭載したインスタンスを利用できます。
GPUSOROBANの使い方は以下の記事で解説しています。
GPUSOROBANの実行環境は以下のとおりです。
インスタンスタイプ
- s16-1-a-standard-ubs22-o
ハードウェア
- GPU:NVIDIA A4000
- GPUメモリ(VRAM):16GB
ソフトウェア
- Ubuntu OS
- NVIDIAドライバ
- CUDA
- Docker
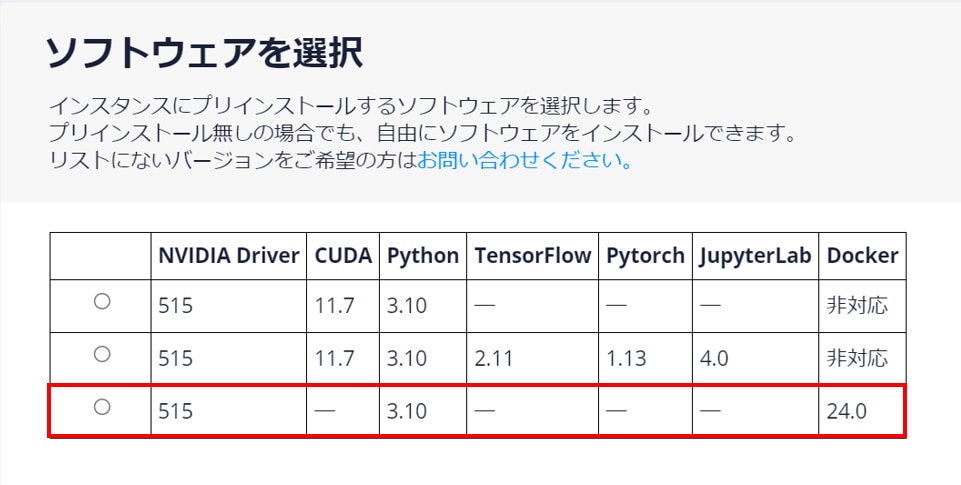
GPUSOROBANの場合、ソフトウェアがプリインストールされているので、環境構築にかかる時間を削減できます
※インスタンスの作成時にDockerがプリインストールされているインスタンスを選択してください。
※インスタンスに接続する際は、7860番にポートフォワードしてください。
ポートフォワードの方法は以下の記事で解説しています。
