

【LLM】Google Gemmaのモデル利用申請
Gemmaは、Googleが公開した軽量かつ高性能なLLMモデルで、ローカルPCの環境で動かすことができます。
この記事では、Gemmaのモデルを使用するための利用申請について解説しています。
Gemmaとは
Gemmaは、Googleが公開したGeminiと同じ技術を活用した軽量なLLMモデルで、ローカルPCの環境でも動かすことができます。
主要なベンチマークにおいて、Gemmaは MetaのLlama2など同規模のモデルを上回ると言われています。学習データから特定の個人情報や機密データを除外しており、安全性の高さも誇ります。
またGemmaはオープンモデルとして公開されており、利用規約に同意をすれば商用利用が可能です。
Gemmaのモデルを使用するにあたって、Googleへの利用申請が必要になります。
Gemmaの使い方については、以下の記事で詳しく解説しています。
モデルの種類
20億パラメータの「Gemma 2B」と70億パラメータの「Gemma 7B」がリリースされており、それぞれ事前学習済みのbase modelと人間の指示に基づいた回答をするためのinstruction modelが用意されています。
パラメータサイズが大きいほどGPUメモリとストレージの容量が必要になります。
model_id |
パラメータサイズ |
タイプ |
GPUメモリ(VRAM)使用量 |
ストレージ使用量 |
google/gemma-2b |
20億 |
base model |
5.2GB |
4.9GB |
google/gemma-2b-it |
20億 |
instruct |
5.2GB |
4.9GB |
google/gemma-7b |
70億 |
base model |
17GB |
16.8GB |
google/gemma-7b-it |
70億 |
instruct |
17GB |
17GB |
Googleへのモデル利用申請
Gemmaのモデルを使用するにあたり、Googleへの申請方法を解説します。
この記事では、モデル「google/gemma-7b」のページにアクセスし、利用申請を進めます。Gemmaのどれか1つのモデルの利用申請が完了すると、他のGemmaのモデルの利用申請も自動的に完了します。
HuggingFaceのアカウントをお持ちの方は、[Log in]を選択します。
