

【Llamaの日本語LLM】Swallowの使い方・性能・商用利用 | 7B・13B・70B
Swallowは、東京工業大学と産総研の研究チームによって開発されたLlama2ベースの日本語LLMです。
この記事では、Swallowの使い方・性能・商用利用について紹介しています。
目次[非表示]
- 1.Swallow とは
- 2.Swallowモデルの種類
- 3.Swallowの日本語性能
- 4.Swallowの商用利用・ライセンス
- 5.Swallowの使い方
- 6.Jupyter Labを起動
- 7.ライブラリのインストール
- 8.モデルの設定
- 9.モデルの量子化
- 10.プロンプトの実行1
- 11.プロンプトの実行2
- 12.プロンプトの実行3
- 13.LLMならGPUクラウド
- 14.まとめ
Swallow とは
Swallowは、東工大と産総研の研究チームによって開発された日本語LLMです。
世界的に支持されているMeta社のLlama2のモデルをベースに、日本語能力を強化するために新たに日本語の語彙やデータを組み込み、継続事前学習を行っています。性能評価では、2023年12月時点で最高水準の日本語処理能力を示しています。
Swallowは、日本語の文法や表現のニュアンスを理解し、高度な言語処理タスクに対処することができるようになっています。
ベースモデルのLlama2については、以下の記事で詳しく解説しています。
Swallowモデルの種類
Swallowモデルには、3つのパラメータサイズ(7B、13B、70B)があり、それぞれに事前学習モデル(base)と、人間の指示に基づいた回答をするためのモデル(instruct)が用意されています。
モデルは、Hugging Faceからモデルをダウンロードできます。
model_id |
パラメータサイズ |
タイプ |
GPUメモリ(VRAM)使用量 |
ストレージ使用 |
使用したGPU |
tokyotech-llm/Swallow-7b-hf |
70億 |
base model |
14.8GB |
14GB |
NVIDIA A100 40GB x |
tokyotech-llm/Swallow-7b-instruct-hf |
70億 |
instruct model |
14.8GB |
14GB |
NVIDIA A100 40GB x 1 |
tokyotech-llm/Swallow-13b-hf |
130億 |
base model |
27.4GB |
26GB |
NVIDIA A100 40GB x 1 |
tokyotech-llm/Swallow-13b-instruct-hf |
130億 |
instruct
model
|
27.4GB |
26GB |
NVIDIA A100 40GB x 1 |
tokyotech-llm/Swallow-70b-hf |
700億 |
base model |
35.4GB (※4bit量子化あり) |