環境構築
ローカルPCもしくはGPUSOROBANにおいてDockerの構築が完了したら、OllamaおよびOpen WebUIの環境を構築します。
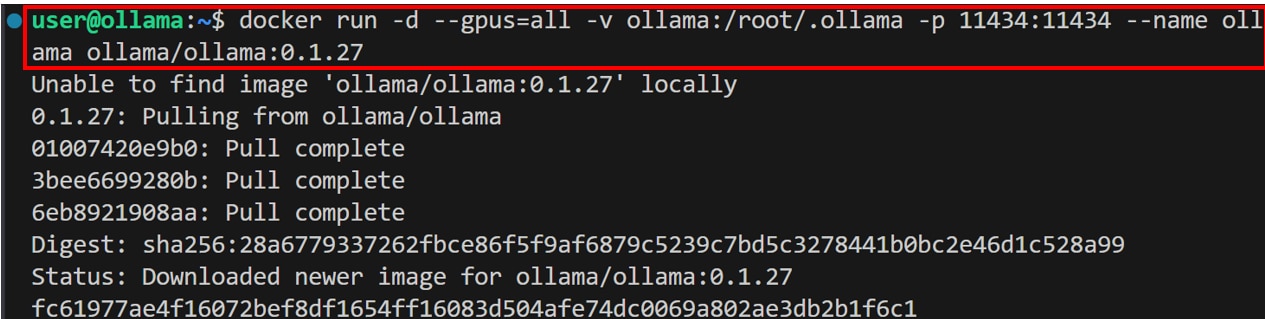
Ollamaコンテナの起動
Ubuntuのターミナルで次のコマンドを実行し、ollamaのdockerコンテナを起動します。
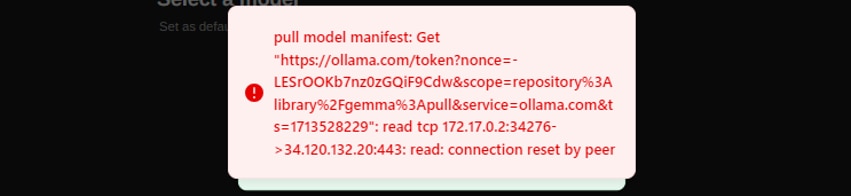
Ollamaの最新のバージョンではモデルをpullするときに以下のエラーが発生するため、Ollamaのバージョンを0.1.27に指定しています。
Open WebUIコンテナの起動
Ubuntuのターミナルで次のコマンドを実行し、Open WebUIのdockerコンテナを起動します。
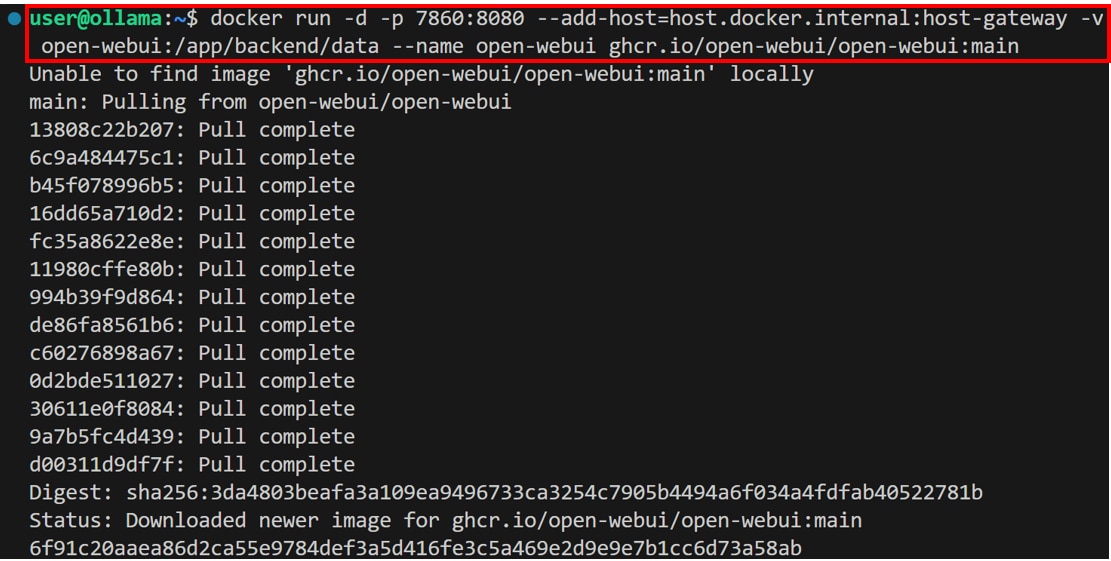