HuggingFaceの新規アカウントを作成する場合は[Sign UP]を選択し、必要情報を入力します。
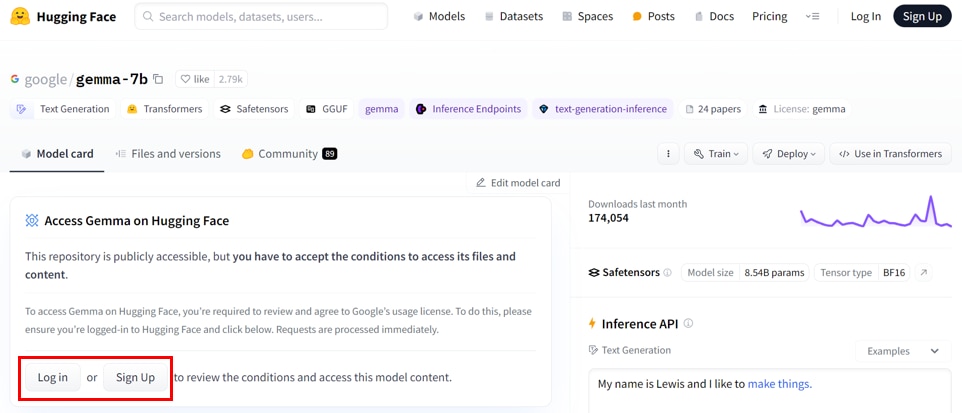
アカウント作成画面で、[Email Address]と[Password]を入力し、[Next]をクリックします。
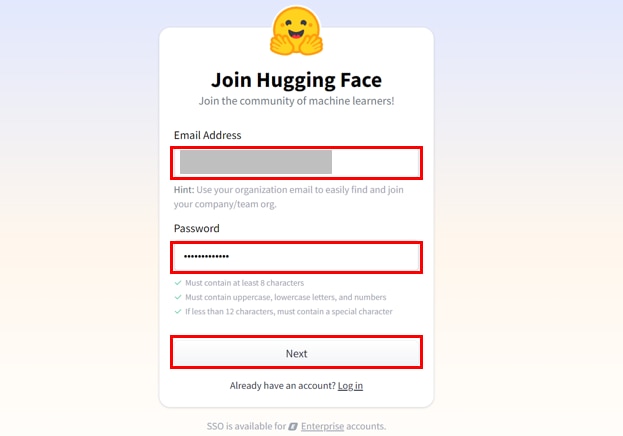
プロフィールを入力し、利用規約に同意した上で、[チェックボックス]にチェックをいれて、[Create Account]をクリックします。
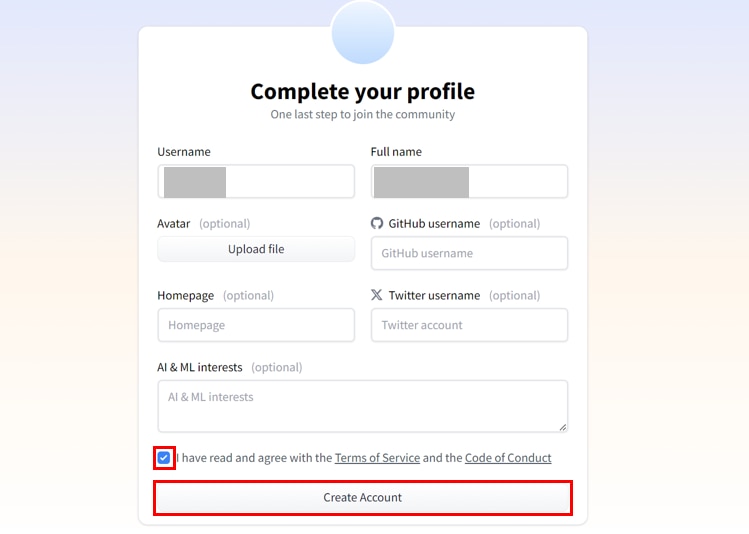
登録したメールアドレスに認証メールが届きますので、リンクをクリックします。
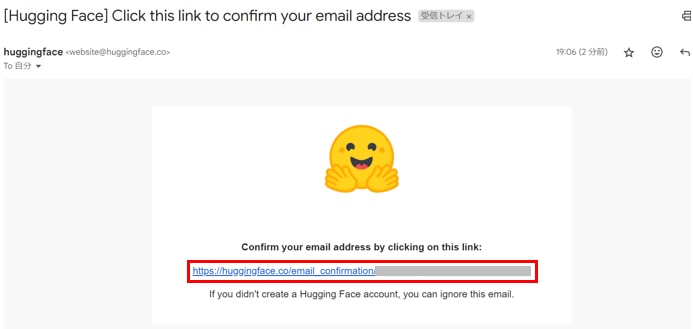
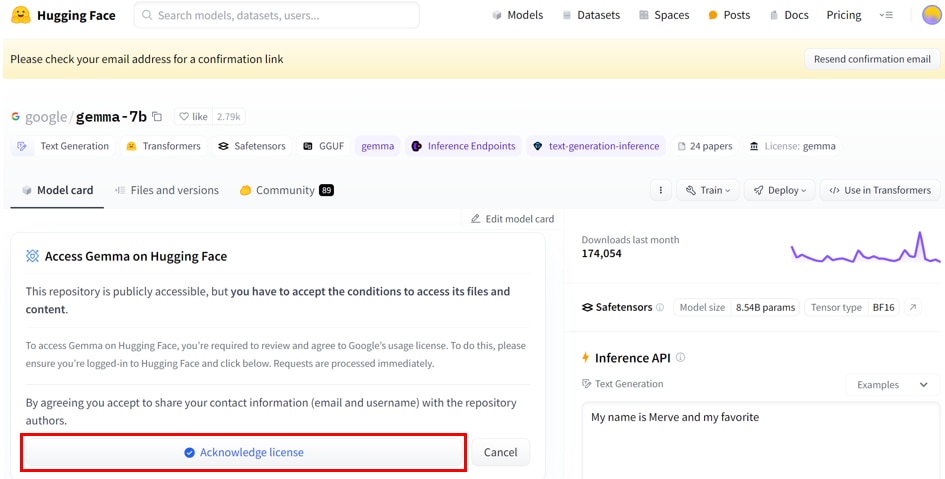
Gemmaのモデルページで、リポジトリの提供者に連絡先情報を共有することに同意したうえで、[Acknowledge license]ボタンをクリックします。
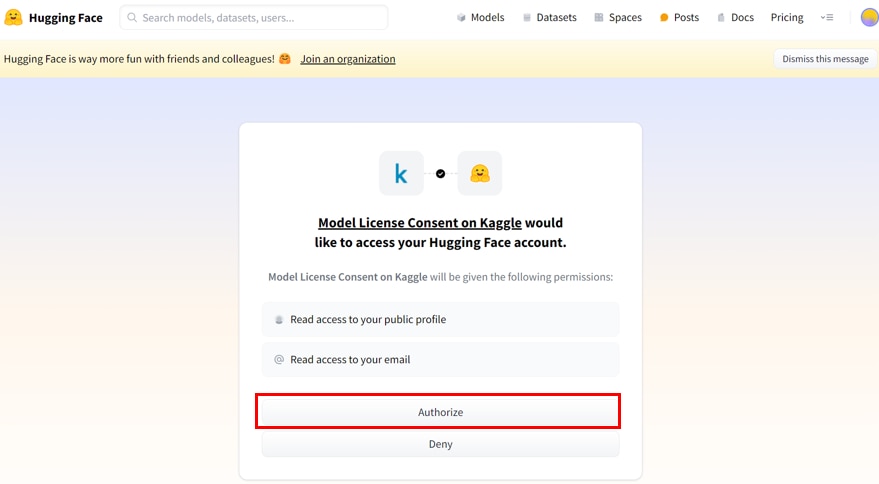