130GB |
NVIDIA A100 80GB x 1 |
tokyotech-llm/Swallow-70b-instruct-hf |
700億 |
instruct model |
35.4GB
(※4bit量子化あり)
|
132GB |
NVIDIA A100 80GB x 1 |
※Swallow 70bをNVIDIA A100 80GB x1枚で動かす場合は、GPUメモリ(VRAM)が不足しますので、精度を落としてモデルを軽量化する量子化を適用しています。
SwallowのベースモデルのLlama2の情報になりますが、HugginFaceの記事では量子化を行わない場合、700億パラメータのLlama-2-70bでは総計140GBのGPUメモリが必要とされています。
またGithubでは、8つのマルチGPU構成(=MP 8)を使用することを推奨されています。
Swallowの日本語性能
Meta社が開発したLlama 2は世界的に支持されるLLMモデルですが、日本語の処理には弱点がありました。
東工大らによる研究チームがLlama 2モデルを日本語と英語のデータで継続事前学習した結果、日本語のベンチマークデータにおいて、全てのモデルが元の性能を上回り、継続事前学習の効果が示されました。
また語彙拡張を行うことで日本語テキストのトークン長を50%以上削減し、学習・推論効率を改善しています。大規模な日本語ウェブコーパスの開発も行われ、品質の高い言語データを取り入れています。
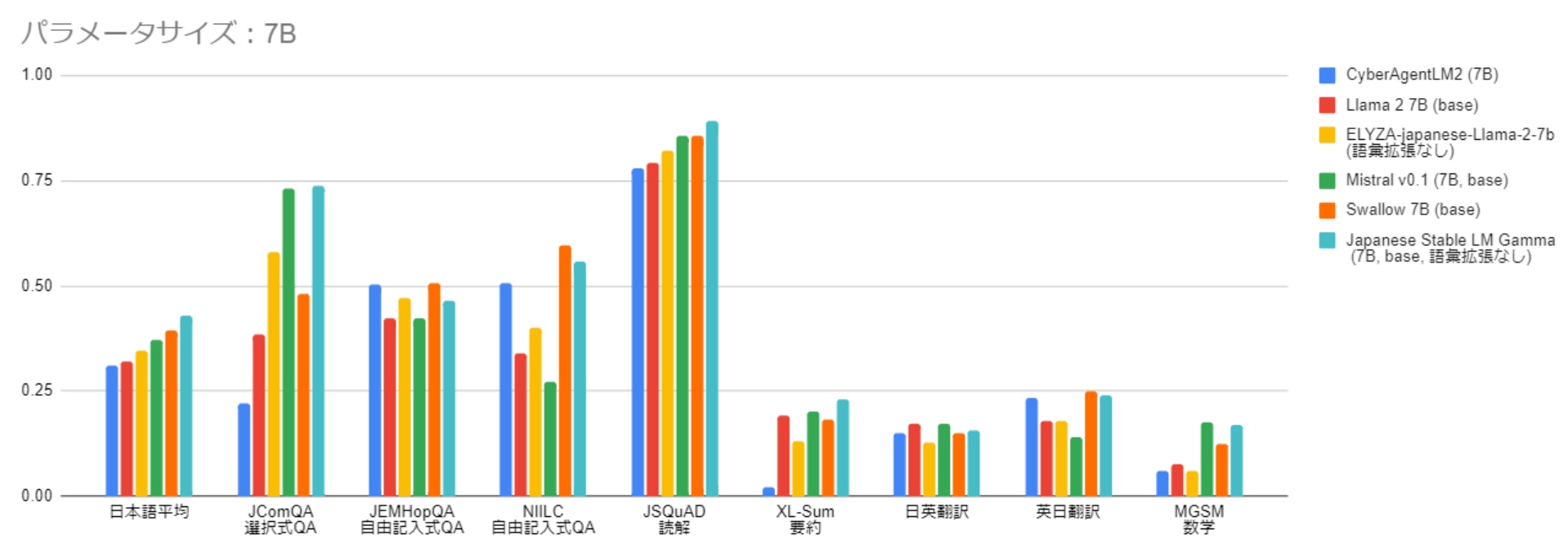
研究チームが実施した日本語の評価ベンチマークでの比較実験結果を以下のグラフに示します。
ざっくり比較する場合は、一番左の項目の[日本語平均]をご覧ください。この項目は各ベンチマークの平均値になります。
7Bのパラメータサイズにおいて、Swallow 7Bは Japanese Stable SM Gamma 7Bを除く他のモデルを上回る性能を示しています。
Swallow 7BはJapanese Stable SM Gamma 7Bをを下回りましたが、これはベースとなるMistral 7Bの性能が高いためです。
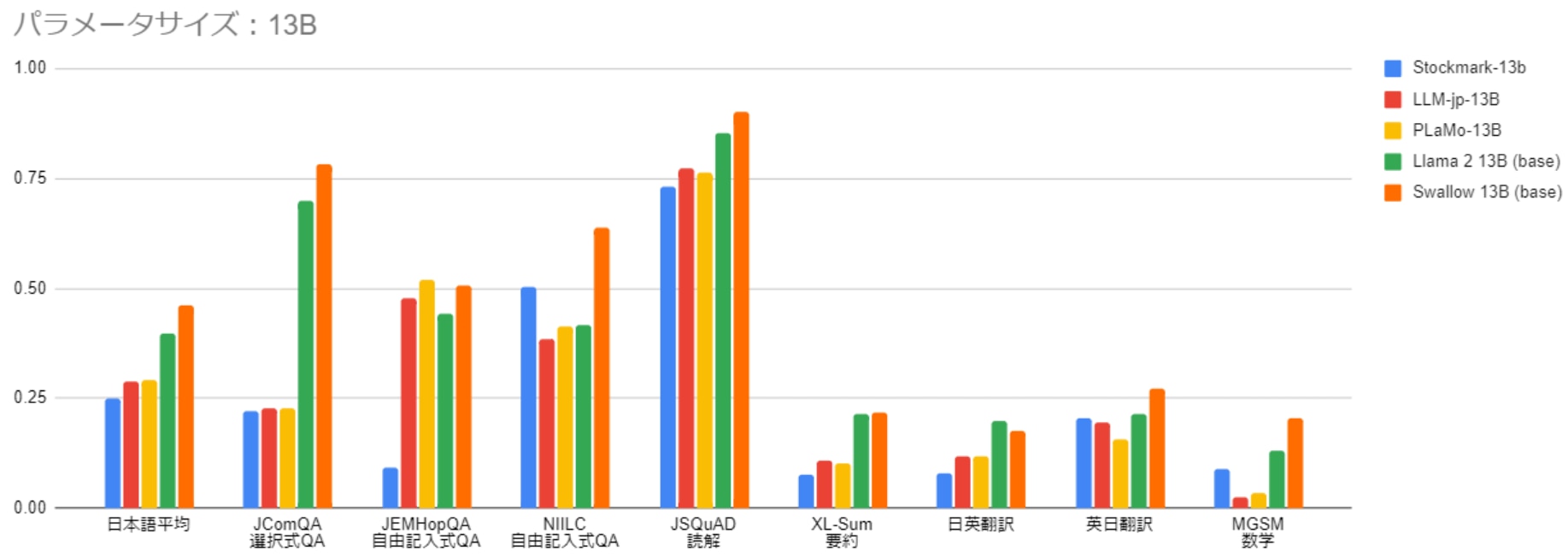
13Bや70Bのパラメータサイズの比較では、Swallowが最高性能を達成しました。
特に13Bのモデルにおいてフルスクラッチで学習した他のモデルとの性能差が顕著に表れています
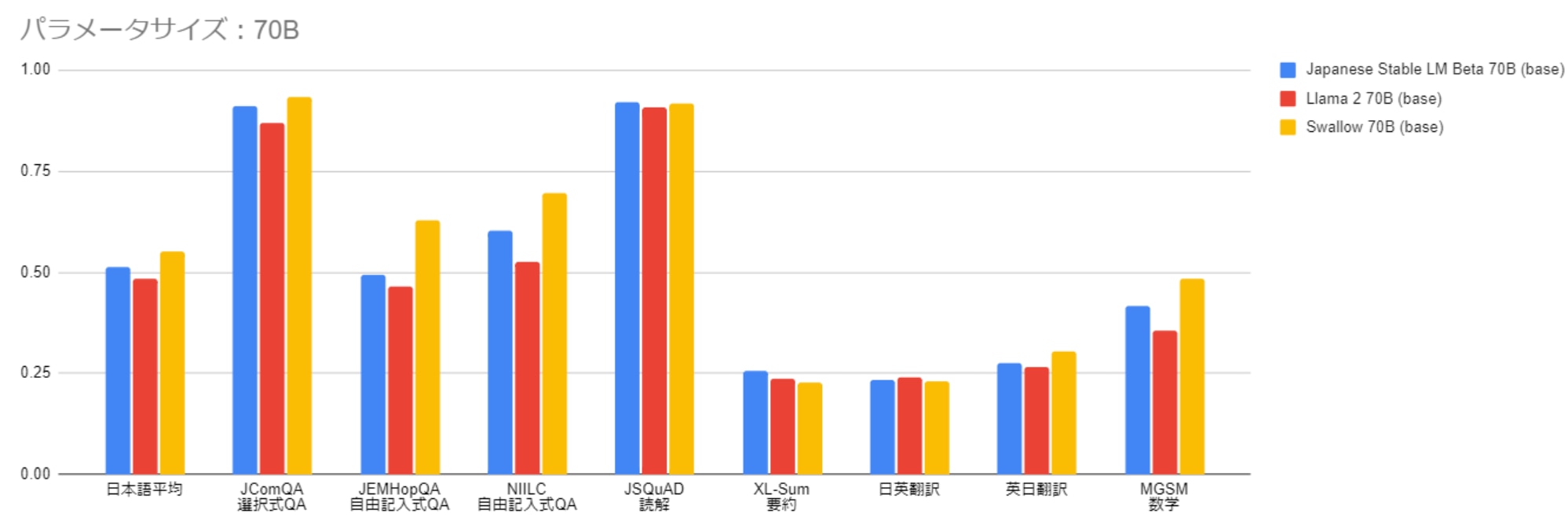
参考:https://tokyotech-llm.github.io/swallow-llama
Swallowの商用利用・ライセンス
SwallowのライセンスはLlama 2のLLAMA 2 Community Licenseを継承しています。
このライセンスに従う限りにおいては、研究および商業目的での利用が可能です。
LLAMA2 Community Licenseの詳細は以下のページをご覧ください。