コマンドの実行が完了したら、ブラウザの検索窓にlocalhost:7860を入力し、Enterを押すとOpen WebUIの画面が表示されます。
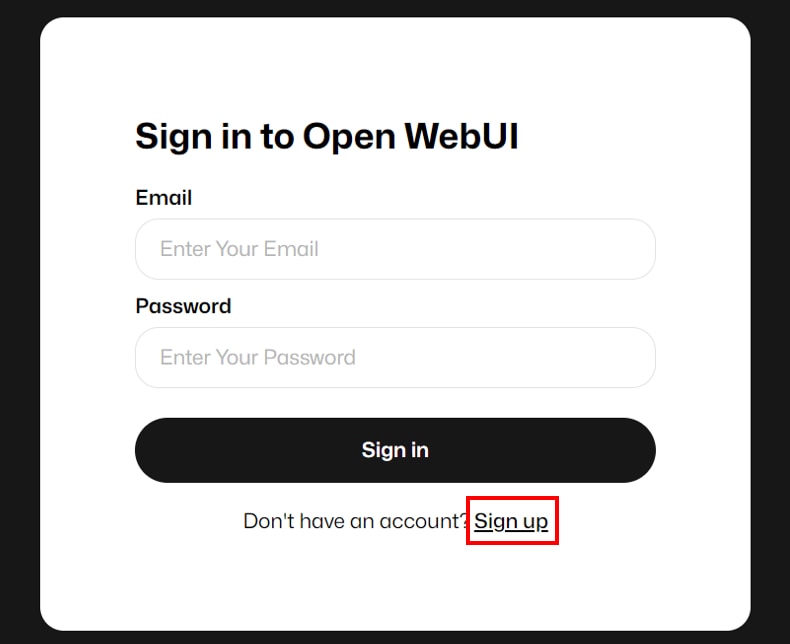
Open WebUIにログイン
サインインの画面が表示されますので、Open WebUIのアカウント未登録の場合は[Sign up]をクリックして、アカウント登録後にログインしてください。
既にアカウント登録済みの場合は、認証情報を入力し、[Sign in]をクリックしてログインできます。
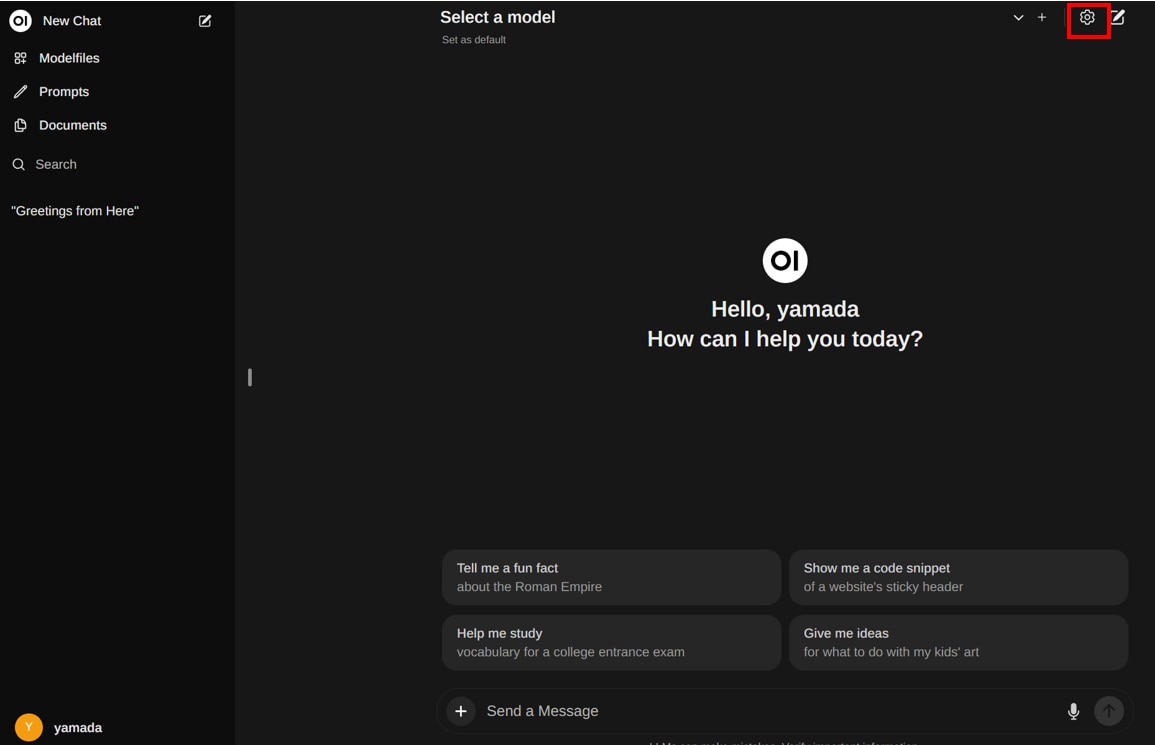
LLMモデルの設定
ログインが完了したら、右上の[歯車]アイコンをクリックします。
サイドバーの[Models]を選択し、[Pull a model from Ollama.com]にダウンロードする”モデル名”を入力し、[ダウンロード]アイコンをクリックします。
