

Llama2とは?使い方・日本語性能・商用利用について解説 | 初心者ガイド
この記事では、Llama2について幅広く解説しています。Llama2の性能や安全性、商用利用、日本語対応、様々な環境での使い方などに触れています。
目次[非表示]
- 1.Llama2とは
- 2.Llama2の性能と安全性(ChatGPTとの比較)
- 3.Llama2モデルのバリエーション(7b,13b,70b,Chat)
- 4.Llama2は無料で使えて商用利用も可能
- 5.クローズドなローカル環境で使える軽量LLM
- 6.Llama2の日本語モデル(ELYZA-japanese-Llama-2)
- 7.Llama2を動かすにはGPUが必要
- 8.Llama2を使用するための環境
- 9.Windows + GPUのローカル環境
- 10.Windows + CPUのローカル環境(Llama.cpp、Llama-cpp-python)
- 11.Macのローカル環境(Llama.cpp、Llama-cpp-python)
- 12.GPUクラウドサービスとは
- 13.Google Colaboratory(Colab)の環境
- 14.GPUクラウドサービス(GPUSOROBAN)の環境
- 15.Llama2を追加学習・ファインチューニングする方法
- 16.Text generation web UIの使い方
- 17.ブラウザでLlama2を体験してみる
- 18.Llama2をAPIで使う方法(Replicate API)
- 19.Llama2を推論で動かす
- 19.1.Metaへのモデル利用申請とHuggingFaceの設定
- 19.2.推論環境の準備
- 19.3.ライブラリのインストール
- 19.4.モデルの設定
- 19.5.テキスト生成のタスク
- 19.6.質問応答のタスク
- 19.7.テキスト分類のタスク
- 19.8.テキスト要約のタスク
- 19.9.テキスト抽出のタスク
- 19.10.日本語翻訳のタスク
- 19.11.コード生成のタスク
- 20.LLMならGPUクラウド
- 21.まとめ
Llama2とは
Llama2(Large Language Model Meta AI 2/ラマツー)とは、Facebookを運営するMeta社が開発した言語生成AI(LLM)で、OpenAI社のChatGPTに匹敵するの性能を持っています。
Llama2の特徴としては、軽量モデルで高性能、そして無料で使えるオープンソースであるため、開発者にとって扱いやすいモデルになっています。
Llama2でできることは、以下の通りです。
- 文章生成
- 質問応答
- 分類・要約・抽出
- 翻訳
- 会話
- コード生成

Llama3については、別記事で詳しく解説しています。
Llama2の性能と安全性(ChatGPTとの比較)
有用性の評価
Llama2は最大で700億のパラメータを持っています。この数はGPT-3の1700億パラメータよりも少ないですが、それでも大量のデータを学習して性能を向上させています。
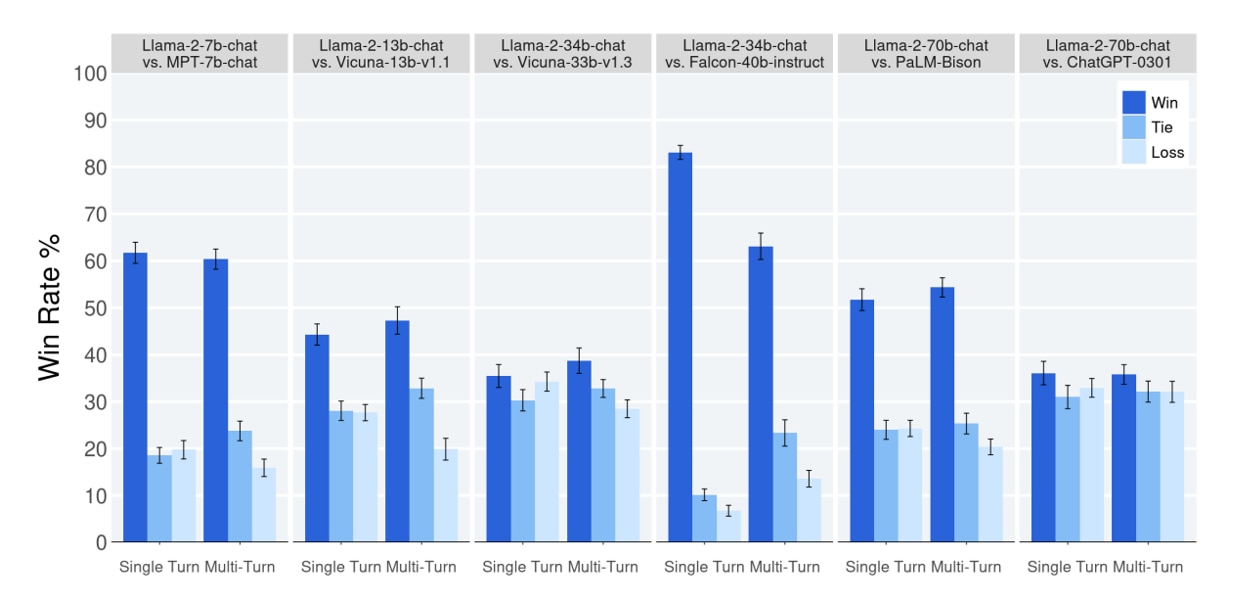
