

【Llama2】Google Colabでの使い方
この記事では、Google Colabの環境を使ってLlama2によるテキスト生成をする方法(推論)について紹介しています。
目次[非表示]
- 1.Llama2とは
- 2.Metaへのモデル利用申請とHuggingFaceの設定
- 3.Google Colabとは
- 4.ノートブック・ランタイムの準備
- 5.モデルの設定
- 6.生成タスク1
- 7.生成タスク2
- 8.生成タスク3
- 9.LLMならGPUクラウド
- 10.まとめ
Llama2とは
Llama2(ラマツー)とは、Facebookを運営するMeta社が開発した言語生成AI(LLM)で、OpenAI社のChatGPTに匹敵するの性能を持っています。
Llama2の特徴としては、軽量モデルで高性能、そして無料で使えるオープンソースであるため、開発者にとって扱いやすいモデルになっています。

Llama2の詳細については、以下の記事で解説しています。
Metaへのモデル利用申請とHuggingFaceの設定
Llama2を利用する前に、Meta社へのモデル利用の申請とHuggingFaceの設定の準備を行います。
設定が完了したら、HuggingFaceのアクセストークンを後で使いますので、メモしておきます。
Metaへのモデル利用申請・HuggingFaceの設定方法について、以下の記事で詳しく解説しています。
Google Colabとは
Google Colabratory(Colab)は、Googleが提供しているブラウザからJupyter note book形式でPythonを実行できるサービスです。Colab上でLlama2のモデルを動かすことが出来ます。
Colabは一般的なクラウドサーバーと異なり、あくまでも一時的に使うためのサービスであるためデータが保持できないなど、様々な制限がありますので、ご利用の際はご注意ください。
ノートブック・ランタイムの準備
以下のリンクからGoogle Colabにアクセスします。
[ファイル]タブから[ノートブックを新規作成]を選択します。
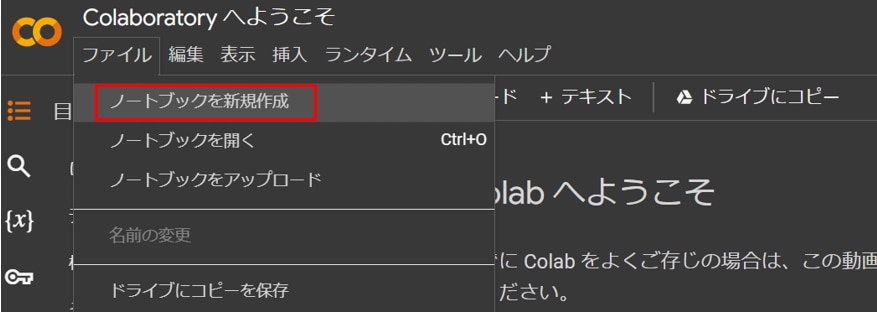
[ランタイム]タブから[ランタイムのタイプを変更]を開き、[T4GPU]を選択し、[保存]ボタンを押します。
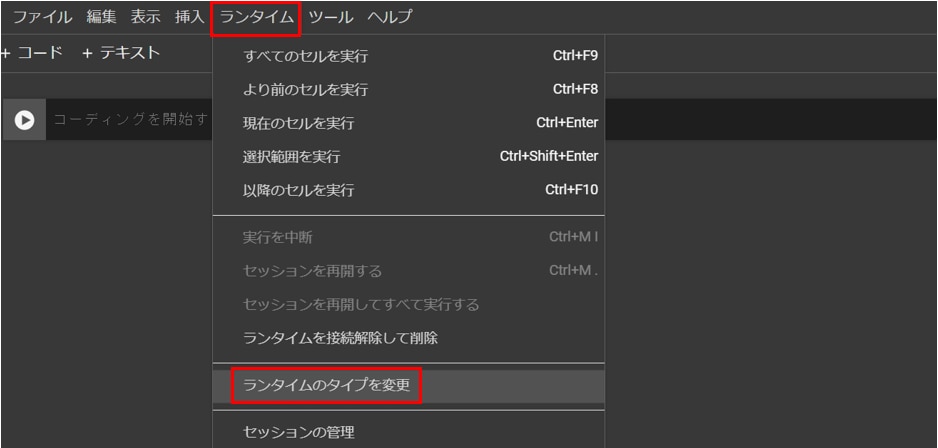
※T4 < V100 < A100の順にGPUメモリの容量が大きく、計算速度が早くなりますが、A100やV100が割り当てられるのは稀なため、最低限T4が割り当てられればOKです。
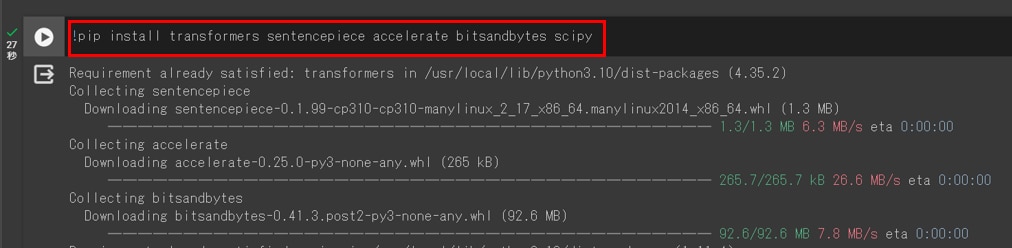
Google Colabのコードセルで次のコマンドを実行し、必要なパッケージをインストールします。
次のコマンドを実行し、必要なライブラリをインポートします。

