

【Llama2】日本語モデル | ELYZA-japanese-Llama-2-7b・13b
この記事では、Llama2の日本語学習済みモデル「ELYZA-japanese-Llama-2」の使い方について解説しています。
目次[非表示]
- 1.Llama2とは
- 2.Llama2の日本語学習済みモデル「ELYZA-japanese-Llama-2」
- 3.商用利用が可能
- 4.日本語LLMで最高水準
- 5.モデルのバリエーション
- 6.モデルを動かすにはGPUが必要
- 7.実行環境
- 8.Jupyter Labを起動
- 9.必要なパッケージのインストール
- 10.モデルとトークナイザーを読み込む関数
- 11.モデル・トークナイザーを読み込む
- 12.モデルを使用してテキストを生成する関数
- 13.生成タスク1
- 14.生成タスク2
- 15.生成タスク3
- 16.生成タスク4
- 17.LLMならGPUクラウド
- 18.まとめ
Llama2とは
Llama2(Large Language Model Meta AI 2/ラマツー)とは、Facebookを運営するMeta社が開発した言語生成AI(LLM)で、OpenAI社のChatGPTに匹敵するの性能を持っています。
Llama2の特徴としては、軽量モデルで高性能、そして無料で使えるオープンソースであるため、開発者にとって扱いやすいモデルになっています。

Llama2の詳細については、以下の記事で解説しています。
Llama2の日本語学習済みモデル「ELYZA-japanese-Llama-2」
「ELYZA-japanese-Llama-2」は、Llama2をベースにELYZA社が追加事前学習を行った日本語LLMです。
パラメータ数は70億と130億のモデルがあり、いずれも商用利用も可能です。このモデルはGPT-3.5に匹敵する性能を持ち、日本語の公開モデルの中で最高水準とされています。
元のLlama 2の事前学習では、日本語はわずか0.1%(20億トークン)しか含まれていないため、追加で180億トークンの日本語データを事前学習させています。
学習に用いたのはOSCARやWikipedia等に含まれる日本語テキストデータです。
商用利用が可能
ELYZA-japanese-Llama-2のライセンスはLLAMA 2 Community Licenseに準拠しており、Acceptable Use Policy に従う限り、研究および商業目的で利用できます。
日本語LLMで最高水準
ELYZA-japanese-Llama-2-7bのモデルは、70億のパラメータを持ち、公開されている日本語のLLMとしては最大級の規模になります。
ELYZA Tasks 100という日本語LLMの性能評価においても、ELYZA-japanese-Llama-2-7bはオープンな日本語LLMのなかでは最高水準の評価がされています。
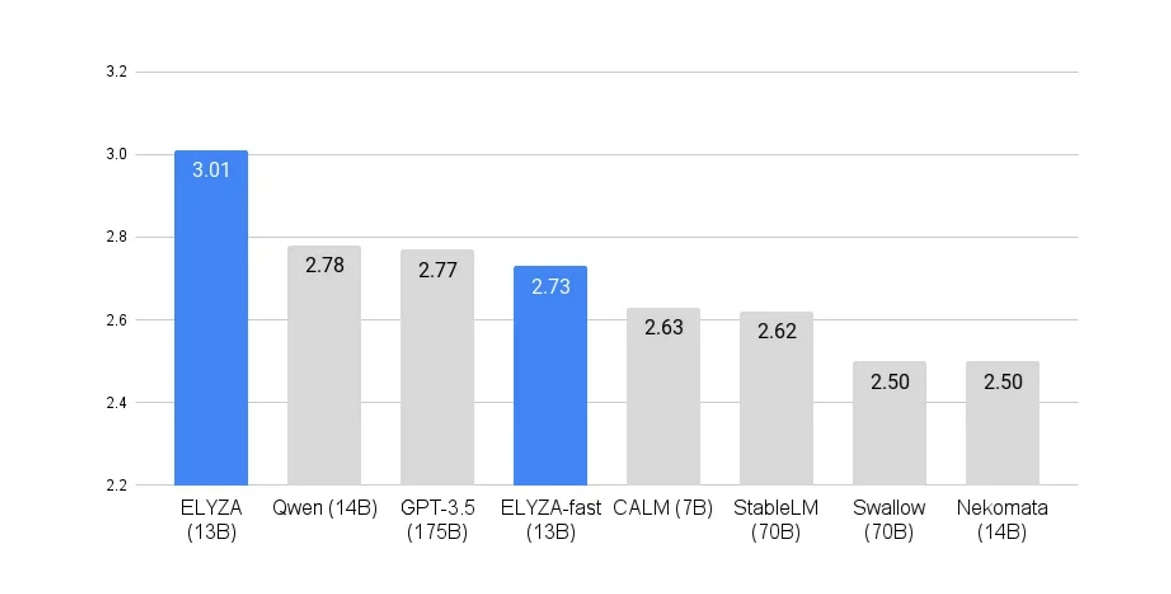
ELYZA Tasks 100による日本語LLMの性能評価比較
参考:https://note.com/elyza/n/na405acaca130
モデルのバリエーション
ELYZA-japanese-Llama-2のモデルには複数のバリエーションがあります。
ユーザーの指示に従い様々なタスクを解くために事後学習を行った「instruct」や、日本語の語彙を追加することで入出力できる文章量の改善および推論を高速化したモデルの「fast」、それらを組み合わせた「fast-instruct」があります。
model_id |
モデルの説明 |
elyza/ELYZA-japanese-Llama-2-(7b or 13b) |
Llama2に約180億トークンの日本語テキストで追加事前学習を行ったモデル |
elyza/ELYZA-japanese-Llama-2-(7b or 13b)-fast-instruct |
「ELYZA-japanese-Llama-2-(7b or 13b)」に対して事後学習を行ったモデル。 ユーザーの指示に従い多様なタスクを解くことができる。 |
elyza/ELYZA-japanese-Llama-2-(7b or 13b)-fast |
Llama 2に日本語の語彙を追加して事前学習を行ったモデル。 入出力できる文章量の効率化および推論の高速化がされている |
elyza/ELYZA-japanese-Llama-2-(7b or 13b)-fast-instruct |
「ELYZA-japanese-Llama-2-(7b or 13b)-fast」に対して事後学習を行ったモデル。に対して事後学習を行ったモデル。 「fast」と「instruct」の組み合わせ。 |
モデルを動かすにはGPUが必要
ELYZA-japanese-Llama-2などのLLMを使用する際には、大量の計算を行うためにGPUが必要です。
ELYZA-japanese-Llama-2において推論を実行する際の「GPUメモリ使用量」、「ストレージ使用量」、「使用したGPU」について、各モデルごとにまとめています。
モデルのサイズが大きくなると、より大きなGPUメモリ(VRAM)とストレージ容量が必要になることが分かります。
model_id |
GPUメモリ(VRAM)使用量 |
ストレージ使用量 |
使用したGPU |
elyza/ELYZA-japanese-Llama-2-7b |
15.7GB |
13GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-7b-instruct |
15.7GB |
13GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-7b-fast |
15.9GB |
13GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-7b-fast-instruct |
15.9GB |
13GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-13b |
27.1GB |
25GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-13b-instruct |
27.1GB |
25GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-13b-fast |
27.4GB |
25GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-13b-fast-instruct |
27.4GB |
25GB |
NVIDIA A100 80GB x 1 |
実行環境
この記事ではGPUクラウドサービス(GPUSOROBAN)を使用しました。
- インスタンス名:t80-1-a-exlarge-ubs22-i
- GPU:NVIDIA A100 80GB x 1
- OS :Ubuntu 22.04
- CUDA:11.7
- Jupyter Lab
GPUSOROBANはメガクラウドの50%以上安いGPUクラウドサービスです。
GPUSOROBANの使い方は以下の記事で解説しています。
Jupyter Labを起動
GPUSOROBANのインスタンスに接続したら、次のコマンドを実行しJupyter Labを起動します。