以下のグラフでは、Llama2と他のLLMモデルを4000のプロンプトを使用して評価した結果を示し、この結果は人間による有用性の評価に基づいています。一番右のグラフでは、Llama2とChatGPTを比較していますが、Llama2がわずかにChatGPTを上回る結果となりました。
安全性の評価
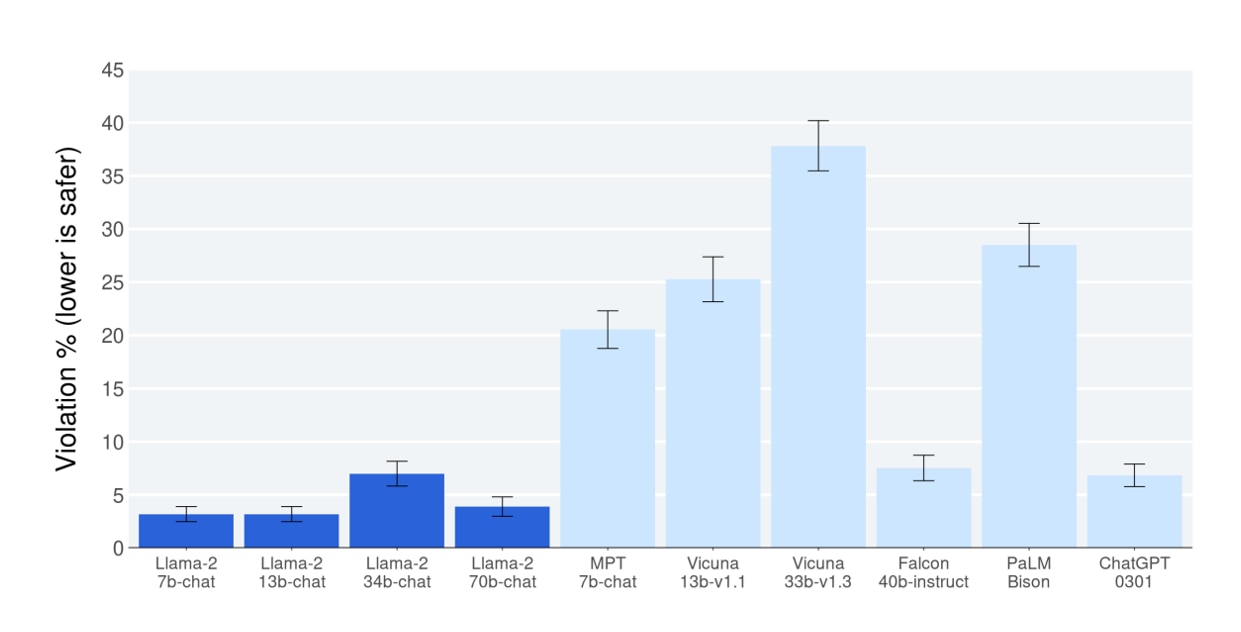
Llama2の安全性をテストするために、約2,000の悪意のあるプロンプトを実行しました。これらのプロンプトは、機密情報を抽出することを意図しています。
テストの結果では、Llama2がChatGPTを上回る安全性を示しています。安全性スケール上の割合が低いほど、モデルはより安全であると考えられます。
Llama2モデルのバリエーション(7b,13b,70b,Chat)
Llama2には、70億、130億、700億の3つの異なるパラメータ数のタイプがあり、パラメータ数が大きいほど高い精度が期待されます。事前学習に使用されたトークンの総数は2兆で、コンテキストの長さは4,000を超えます。
以下が事前学習済みのモデル一覧です。
- Llama-2-7b:70億のパラメータを持つモデル
- Llama-2-13b:130億のパラメータを持つモデル
- Llama-2-70b:700億のパラメータを持つモデル
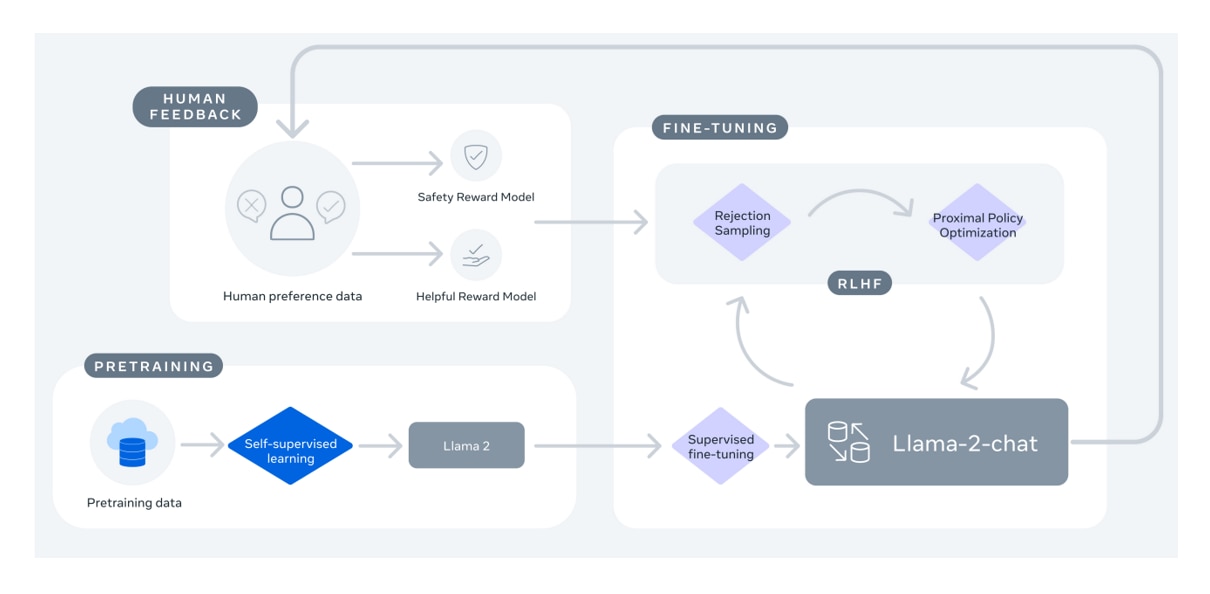
これに加えて、人間のような自然な会話ができるようにファインチューニングされたモデルが存在します。Chatモデルでは、10万回以上の教師あり学習と、100万人以上のフィードバックによる強化学習が行われています。Chatモデルは、ChatGPTのような自然な会話を生成できます。
以下がChatモデルの一覧です。
- Llama-2-7b-chat:70億のパラメータを持つモデル
- Llama-2-13b-chat:130億のパラメータを持つモデル
- Llama-2-70b-chat:700億のパラメータを持つモデル
Llama2は無料で使えて商用利用も可能
Llama2は、OpenAIのGPTやGoogleのPaLMなどがクローズドなLLMが主流となる中で、オープンソースかつ無料で使えるという利点があります。Llama2のコードはGithubでも公開されています。
利用する前にはMeta社への事前申請が必要ですので、ご注意ください。Llama2は研究用途だけでなく、商用利用も可能です。
具体的には、ユーザーはLlama 2とその関連資料を使用、複製、配布、改変するための非独占的なライセンスを得ます。
ただし、Llama 2を第三者に提供する場合は、以下のページにある同意書のコピーを提供しなければなりません。
また月間ユーザー数が7億人を超える場合、追加ライセンスが必要とされています。
具体的なライセンス契約や利用規約は、以下のページに明記されています。
クローズドなローカル環境で使える軽量LLM
Llama2は、OpenAIのGPTモデルと比べて非常に少ないパラメータで構成されているため、ローカル環境での利用ができるほど軽量なモデルです。
ユーザーが用意した環境にダウンロードして使用できるため、使用したデータが外部に学習される心配がなく、個人情報や機密情報の取り扱いにおいても安全に利用できます。
