

【Llama2】Macでの Llama.cppの使い方 | ローカル環境
この記事では、Macのローカル環境を使ってLlama.cppによるテキスト生成をする方法(推論)について紹介しています。
目次[非表示]
- 1.Llama2とは
- 2.Macのローカル環境Llama2を動かす(Llama.cpp)
- 3.LLama 2 のモデル一覧
- 4.実行環境
- 5.ビルドツールのインストール
- 6.Llama.cppのビルド
- 7.モデルのダウンロード
- 8.テキスト生成
- 9.生成AI・LLMならGPUクラウド
- 10.まとめ
Llama2とは
Llama2(ラマツー)とは、Facebookを運営するMeta社が開発した言語生成AI(LLM)で、OpenAI社のChatGPTに匹敵するの性能を持っています。
Llama2の特徴としては、軽量モデルで高性能、そして無料で使えるオープンソースであるため、開発者にとって扱いやすいモデルになっています。
Llama2の詳細については、以下の記事で解説しています。
Macのローカル環境Llama2を動かす(Llama.cpp)
Llama.cppはもともとMacBookでLlamaを実行することを目指して開発されたランタイムです。
Macの環境では、主にM1チップを利用して、4bit量子化されたLlama2モデルを実行することが可能です。
この記事では、Llama.cppについて解説しています。
Llama.cppはC言語で書かれていますが、Pythonで使えるllama-cpp-pythonもあります。
llama-cpp-pythonについて詳しく知りたい方は下記の記事をご覧ください。
LLama 2 のモデル一覧
「Llama.cpp」を利用するには、「Llama 2」モデルをGGUF形式に変換する必要があります。
HuggingFaceには、変換済みのモデルが公開されています。
Llama.cppの量子化モデルは、2bit~8bitまでたくさんのバリエーションがありますが、大半のモデルは低品質になりますので推奨されていません。
HiggingFaceで推奨されているモデルは以下の通りです。
量子化メソッドの[Q4_K_M]、[Q5_K_S]、[Q5_K_M]が推奨されています。
model_id |
メモリ(RAM)の使用量※ |
ストレージの使用量 |
量子化メソッド |
量子化bit |
llama-2-7b-chat.Q4_K_M.gguf |
6.58 GB |
4.08GB |
Q4_K_M |
4bit |
llama-2-7b-chat.Q5_K_S.gguf |
7.15 GB |
4.65GB |
Q5_K_S |
5bit |
llama-2-7b-chat.Q5_K_M.gguf |
7.28 GB |
4.78GB |
Q5_K_M |
5bit |
llama-2-13b-chat.Q4_K_M.gguf |
10.37 GB |
7.87 GB |
Q4_K_M |
4bit |
llama-2-13b-chat.Q5_K_S.gguf |
11.47 GB |
8.97 GB |
Q5_K_S |
5bit |
llama-2-13b-chat.Q5_K_M.gguf |
11.73 GB |
9.23 GB |
Q5_K_M |
5bit |
llama-2-70b-chat.Q4_K_M.gguf |
43.92 GB |
41.42 GB |
Q4_K_M |
4bit |
llama-2-70b-chat.Q5_K_S.gguf |
33.07 GB |