ブラウザの検索窓に"localhost:8888"を入力すると、Jupyter Labをブラウザで表示できます。
Jupyter Labのホーム画面で[Python3 ipykernel]を選択し、Notebookを開きます。
Jupyter Labの使い方が分からない方は、以下の記事が参考になります。
プリインストールされたJupyter Labを使用する場合は、以下の記事をご覧ください。
Jupyter Labを新しくインストールして使う場合、以下の記事をご覧ください。
必要なパッケージのインストール
JupyterLabのNotebookのコードセルで次のコマンドを実行し、必要なパッケージをインストールします。

次のコマンドを実行し、ライブラリをインポートします。
モデルとトークナイザーを読み込む関数
HuggingFaceのTransformersを使用して、事前学習済みモデルおよびトークナイザーの関数を定義します。
トークナイザーはテキストをモデルが理解できる形式に変換する機能です。
モデル・トークナイザーを読み込む
モデルとトークナイザーを読み込みます。
モデルを変更する場合は、model_idを差し替えてください。
この段階でモデルがGPUメモリにロードされますので、しばらく時間がかかります。
model_id |
GPUメモリ(VRAM)使用量 |
ストレージ使用量 |
使用したGPU |
elyza/ELYZA-japanese-Llama-2-7b |
15.7GB |
13GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-7b-instruct |
15.7GB |
13GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-7b-fast |
15.9GB |
13GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-7b-fast-instruct |
15.9GB |
13GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-13b |
27.1GB |
25GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-13b-instruct |
27.1GB |
25GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-13b-fast |
27.4GB |
25GB |
NVIDIA A100 80GB x 1 |
elyza/ELYZA-japanese-Llama-2-13b-fast-instruct |
27.4GB |
25GB |
NVIDIA A100 80GB x 1 |
モデルを使用してテキストを生成する関数
モデルとトークナイザーを活用して、与えられたプロンプトからテキストを生成する関数を定義します。B_INSTとE_INSTはプロンプトの開始と終了を示し、B_SYSとE_SYSは生成されたテキストの開始と終了を指します。
また、max_new_tokens=300は生成されるテキストの最大トークン数を指定しており、必要に応じて変更できます。
生成タスク1
日本語でモデルに質問をして、生成するタスクを実行してみます。
プロンプト
生成結果
生成タスク2
プロンプト
生成結果
生成タスク3
プロンプト
生成結果
生成タスク4
プロンプト
生成結果
LLMならGPUクラウド
Llama2やその他のLLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
本記事では、ELYZA-japanese-Llama-2を用いてテキスト生成を行いました。
このモデルは、Llama2において日本語追加学習を施したものであり、その生成結果も自然な日本語が得られました。
ELYZA社は現在、パラメータ数7B(70億)と13B(130億)までのモデルを公開していますが、70B(700億)のモデルも開発中であり、今後の展望が期待されます。
Llama2に関する使い方(まとめ)は、以下の記事で解説していますので、あわせてご覧ください。