また、Llama2はファインチューニング(追加学習)も可能なので、特定のタスクや目的に合わせてモデルをカスタマイズすることができます。
Llama2の日本語モデル(ELYZA-japanese-Llama-2)
Llama 2のベースモデルは、日本語が事前学習されたトークンが0.1%ほど(20億トークン)しか含まれておらず、そのため日本語には弱い部分があります。
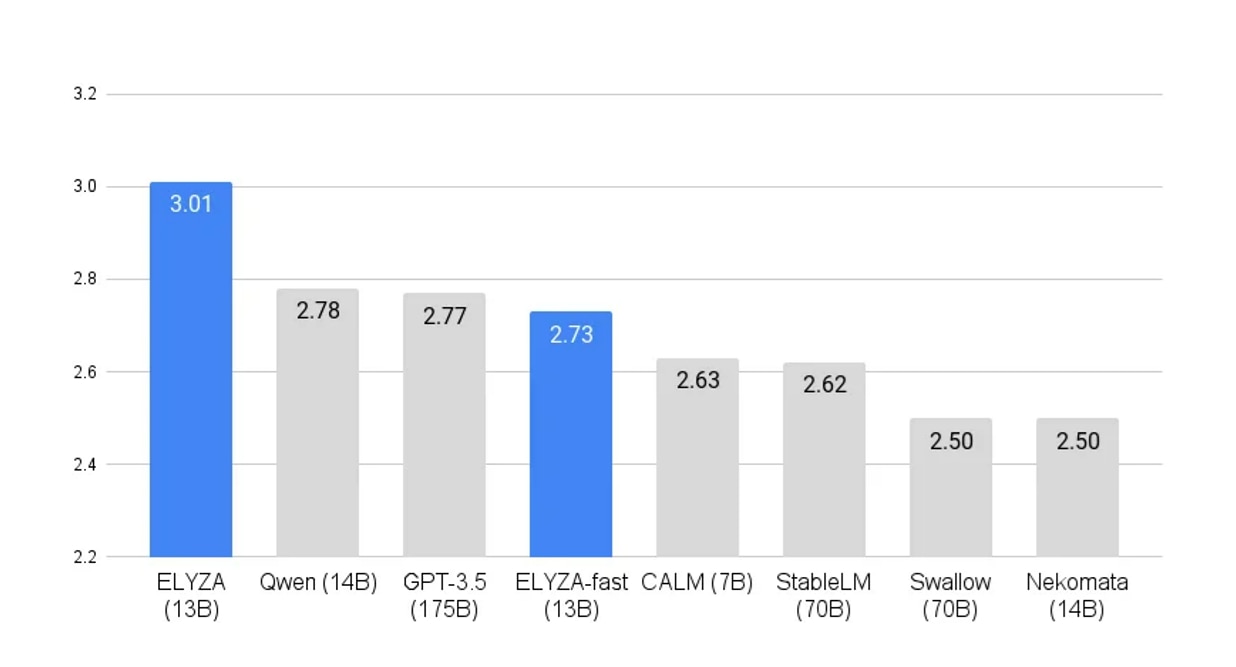
Llama2のベースモデルに対し、ELYZA社が日本語データを180億トークン追加で事前学習させた「ELYZA-japanese-Llama-2」というモデルがあります。
このモデルは日本語LLMの中でも最大級の規模であり、ELYZA Task 100という日本語LLMの性能評価では最高水準の評価を受けています。
ELYZA-japanese-Llama-2の具体的な使い方については、以下の記事で詳しく解説しています。
Llama-3-ELYZA-JPの使い方については、別記事で詳しく解説しています。
Llama2を動かすにはGPUが必要
Llama2などのLLMを利用する際には、大量の計算を行うためにGPUが必要です。
Llama2において推論を実行する際の「GPUメモリ使用量」、「ストレージ使用量」、「使用したGPU」について、各モデルごとにまとめています。モデルのサイズが大きくなると、より大きなGPUメモリ(VRAM)とストレージ容量が必要になることが分かります。
この記事では量子化を使って、精度を落とす代わりにモデルを軽量化して、1GPUで実行する方法を紹介してます。
model_id |
GPUメモリ(VRAM)使用量
※4bit量子化を使用
|
ストレージ使用量 |
使用したGPU |
meta-llama/Llama-2-7b-hf |
6.7GB |
13GB |
NVIDIA A4000 16GB x 1 |
meta-llama/Llama-2-13b-hf |
10.3GB |
25GB |
NVIDIA A4000 16GB x 1 |
meta-llama/Llama-2-70b-hf |
37.9GB |
129GB |
NVIDIA A100 80GB x 1 |
meta-llama/Llama-2-7b-chat-hf |
6.7GB |
13GB |
NVIDIA A4000 16GB x 1 |
meta-llama/Llama-2-13b-chat-hf |
10.1GB |
25GB |
NVIDIA A4000 16GB x 1 |
meta-llama/Llama-2-70b-chat-hf |
37.9GB |
129GB |
NVIDIA A100 80GB x 1 |
HugginFaceの記事によると量子化を行わない場合は、Llama-2-70bの場合で、140GBのGPUメモリが必要になります。またGithubでは、8つのマルチGPU構成(=MP 8)を使用することを推奨されています。
Llama2を使用するための環境
Llama2は、基本的にはモデルをローカル環境またはクラウド環境にダウンロードして利用しますが、他にもブラウザやAPIを介して利用する方法もあります。
それぞれの使い方について詳しく説明していきます。
