

【Llama2】ファインチューニング | 7b・13b・70b
この記事ではLlama2のモデルをファインチューニングする方法を解説しています。
目次[非表示]
- 1.Llama2とは
- 2.Llama2のファインチューニング
- 3.ファインチューニングにはGPUが必要
- 4.Metaへのモデル利用申請とHuggingFaceの設定
- 5.実行環境
- 6.必要なパッケージをインストール
- 7.Jupyter Labを起動
- 8.必要なライブラリをインポート
- 9.モデルの読み込み
- 10.データセットの読み込み
- 11.ベースモデルの動作確認
- 11.1.プロンプトの実行
- 11.2.ベースモデルの生成結果
- 11.2.1.Llama-2-7b-hfの生成結果
- 11.2.2.Llama-2-13b-hfの生成結果
- 11.2.3.Llama-2-70b-hfの生成結果
- 12.モデルのファインチューニング設定
- 13.パラメータとプロファイラの設定
- 14.ファインチューニングの実行
- 15.チェックポイントを保存
- 16.ファインチューニングしたモデルの評価
- 16.1.入力したプロンプト
- 16.2.生成結果
- 16.2.1.Llama-2-7b-hfの生成結果
- 16.2.2.Llama-2-13b-hfの生成結果
- 16.2.3.Llama-2-70b-hfの生成結果
- 17.LLMならGPUクラウド
- 18.まとめ
Llama2とは
Llama2(Large Language Model Meta AI 2/ラマツー)とは、Facebookを運営するMeta社が開発した言語生成AI(LLM)で、OpenAI社のChatGPTに匹敵するの性能を持っています。
Llama2の特徴としては、軽量モデルで高性能、そして無料で使えるオープンソースであるため、開発者にとって扱いやすいモデルになっています。

Llama2の詳細については、以下の記事で解説しています。
Llama2のファインチューニング
Llama2のモデルを新しい領域やタスクに適応させるためにファインチューニング(追加学習)を行うことができます。
専門的な情報やローカルな情報など、未知のデータを使ってモデルをファインチューニングすることで、Llama2ベースの独自のモデルを作成できます。
この記事ではLlama2をファインチューニングする方法を解説していきます。
ファインチューニングにはGPUが必要
Llama2でファインチューニングをする際には、大量の計算を行うためにGPUが必要です。
表をみるとモデルのサイズが大きくなると、より大きなGPUメモリ(VRAM)が必要になり、ファインチューニングの時間が長くなることが分かります。
この記事では量子化を使って、精度を落とす代わりにモデルを軽量化して、1GPUで実行する方法を紹介してます。
モデル |
量子化 |
GPUメモリ(VRAM)使用量 |
ファインチューニングの時間 |
使用したGPU |
Llama-2-7b-hf |
8bit量子化 |
18.3GB |
1時間6分 |
NVIDIA A100 80GB x 1 |
Llama-2-13b-hf |
8bit量子化 |
28.1GB |
1時間56分 |
NVIDIA A100 80GB x 1 |
Llama-2-70b-hf |
4bit量子化 |
61.8GB |
3時間24分 |
NVIDIA A100 80GB x 1 |
HugginFaceの記事によると量子化を行わない場合は、Llama-2-70bの場合で、140GBのGPUメモリが必要になります。またGithubでは、8つのマルチGPU構成(=MP 8)を使用することを推奨されています。