Swallowの使い方
ここからSwallowのモデルを使った日本語のテキスト生成(推論)を解説します。
この記事ではGPUクラウドサービス(GPUSOROBAN)の実行環境を使用しました。
- インスタンス名:t80-1-a-exlarge-ubs22-i
- GPU:NVIDIA A100 80GB x 1
- OS :Ubuntu 22.04
- CUDA:11.7
- Jupyter Labプリインストール
GPUSOROBANはメガクラウドの50%以上安いGPUクラウドサービスです。
GPUSOROBANの使い方は以下の記事で解説しています。
Jupyter Labを起動
GPUSOROBANのインスタンスに接続したら、次のコマンドを実行し、Jupyter Labを起動します。

ブラウザの検索窓に"localhost:8888"を入力すると、Jupyter Labをブラウザで表示できます。
Jupyter Labのホーム画面で[Python3 ipykernel]を選択し、Notebookを開きます。
Jupyter Labの詳しい使い方は、以下の記事で解説しています。
プリインストールされたJupyter Labを使用する場合
Jupyter Labを新しくインストールして使う場合
ライブラリのインストール
JupyterLabのNotebookのコードセルで次のコマンドを実行し、PyTorchをインストールします。
次のコマンドを実行し、必要なパッケージをインストールします。
必要なライブラリをインポートします。
モデルの設定
HuggingFaceのtransformersというライブラリを使用してモデルの準備をします。
この記事ではパラメータサイズ13bのinstructモデル(Swallow-13b-instruct-hf)を指定していますが、他のモデルを使いたい場合は表を参考に適宜model_idを変更してください。
model_id |
パラメータサイズ |
タイプ |
GPUメモリ(VRAM)使用量 |
ストレージ使用 |
使用したGPU |
tokyotech-llm/Swallow-7b-hf |
70億 |
base model |
14.8GB |
14GB |
NVIDIA A100 40GB x |
tokyotech-llm/Swallow-7b-instruct-hf |
70億 |
instruct model |
14.8GB |
14GB |
NVIDIA A100 40GB x 1 |
tokyotech-llm/Swallow-13b-hf |
130億 |
base model |
27.4GB |
26GB |
NVIDIA A100 40GB x 1 |
tokyotech-llm/Swallow-13b-instruct-hf |
130億 |
instruct
model
|
27.4GB |
26GB |
NVIDIA A100 40GB x 1 |