- ローカルPC(Windows、Mac、Linux)
- GPUクラウドサービス(Linux)
- ブラウザ(デモサイト)
- Web APIを介して利用する
Windows + GPUのローカル環境
Llama2-7bモデルの推論を実行する場合、GPUメモリ(VRAM)が16GBのローカルPCで利用できます。
ただし、70bモデルの推論やモデルのファインチューニングになると、より大きなGPUメモリが必要です。本格的なLLM開発には、マルチGPUで高速に計算ができるNVIDIA A100やH100が推奨されます。
Windows + GPUのローカル環境の使い方については、以下の記事で詳しく解説しています。
Windows + CPUのローカル環境(Llama.cpp、Llama-cpp-python)
Llama.cppはCPUやM1チップだけでLLMを動かせるランタイムです。
このランタイムでは、4bitの量子化を使ってモデルを軽くし、CPUでもLlama2を実行できます。ただし、処理速度はかなり低下しますので、できるだけGPUを使うことをお勧めします。
Llama.cppはC言語で書かれていますが、Pythonで動くlama-cpp-pythonも利用できます。
Windows + CPUのローカル環境で「Llama.cpp」を使う方法は、以下の記事で詳しく解説しています。
Windows + CPUのローカル環境で「Llama-cpp-python」を使う方法については、以下の記事で解説しています。
Macのローカル環境(Llama.cpp、Llama-cpp-python)
Llama.cppはもともとMacBookでLlamaを実行することを目指して開発されたランタイムです。
Macの環境では、主にM1チップを利用して、4bit量子化されたLlama2モデルを実行することが可能です。
Llama-2-7bの軽量モデルの推論には対応していますが、より大きなモデルの推論やファインチューニングにはGPUの使用をお勧めします。
Llama.cppはC言語で記述されていますが、Pythonで動くLlama-cpp-pythonも使用できます。
Macのローカル環境での「Llama.cpp」の具体的な使い方は、以下の記事で詳しく解説されています。
「Llama-cpp-python」をMacのローカル環境で使う方法についても、以下の記事で解説しています。
GPUクラウドサービスとは
ハイスペックなPCの購入や運用にハードルを感じる方には、GPUクラウドサービスがおすすめです。
GPU搭載のサーバーをクラウド上で利用できるため、ハイスペックなPCを購入する必要はありません。PCを購入してしまうと後からスペックを上げることが難しいですが、クラウドサーバーなら時間単位で借りられて、スペックの変更も簡単です。
インターネット環境さえあれば、ローカルPCは低スペックでも問題なく、Windows・MacのどちらのPCからでも接続して利用できます。
GPUクラウドサービスでは、以下のようなサービスが提供されています。
- Google Colab
- GPUSOROBAN
- Amazon Web Service(AWS)
- Microsoft Azure(Azure)
- Google Cloud Platform(GCP)
