

【LLM】Google Gemmaとは?使い方・性能・商用利用について解説
Gemmaは、Googleが公開した軽量かつ高性能なLLMで、商用利用可能なオープンモデルです。
この記事では、Gemmaの使い方から性能・安全性・商用利用まで紹介しています。
目次[非表示]
- 1.Gemmaとは
- 2.Gemmaの性能
- 3.オープンモデル・商用利用
- 4.安全性・ローカルで使える
- 5.モデルの種類
- 6.Gemmaのモデル申請
- 7.Gemmaを使ったテキスト生成(推論)
- 8.Jupyter Labを起動
- 9.ライブラリのインストール
- 10.モデルの設定
- 11.生成タスク1
- 12.生成タスク2
- 13.生成タスク3
- 14.LLMならGPUクラウド
- 15.まとめ
Gemmaとは
Gemmaは、Googleが公開したGeminiと同じ技術を活用した軽量なLLMモデルで、ローカルPCの環境でも動かすことができます。
Gemmaの性能は、MetaのLlama2など同規模のモデルを上回ると言われています。学習データから特定の個人情報や機密データを除外しており、安全性の高さも誇ります。
またGemmaはオープンモデルとして公開されており、利用規約に同意をすれば商用利用が可能です。
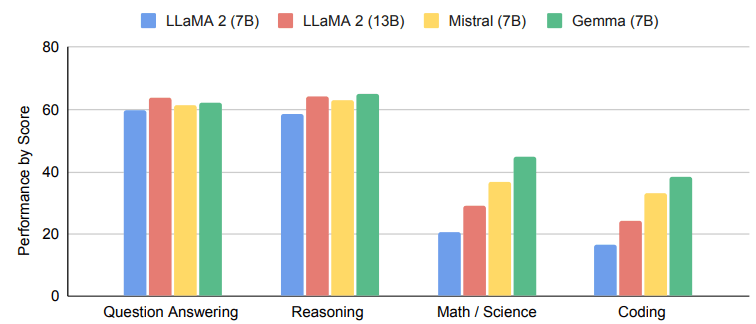
Gemmaの性能
Googleのレポートによると、Gemma(7B)が他のモデルと比較して、質疑応答、推論、数学・科学、コーディングの分野において優れたベンチマークを記録しています。
比較したLlama2のパラメータサイズが13Bに対して、Gemmaのパラメータサイズは7Bであることから、Gemmaは軽量で性能が高いことがわかります。
オープンモデル・商用利用
Googleは、Gemmaは完全なオープンソースとしてではなく、オープンモデルとして公開しています。Googleの利用規約に同意をすれば商用利用が可能です。
オープンモデルでは、モデルの重みと事前訓練済みパラメータを利用できますが、実際のソースコードや訓練データにはアクセスできないと言われています。
またGoogleが掲げる「安全で責任ある開発」を保証するために、「利用規約」と「使用禁止ポリシー」の中で細かく禁止項目を設けています。性的、違法、詐欺的、暴力的、憎悪を助長するコンテンツ、なりすましなど、生成AIで悪用が懸念される使い方を禁止しています。
安全性・ローカルで使える
Gemmaは、安全性を重視して設計されており、データセットから特定の個人情報や機密事項などセンシティブなデータを自動的にフィルタリングする技術があります。
Gemmaの事前訓練モデルを安全かつ信頼できるものにするために、広範なファインチューニングと人間のフィードバックによる強化学習(RLHF)などを利用しています。
GemmaはローカルPCでも使用することができ、入力するデータを外部に学習されるリスクもありません。
モデルの種類
Gemmaのモデルには、20億パラメータの「Gemma 2B」と70億パラメータの「Gemma 7B」があります。
それぞれに事前学習済みのbase modelと人間の指示に基づいた回答をするためのinstruction modelが用意されています。
パラメータサイズが大きいほどGPUメモリとストレージの容量が必要になります。
model_id |
パラメータサイズ |
タイプ |
GPUメモリ(VRAM)使用量 |
ストレージ使用量 |
推論に使用したGPU |
google/gemma-2b |
20億 |
base model |
5.2GB |
4.9GB |
NVIDIA A4000 16GB x1 |
google/gemma-2b-it |
20億 |
instruct
model
|
5.2GB |
4.9GB |
NVIDIA A4000 16GB x1 |
google/gemma-7b |
70億 |
base model |
17GB |
16.8GB |
NVIDIA A100 80GB x 1 |
google/gemma-7b-it |
70億 |
instruct
model
|
17GB |
17GB |
NVIDIA A100 80GB x 1 |
Gemmaのモデル申請
Gemmaのモデルを使うためには利用申請が必要になります。
Gemmaの利用申請の方法は、以下の記事で詳しく解説しています。
Gemmaを使ったテキスト生成(推論)