30.57 GB |
Q5_K_S |
5bit |
llama-2-70b-chat.Q5_K_M.gguf |
51.25 GB |
48.75 GB |
Q5_K_M |
5bit |
※メモリ(RAM)の使用量には、GPUオフロードが含まれていません。GPUを使用する場合は、RAMの使用量が減り、代わりにGPUメモリ(VRAM)が使用されます。
※Llama.cppで扱えるモデル形式は過去GGMLが使われていましたが、現在はGGUFが使われています。
実行環境
この記事では以下のスペックのMacBookを使用しました。
- MacBook Pro
- チップ Apple M1 Pro
- メモリ 16GB
ビルドツールのインストール
Llama.cppはソースコードからビルドして利用する必要がありますので、ビルドツールのインストールから行います。
まだインストールしていない場合はHomebrewをインストールします。
ターミナルを開き、次のコマンドをコピペしてEnterを押すとインストールが実行されます。

ターミナルで次のコマンドを実行し、Homebrewのパスを通します。
![]()
インストール完了およびPATHが通っているか確認します。
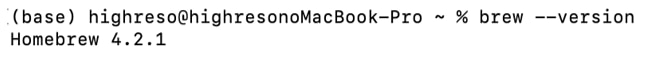
必要なパッケージをインストールします。
Xcodeをインストールします。
Llama.cppのビルド
ターミナルで次のコマンドを実行し、llama.cppのリポジトリのクローンを作成します。
llama.cppフォルダに移動します
ビルドします。
モデルのダウンロード
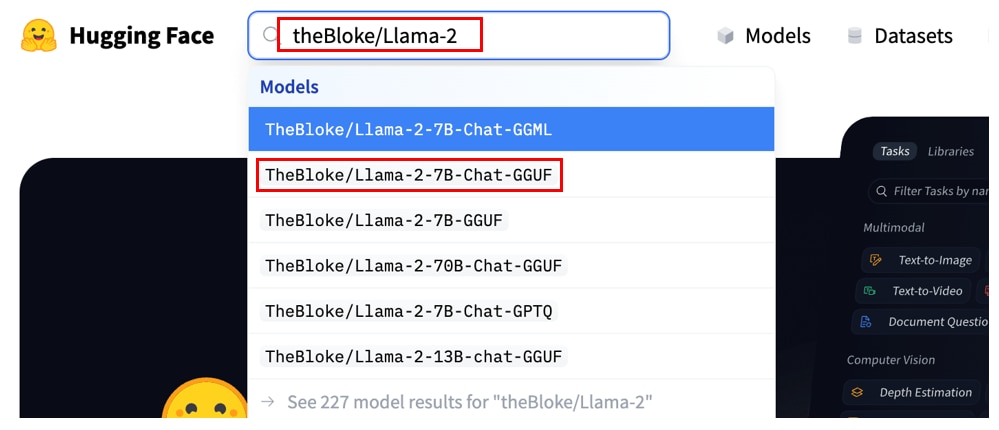
HuggingFaceのサイトにアクセスし、検索窓に[TheBloke/Llama-2]と入力すると、
TheBloke/Llama-2-(7b or 13b or 70b)-Chat-GGUFが表示されますので、[TheBloke/Llama-2-7b-Chat-GGUF ]を選択します。
*末尾がGGMLと書かれたものは古い形式になりますので、選ばないようにご注意ください。
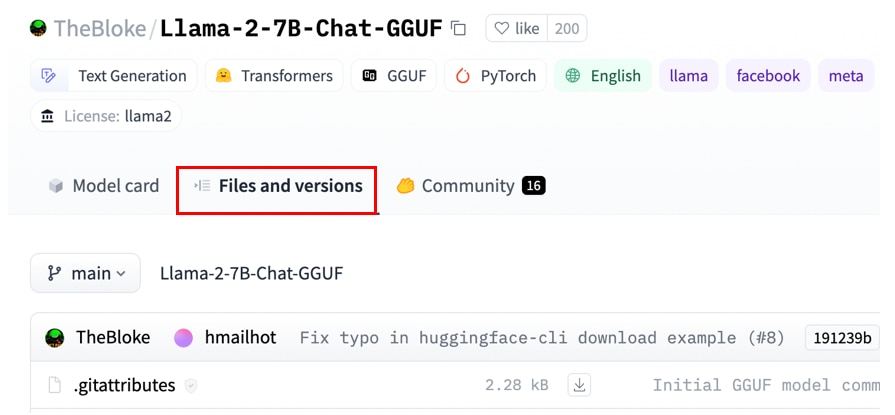
モデルのページに遷移したら、[Files and versions]のタブを開きます。
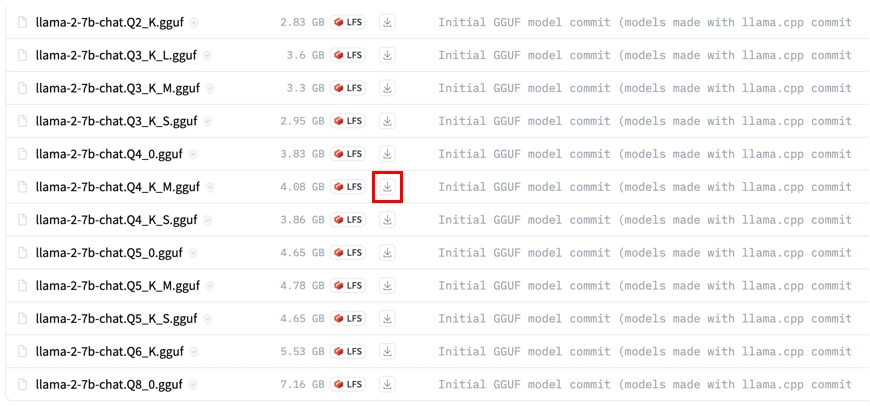
モデルの一覧が表示されますので、
ダウンロードする対象のモデルの[ダウンロード]アイコンにカーソルを合わせて、
右クリックで[リンクのアドレス]を選択し、コピーします。
モデルを格納するディレクトリに移動します。
先程コピーしたURLを使って、モデルをダウンロードします。
※ダウンロードしたモデルのファイル名の末尾に[?download=true]が付いている場合はこの部分を除外する形でファイル名を変更してください。
テキスト生成
プロンプトの実行
新製品のキャッチフレーズを生成する推論を実行しました。
生成結果
日本語翻訳
生成AI・LLMならGPUクラウド
Llama2やその他のLLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Macのローカル環境でLlama.cppを用いて推論をする方法を紹介しました。
Llama2は無料で使えて商用利用可能な利便性の高いモデルでありながら、ChatGPTと同等以上の性能があります。
Llama2に関する詳細な情報は、以下の記事でまとめて紹介していますので、あわせてご覧ください。