Google Colaboratory(Colab)の環境
Google Colab(Colab)は、Googleが提供するブラウザ上でJupyter Notebook形式のPython実行サービスです。Colab上でLlama2を実行することが可能です。
Colabは通常のクラウドサービスとは異なり、一時的に利用するための簡便なサービスです。そのため、セッションが自動的に切れたり、環境やデータの保存ができなかったり、GPUの使用に制限があるなど、いくつかの制約がありますので、ご注意ください。
ColabでLlama2を使用する方法については、以下の記事で詳しく解説しています。
GPUクラウドサービス(GPUSOROBAN)の環境
GPUSOROBANは、業界最安級のGPUクラウドサービスで、1時間50円から利用できます。
AWSやGCP、AzureのGPUクラウドと比較して50%~70%も安い料金で、高性能なNVIDIA GPUを活用できます。Google ColabのようなGPU使用量の制限やランタイムリセット時にデータが削除される心配もありません。
GPUに特化したシンプルなサービスで、クラウドサーバー(インスタンス)の設定はわずか3分で完了します。データ転送料やストレージコストもインスタンス利用料に含まれ、明瞭で理解しやすい料金体系を採用しています。
国内最上位のNVIDIAエリートパートナーに認定され、日本人による技術サポートも無料で提供されます。
GPUSOROBANを使ったLlama2の使い方については、以下の記事で詳しく解説しています。
Llama2を追加学習・ファインチューニングする方法
Llama2のモデルを新しい領域やタスクに適応させるためにファインチューニング(追加学習)を行うことができます。
専門的な情報やローカルな情報など、未知のデータを使ってモデルをファインチューニングすることで、Llama2ベースの独自のモデルを作成できます。
Llama2をファインチューニングする手順については、以下の記事で詳しく解説しています。
Text generation web UIの使い方
Text generation web UI とは、言語生成AI(LLM)のモデルをGUIで使用できるツールです。
無料でインストールすることができ、Web UIの起動後は、コーディング不要でテキスト生成ができるようになります。
ブラウザでLlama2を体験してみる
llama2.aiは、手軽にLlama2を試せるデモサイトです。
ブラウザのWebアプリ上でプロンプトを入力するだけで、簡単にテキスト生成ができます。
llama2.aiはあくまでもデモサイトになりますので、本格的に使用する場合は、ローカル環境やクラウドの環境を用意する必要があります。
llama2.aiの詳しい使い方は、以下の記事で解説されています。
Llama2をAPIで使う方法(Replicate API)
Replicateは、手軽に生成AIモデルを実行できるクラウドプラットフォームです。
このプラットフォーム上で提供される生成AIモデルは、Web APIを通じてアクセス可能です。
APIを利用することで、数行のコードを実装するだけで、簡単にLlama2を実行できます。
Llama2のAPIを使用した具体的な手順については、以下の記事で詳しく解説しています。