この記事では、Gemmaを使ったテキスト生成(推論)を行います。
実行環境はGPUクラウドサービス(GPUSOROBAN)を使用しました。
- インスタンス名:t80-1-a-standard-ubs22-i
- GPU:NVIDIA A100 80GB x 1
- OS :Ubuntu 22.04
- CUDA:11.7
- Jupyter Labプリインストール
GPUSOROBANはメガクラウドの50%以上安いGPUクラウドサービスです。 GPUSOROBANの使い方は以下の記事で解説しています。
Winodws環境でGemmaを使用する方法は、以下の記事で解説しています。
Gemmaのファインチューニングについて、以下の記事で詳しく解説しています。
Jupyter Labを起動
GPUSOROBANのインスタンスに接続したら、次のコマンドを実行し、Jupyter Labを起動します。
![]()
ブラウザの検索窓に"localhost:8888"を入力すると、Jupyter Labをブラウザで表示できます。
Jupyter Labのホーム画面で[Python3 torch113_py310]を選択し、Notebookを開きます。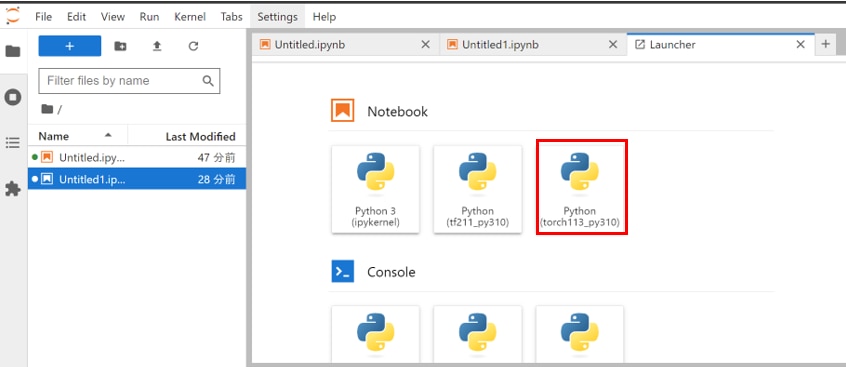
Jupyter Labの詳しい使い方は以下の記事で解説しています。
プリインストールされたJupyter Labを使用する場合
Jupyter Labを新しくインストールして使う場合
ライブラリのインストール
JupyterLabのNotebookのコードセルで次のコマンドを実行し、必要なパッケージをインストールします。
上記のパッケージのインストールが完了したら、Flash attentionをインストールします。Flash attentionは、Transformerの処理を効率化して推論を高速化します。
必要なライブラリをインポートします。
モデルの設定
HuggingFaceで利用申請したGemmaのモデルを読み込みます。
この段階でモデルがGPUメモリにロードされますので、しばらく時間がかかります。
この記事では、モデルのパラメータをロードする数値表現をbfloat16に指定します。
HuggingFaceにアクセスするためのトークンを設定します。
HuggignFaceでのアクセストークンの発行方法は以下の記事で解説しています。
トークナイザーを読み込みます。
モデルを読み込みます。
初回はモデルをダウンロードするため時間がかかりますが、2回目以降はモデルの読み込みだけになりますので、時間はかかりません。
この記事ではgoogle/gemma-7b-itのパラメータ7bのチャットモデルを使用していますが、他のモデルを使いたい場合は表を参考に適宜model_idを変更してください。
model_id |
GPUメモリ(VRAM)使用量 |
ストレージ使用 |
使用したGPU |
google/gemma-2b |
5.2GB |
4.9GB |
NVIDIA A4000 16GB x1 |
google/gemma-2b-it |
5.2GB |
4.9GB |
NVIDIA A4000 16GB x1 |
google/gemma-7b |
17GB |
16.8GB |
NVIDIA A100 80GB x 1 |
google/gemma-7b-it |
17GB |
17GB |
NVIDIA A100 80GB x 1 |
生成タスク1
プロンプトの実行
富士山について質問をしてみます。
生成結果
富士山に関するそれらしい回答が得られました。
日本語訳
生成タスク2
プロンプトの実行
東京の観光スポットについて質問をしてみます。
生成結果
東京の観光スポットに関するそれらしい回答が得られました。
日本語翻訳
生成タスク3
プロンプトの実行
日本語を使って、おすすめの日本食について質問してみます。
生成結果
日本語で回答が得られましたが、不完全な内容になっています。
LLMならGPUクラウド
LLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Gemmaの使い方や性能・安全性・商用利用について紹介しました。
Gemmaはローカル環境で使えるほど軽量かつ高性能なオープンモデルです。
ローカル環境でGemmaを使用する方法は、以下の記事で解説しています。
Gemmaのファインチューニングについては、以下の記事で解説しています。