この記事ではモデル名を”gemma:7b”と入力しています。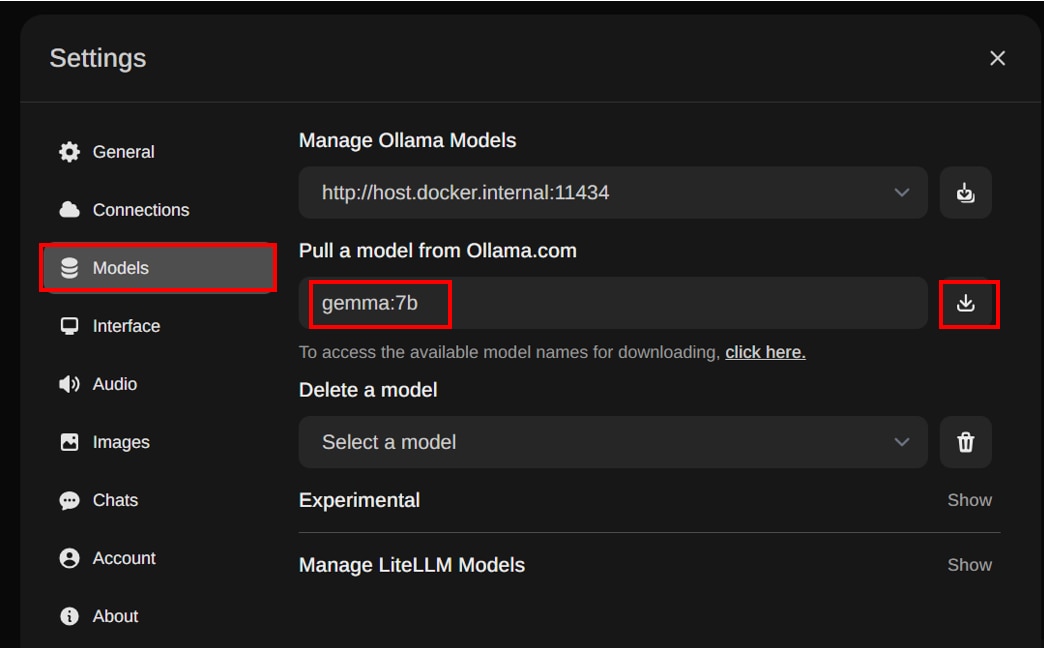
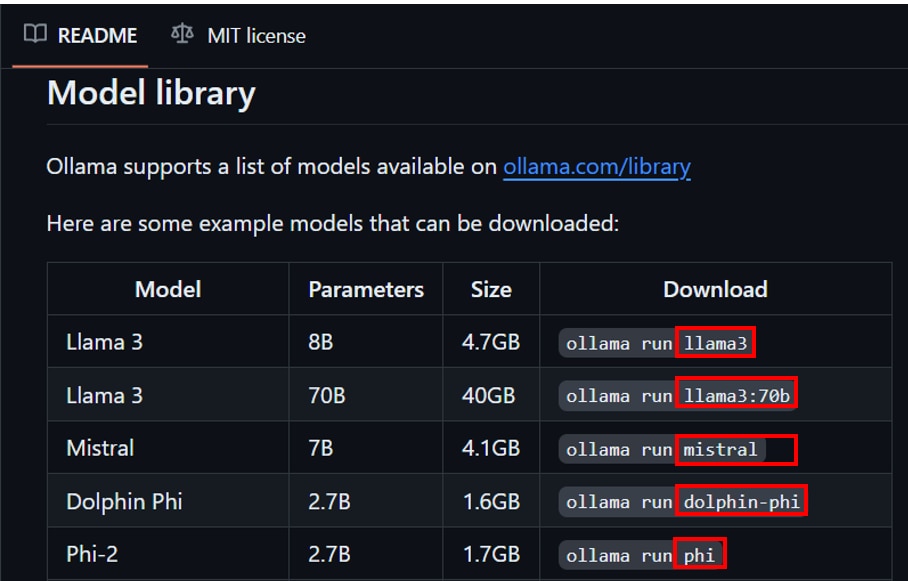
他のモデル名はGithubから参照できます。
[Download]列のollama runnの右側に表示されているものが入力するモデル名になります。
入力するモデル名の例
- llama3
- llama3:70b
- mistral
- dolphin-phi
- phi
テキスト生成
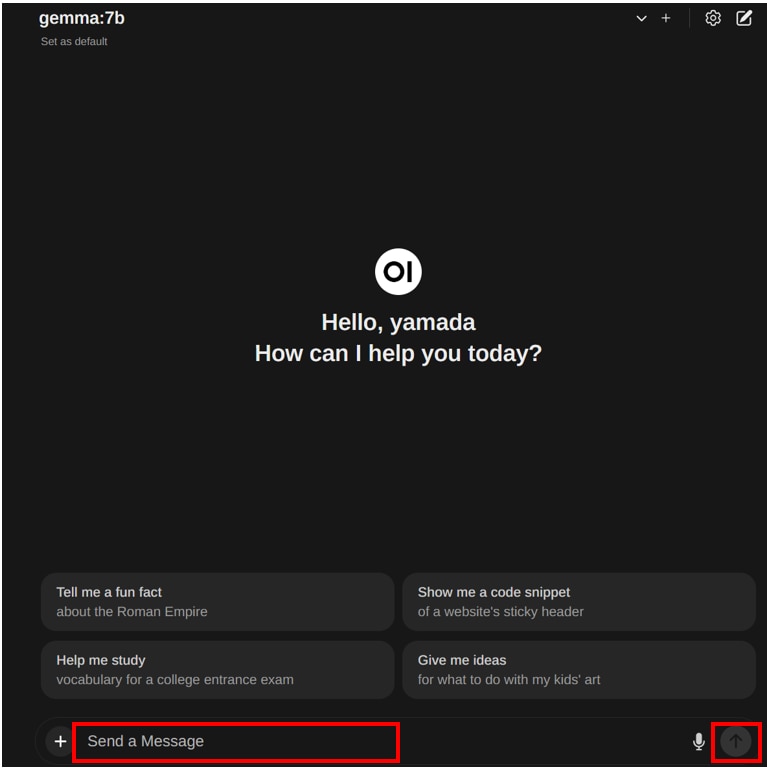
モデルのダウンロードが完了したら画面上の[Select a model]をクリックし、ダウンロードしたモデルを選択します。
この記事ではgemma:7bを選択しています。