KaggleからHuggingFaceのアカウントの連絡先情報にアクセスすることを許可したうえで、[Authorize]ボタンをクリックします。
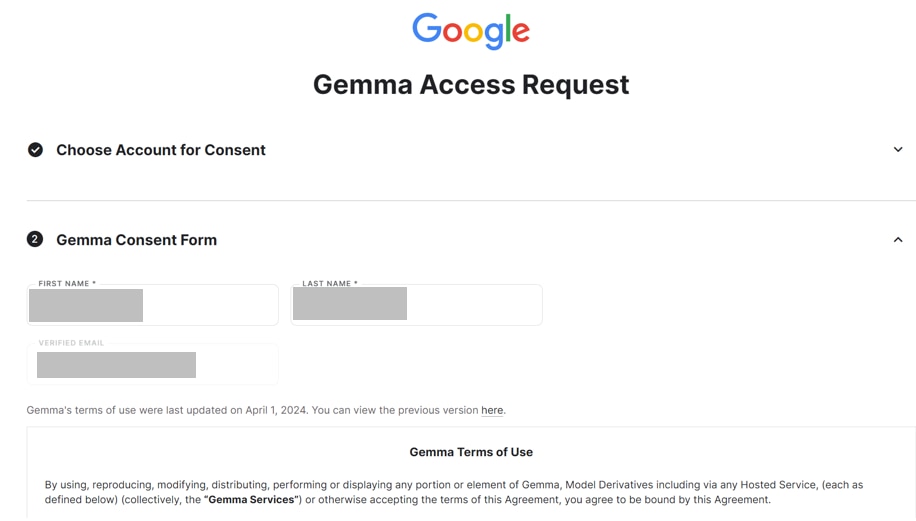
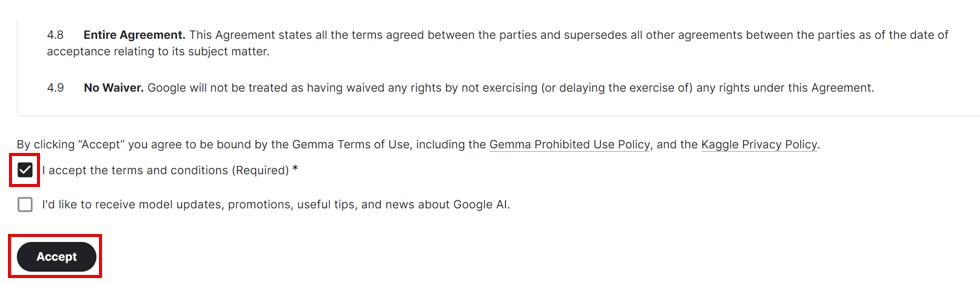
Gemmaのモデルへのアクセス申請において、[I accept the terms and conditions(Reauired)*]にチェックをいれて、[Accept]ボタンをクリックします。
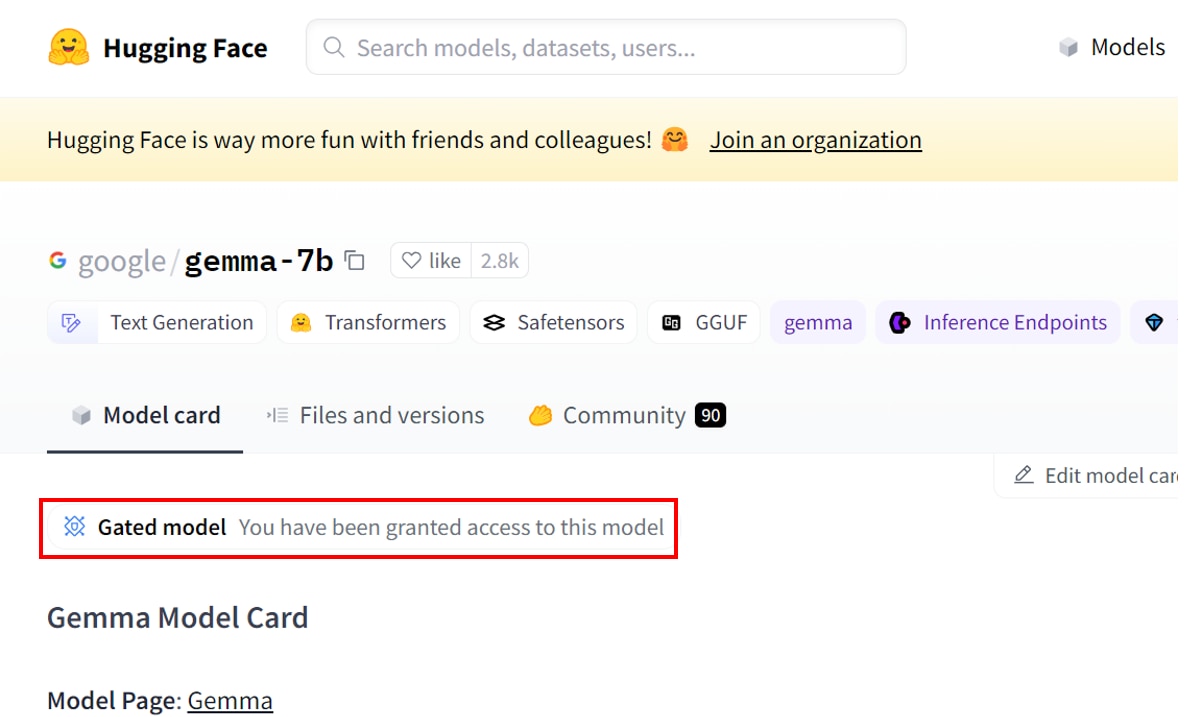
Gemmaのモデルページに、[Gated model You have been granted access to this model]と表示されたら、利用申請が完了です。
生成AI・LLMならGPUクラウド
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Gemmaのモデルを使用するための利用申請について解説しました。
Gemmaの使い方については以下の記事で詳しく解説していますので、併せてご覧ください。