モデルの設定
HuggingFaceで利用申請したLlamaのモデルを読み込みます。
この段階でモデルがGPUメモリにロードされますので、しばらく時間がかかります。
この記事ではLlama-2-7b-chat-hfのパラメータ7bのチャットモデルを使用していますが、他のモデルを使いたい場合は表を参考に適宜model_idを変更してください。
model_id |
GPUメモリ(VRAM)使用量 |
ストレージ使用量 |
使用したGPU |
meta-llama/Llama-2-7b-hf |
6.7GB |
13GB |
NVIDIA T4 16GB x 1 |
meta-llama/Llama-2-13b-hf |
10.3GB |
25GB |
NVIDIA T4 16GB x 1 |
meta-llama/Llama-2-70b-hf |
37.9GB |
129GB |
NVIDIA A100 80GB x 1 |
meta-llama/Llama-2-7b-chat-hf |
6.7GB |
13GB |
NVIDIA T4 16GB x 1 |
meta-llama/Llama-2-13b-chat-hf |
10.1GB |
25GB |
NVIDIA T4 16GB x 1 |
meta-llama/Llama-2-70b-chat-hf |
37.9GB |
129GB |
NVIDIA A100 80GB x 1 |
HuggingFaceにアクセスするためのトークンを設定します。
HuggignFaceでのアクセストークンの発行方法は以下の記事で解説しています。
モデルの量子化の設定を行います。
量子化は、モデルのパラメータや活性化関数などを低bitに変換する技術で、モデルサイズを軽量化することができます。
モデルを読み込みます。初回はモデルをダウンロードするため時間がかかりますが、
2回目以降はモデルの読み込みだけになりますので、時間はかかりません。
トークナイザーを読み込みます。
transformersライブラリの pipeline 関数を使用して、テキスト生成のためのパイプラインを構築します。
生成タスク1
プロンプトの実行
transformers.pipelineについて質問してみます。
生成結果
日本語翻訳
生成タスク2
プロンプトの実行
Pythonの仮想環境について質問してみます。
生成結果
日本語翻訳
生成タスク3
プロンプトの実行
Docker composeについて質問してみます。
生成結果
日本語翻訳
LLMならGPUクラウド
Llama2やその他のLLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Google Colabの環境でLlama2を用いて推論をする方法を紹介しました。
Llama2は無料で使えて商用利用可能な利便性の高いモデルでありながら、ChatGPTと同等以上の性能があります。
Llama2に関する詳細な情報は、以下の記事でまとめて紹介していますので、あわせてご覧ください。