画面下の[Send a Message]に”プロンプト”を入力し、[上矢印]ボタンを押すと、テキストが生成されます。
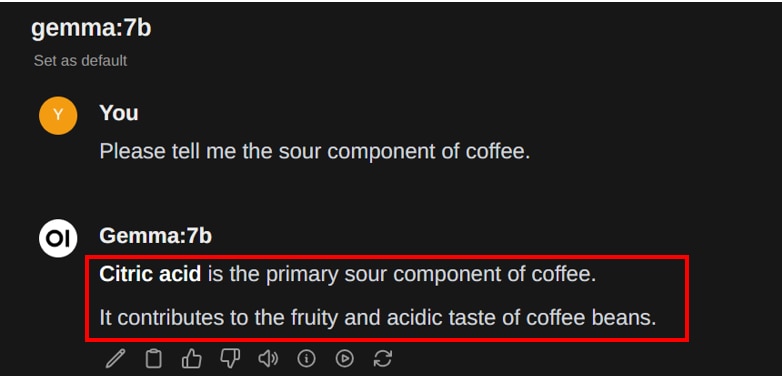
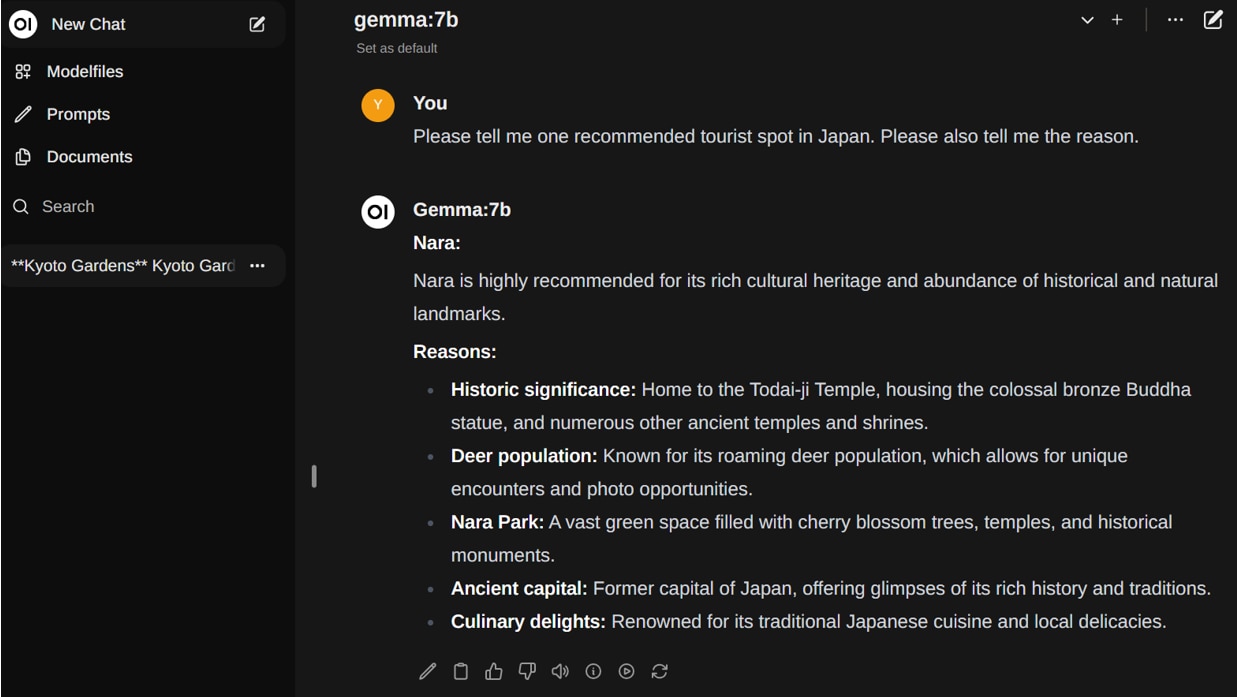
プロンプト1
生成結果
プロンプト2
生成結果
プロンプト3
生成結果
※Gemmaは日本語の学習率が低いため、英語もしくは不完全な日本語でテキストが生成されています。
LLMならGPUクラウド
LLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Ollamaを使用して、ローカル環境でLLMモデルを実行する方法を紹介しました。
OllamaとOpen WebUIを併せて使用することで、ChatGPTのようなインターフェースでテキスト生成できます。