Llama2を推論で動かす
ここからはLlama2のChatモデルを利用して、以下の推論タスクを実行していきます。
- テキスト生成
- 質問応答
- テキスト分類
- テキスト要約
- テキスト抽出
- 日本語翻訳
- コード生成
Metaへのモデル利用申請とHuggingFaceの設定
Llama2を利用する前に、Meta社とHuggingFaceへのモデルの利用申請を行います。
設定が完了したら、HuggingFaceのアクセストークンを後で使いますので、メモしておきます。
Metaへのモデル利用申請・HuggingFaceの設定方法について、以下の記事で詳しく解説しています。
推論環境の準備
この記事では、Jupyter Lab形式でLlama2の推論を行います。そのため、環境構築の手順はそれぞれの環境に合わせて記事をご確認ください。
ローカルPC(Windows)の環境構築に関する詳細は、以下の記事で解説しています。
GPUSOROBAN(Ubuntu)の環境構築に関する詳細は、以下の記事で解説しています。
Google Colabの環境構築に関する詳細は、以下の記事で解説しています。
ライブラリのインストール
Jupyter Labを起動したら、新しいNotebookを開きます。
Notebookのコードセルに以下のコマンドを実行し、必要なライブラリをインストールします。
コードセルにコマンドを入力し、[Alt]+[Enter]キーで実行できます。
Windows, GPUSOROBANの場合
Google Colabの場合
必要なライブラリをインポートします。
モデルの設定
HuggingFaceのtransformersというライブラリを使用してモデルの準備をします。
HuggingFaceで利用申請したLlamaのモデルを読み込みます。
この段階でモデルがGPUメモリにロードされますので、しばらく時間がかかります。
この記事ではLlama-2-70b-chat-hfのパラメータ70bのチャットモデルを使用していますが、他のモデルを使いたい場合は、表を参考に適宜model_idを変更してください。
model_id |
GPUメモリ(VRAM)使用量
※4bit量子化を使用
|
ストレージ使用量 |
使用したGPU |
meta-llama/Llama-2-7b-hf |
6.7GB |
13GB |
NVIDIA A4000 16GB x 1 |
meta-llama/Llama-2-13b-hf |
10.3GB |
25GB |
NVIDIA A4000 16GB x 1 |
meta-llama/Llama-2-70b-hf |
37.9GB |
129GB |
NVIDIA A100 80GB x 1 |
meta-llama/Llama-2-7b-chat-hf |
6.7GB |
13GB |
NVIDIA A4000 16GB x 1 |
meta-llama/Llama-2-13b-chat-hf |
10.1GB |
25GB |
NVIDIA A4000 16GB x 1 |
meta-llama/Llama-2-70b-chat-hf |
37.9GB |
129GB |
NVIDIA A100 80GB x 1 |