Metaへのモデル利用申請とHuggingFaceの設定
Llama2を利用する前に、Meta社へのモデル利用の申請とHuggingFaceの設定の準備を行います。
設定が完了したら、HuggingFaceのアクセストークンを後で使いますので、メモしておきます。
Metaへのモデル利用申請・HuggingFaceの設定方法について、以下の記事で詳しく解説しています。
実行環境
この記事ではGPUクラウドサービス(GPUSOROBAN)を使用しています。
- インスタンス名:t80-1-a-exlarge-ubs22-i
- GPU:NVIDIA A100 80GB x 1
- OS :Ubuntu 22.04
- CUDA:11.7
- Jupyter Labプリインストール
GPUSOROBANはメガクラウドの50%以上安いGPUクラウドサービスです。
GPUSOROBANの使い方は以下の記事で解説しています。
必要なパッケージをインストール
インスタンスを起動したら次のコマンドを実行します。
llama-recipesのリポジトリをインスタンスに複製します。

llama-recipesのディレクトリに移動します。
requirements.txtを開きインストールするライブラリを編集します。
1.[llama-recipes]を追加します。
2.[torch>=2.0.1]を[torch==2.0.1]に変更します。
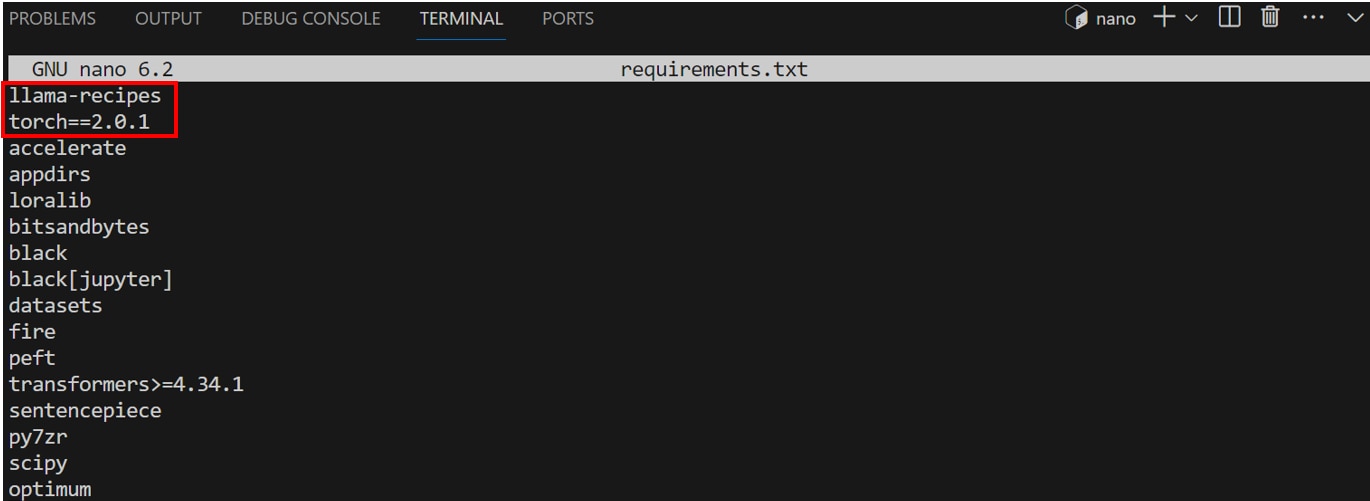
編集が完了したら[Ctrl]+[S]キーを押して変更を保存し、[Ctrl]+[X]キーで編集モードを終了します。
requirements.txtに記述されたライブラリをインストールします。
Jupyter Labを起動
次のコマンドを実行し、Jupyter Labを起動します。
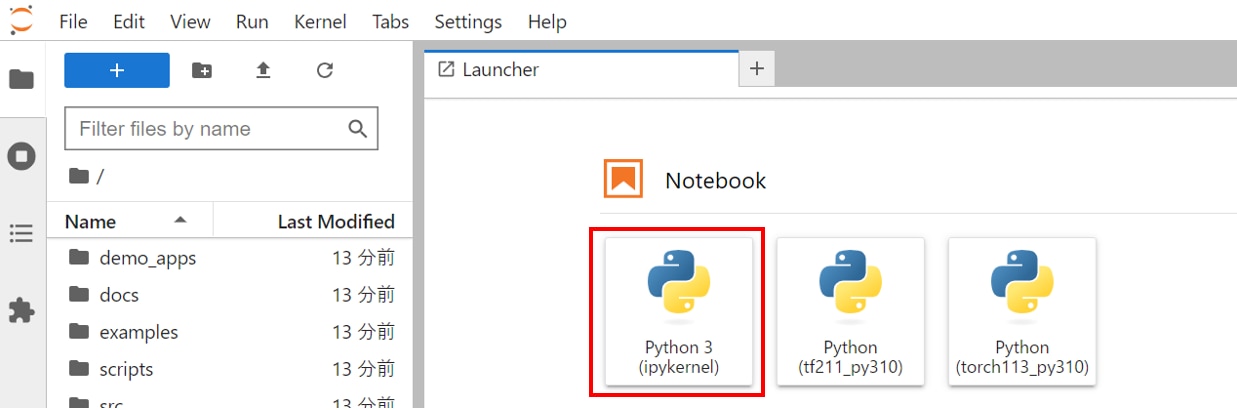
ブラウザの検索窓に"localhost:8888"を入力すると、Jupyter Labをブラウザで表示できます。
Jupyter Labのホーム画面で[Python3 ipykernel]を選択し、Notebookを開きます。
Jupyter Labの使い方が分からない方は、以下の記事が参考になります。
プリインストールされたJupyter Labを使用する場合は、以下の記事をご覧ください。
Jupyter Labを新しくインストールして使う場合の手順は以下の記事をご覧ください。
必要なライブラリをインポート
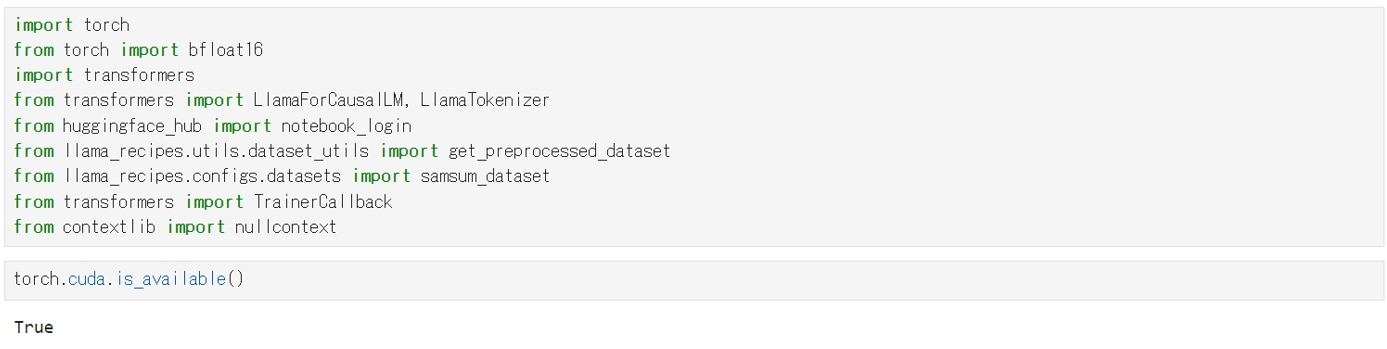
JupyterLabのNotebookのコードセルで次のコマンドを実行し、必要なライブラリをインポートします。
次のコマンドを実行し、PyTorchからGPUを認識できるか確認します
Trueが返るとPyTorchからGPUが認識できています。
モデルの読み込み
HuggingFaceにアクセスするために必要なパッケージをインストールします。
HuggingFaceにアクセスするためのトークンを設定し、ログインします。
HuggignFaceでのアクセストークンの発行方法は以下の記事で解説しています。
Llama-2-7b-hfの場合
モデルとトークナイザーを読み込みます。
8bit量子化を有効化し、GPUメモリを節約しています。
Llama-2-13b-hfの場合
モデルとトークナイザーを読み込みます。
8bit量子化を有効化し、GPUメモリを節約しています。
Llama-2-70b-hfの場合
モデルとトークナイザーを読み込みます