tokyotech-llm/Swallow-70b-hf |
700億 |
base model |
35.4GB (※4bit量子化あり) |
130GB |
NVIDIA A100 80GB x 1 |
tokyotech-llm/Swallow-70b-instruct-hf |
700億 |
instruct model |
35.4GB
(※4bit量子化あり) |
132GB |
NVIDIA A100 80GB x 1 |
※Swallow 70bをNVIDIA A100 80GB x1枚で動かす場合は、GPUメモリ(VRAM)が不足しますので、精度を落としてモデルを軽量化する量子化を適用しています。
HuggingFaceにアクセスするためのトークンを設定します。
HuggignFaceでのアクセストークンの発行方法は以下の記事で解説しています。
モデルの量子化
量子化は、モデルのパラメータや活性化関数などを低bitに変換する技術で、精度を落とす代わりにモデルサイズを軽量化することができます。
モデルのパラメータを4bitでロードするように設定し、4bitの計算に使用されるデータ型をBFloat16に設定しています。
※Swallow 70bをNVIDIA A100 80GB x1枚で動かす場合は、GPUメモリ(VRAM)が不足しますので、精度を落としてモデルを軽量化する量子化を実行します。
※Swallow 7b, 13bの場合は、NVIDIA A100 40GB x 1枚でGPUメモリ(VRAM)が足りますので、ここのコマンドはスキップしてください。
モデルを読み込みます。初回はモデルをダウンロードするため時間がかかりますが、2回目以降はモデルの読み込みだけになりますので、時間はかかりません。
※量子化を使用する場合は、#quantization_config=quant_config,のコメントアウトを外して実行してください。
トークナイザーを読み込みます。
プロンプトの基本設定をします。
プロンプトの実行1
富士山の特徴について質問してみます。
プロンプトの実行2
神奈川の観光スポットについて質問してみます。
※途中で文章が終わっていますが、max_new_tokens=128の値を増やすことで出力する文章を長くすることができます。
プロンプトの実行3
北海道のご当地グルメについて質問してみます。
LLMならGPUクラウド
LLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN 高速コンピューティング」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
Swallowは、東工大と産総研の研究チームによって開発されたLlama2ベースの日本語LLMです。
日本語の文法や表現のニュアンスを理解し、高度な言語処理タスクに対処することができるようになっています。
ベースモデルのLlama2の使い方は、以下の記事で解説していますので、あわせてご覧ください。