HuggingFaceにアクセスするためのトークンを設定します。
HuggignFaceでのアクセストークンの発行方法は以下の記事で解説しています。
モデルの量子化の設定を行います。
量子化は、モデルのパラメータや活性化関数などを低bitに変換する技術で、モデルサイズを軽量化することができます。
この記事では、モデルのパラメータを4bitでロードするように設定し、4bitの計算に使用されるデータ型をBFloat16に設定しています。
モデルを読み込みます。初回はモデルをダウンロードするため時間がかかりますが、
2回目以降はモデルの読み込み
トークナイザーを読み込みます。
transformers ライブラリの pipeline 関数を使用して、テキスト生成のためのパイプラインを構築します。
テキスト生成のタスク
プロンプトの実行
タイ旅行のスケジュールを作成するプロンプトを実行してみます。
生成結果
タイの観光地やスケジュールなどプロンプトに忠実な回答が得られました。
便宜上max_length=300のトークン数で生成していますが、生成するトークン数の上限を増やすこともできます。
日本語翻訳
質問応答のタスク
プロンプトの実行
LLMパラメーターの”temperature”を調整した場合にテキスト生成にどのような影響を及ぼすか質問をしました。
生成結果
LLMパラメーターの”temperature”の質問に対して適切な回答が得られました。
日本語翻訳
テキスト分類のタスク
プロンプトの実行
ニュース記事の文章から、記事が次のどのカテゴリに分類されるかを確認します。
カテゴリ:「テック」「エンタメ」「健康」
生成結果
生成結果はニュース記事を”Tech”に分類しており正解です。根拠も適切な内容になっています。
日本語翻訳
テキスト要約のタスク
プロンプトの実行
ニュース記事を要約するプロンプトを実行します。
生成結果
生成結果では、ニュース記事を適切に要約できています。
日本語翻訳
テキスト抽出のタスク
プロンプトの実行
生成結果
生成結果では、要求に対して適切に文章を抽出できています。
日本語翻訳
日本語翻訳のタスク
プロンプトの実行
英語から日本語へ翻訳するプロンプトを実行します。
生成結果
生成結果では正確な翻訳になっています。
コード生成のタスク
プロンプトの実行
PyTorchのDataLoaderの使い方をLlama2に尋ねてみます。
生成結果
生成結果では、有用なアドバイスの内容になっています。
LLMならGPUクラウド
Llama2やその他のLLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドがおすすめです。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Llama2を使用してテキストを生成する方法(推論)について紹介しました。
Llama2は無料で使えて商用利用可能な利便性の高いモデルでありながら、ChatGPTと同等以上の性能があります。
Llama2についてさらに詳しく知りたい方は、関連記事もあわせてご覧ください。
Llama2のファインチューニングの使い方
Llama2の日本語学習済みモデルの使い方
コード生成に特化したCodeLlamaの使い方