8bit量子化ではGPUメモリが不足したため、4bit量子化を使用しました。
データセットの読み込み
対話と要約のペアで構成されるsamsumというデータセットを読み込みます。
ベースモデルの動作確認
プロンプトの実行
対話の内容を要約するプロンプトを実行し、ファインチューニング前のベースモデルの動作確認を行います。
入力したプロンプトは以下のとおりです。
ベースモデルの生成結果
生成結果は以下のとおりです。
どのサイズのモデルにおいても、ファインチューニング前のベースモデルでは要約ができていないことが分かります。
Llama-2-7b-hfの生成結果
Llama-2-13b-hfの生成結果
Llama-2-70b-hfの生成結果
モデルのファインチューニング設定
ここでは、PEFT(Parameter Efficient Fine-Tuning)を使用したファインチューニングの設定を行います。
PEFTは、少量のパラメータのみをファインチューニングする効果的な手法であり、計算量を削減しGPUのコストを抑えることができます。
具体的には、PERTに関連するパラメーターの設定と、モデルの量子化に関する設定を行います。
パラメータとプロファイラの設定
PyTorch Profilerを使ってファインチューニングのプロセスをプロファイリングするための設定を行います。
プロファイラはトレーニングの各ステップでのパフォーマンスデータを収集し、ログを保存します。
ファインチューニングの実行
ファインチューニングのトレーニングについて、パラメータの設定を行います。
その後プロファイラのセットアップを行い、トレーニングを開始します。

ファインチューニングにかかった時間は以下のとおりです。
モデル |
量子化 |
GPUメモリ(VRAM)使用量 |
ファインチューニングの時間 |
使用したGPU |
Llama-2-7b-hf |
8bit量子化 |
18.3GB |
1時間6分 |
NVIDIA A100 80GB x 1 |
Llama-2-13b-hf |
8bit量子化 |
28.1GB |
1時間56分 |
NVIDIA A100 80GB x 1 |
Llama-2-70b-hf |
4bit量子化 |
61.8GB |
3時間24分 |
NVIDIA A100 80GB x 1 |
チェックポイントを保存
モデルのチェックポイントを保存します。
ファインチューニングしたモデルの評価
モデルを評価モードにして推論を実行します。
ファインチューニング済みのモデルを使用して、テキストの要約ができるか確認します。
入力したプロンプト
前述のコードセルで実行した評価用のプロンプトは以下のとおりです。
ここでは要約前の比較として表示していますので、コードセルで実行する必要はありません。
生成結果
いずれのモデルも要約ができています。70bのモデルが最もシンプルにまとめられていました。
Llama-2-7b-hfの生成結果
Llama-2-13b-hfの生成結果
Llama-2-70b-hfの生成結果
LLMならGPUクラウド
Llama2やその他のLLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- GPU陳腐化の対策になる
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Llama2をファインチューニングする方法を紹介しました。
ファインチューニングにより、未知のデータをモデルに学習させて新しい領域やタスクに適応させることができます。
Llama2に関する使い方(まとめ)は、以下の記事で解説していますので、あわせてご覧ください。



