

【Llama2】無料でブラウザでお試しできる | llama2.ai
この記事では、Llama2をWEBブラウザで使う方法について解説しています。
目次[非表示]
- 1.Llama2とは
- 2.ブラウザで使えるllama2.ai
- 3.llama2.aiの使い方
- 4.モデルの設定
- 5.System Promptの設定
- 6.Temperatureの設定
- 7.Max Tokensの設定
- 8.Top Pの設定
- 9.テキスト生成
- 10.生成AI・LLMならGPUクラウド
- 11.まとめ
Llama2とは
Llama2(Large Language Model Meta AI 2/ラマツー)とは、Facebookを運営するMeta社が開発した言語生成AI(LLM)で、OpenAI社のChatGPTに匹敵するの性能を持っています。
Llama2の特徴としては、軽量モデルで高性能、そして無料で使えるオープンソースであるため、開発者にとって扱いやすいモデルになっています。

Llama2の詳細については、以下の記事で解説しています。
ブラウザで使えるllama2.ai
llama2.aiは、手軽にLlama2を試せるデモサイトです。
ブラウザのWebアプリ上でプロンプトを入力するだけで、簡単にテキスト生成ができます。
llama2.aiはあくまでもデモサイトになりますので、実践的に使いたい方は以下の記事をご覧ください。
llama2.aiの使い方
llama2.aiには以下のサイトからアクセスできます。
モデルの設定
[Settings]タブからサイドバーを開きます。
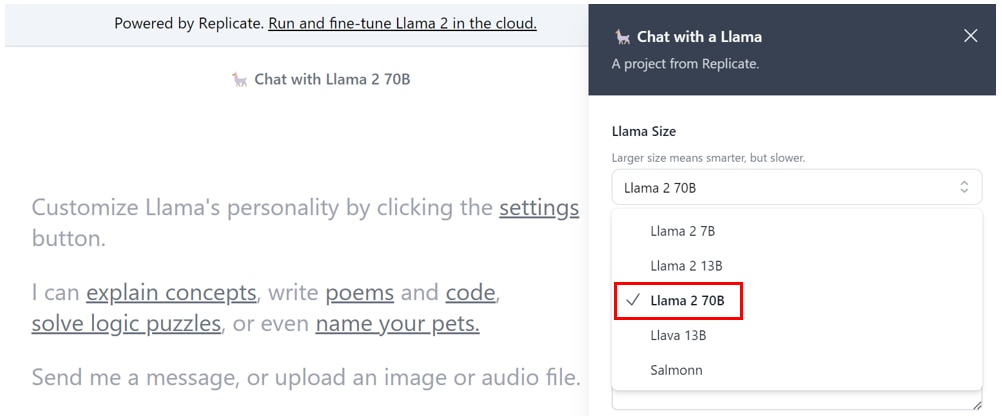
[Llama Sizse]で任意のモデルを選択します。
パラメータ数が大きいモデルほど、テキスト生成の性能が高くなります。
- Llama2 7B :70億パラメータ
- Llama2 13B :130億パラメータ
- Llama2 70B :700億パラメータ
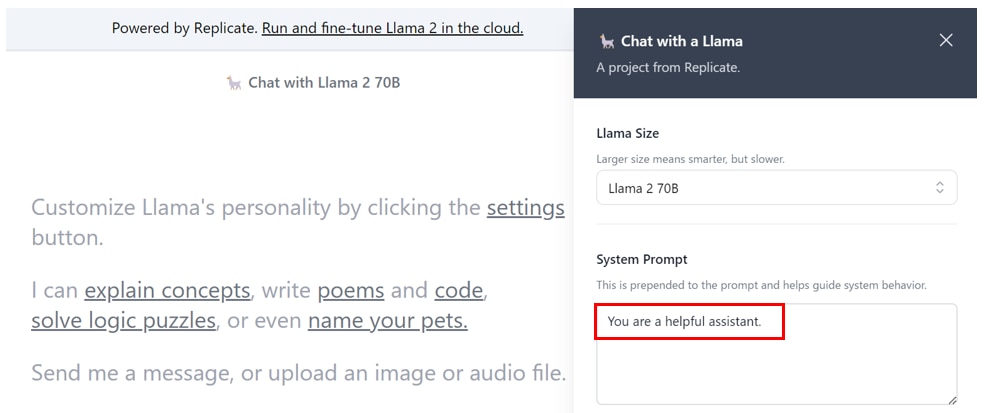
System Promptの設定
[System Prompt]は、モデルに対してユーザーが与える前提情報になります。
“You are a helpful assistant.”
“You are an excellent programmer”
“You are an excellent tour guide”
など前提となる情報を英語でインプットします。
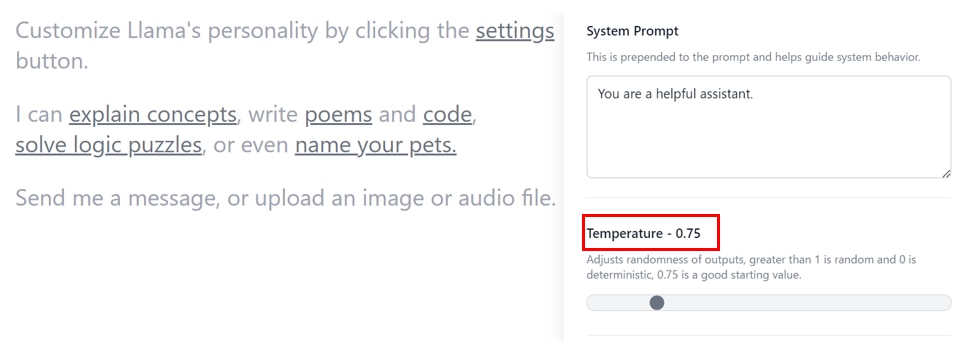
Temperatureの設定
[Temperature]は、生成されるテキストの多様性やランダム性を制御するパラメータです。
Temperatureが高いと、確率分布の散らばりが小さくなります。つまり生成確率の高いトークンと生成確率の低いトークンの差が小さくなるため、生成のランダム性が高くなります。生成されるテキストは多様で創造的になりますが、再現性は低くなります。
逆にTemperatureが低いと確率分布の散らばりが大きくなります。つまり生成確率の高いトークンと生成確率の低いトークンの差が大きくなるため、生成のランダム性が低くなります。生成されるテキストは文脈に忠実で再現性が高くなります。
Temperatureの初期値は0.75から始めることを推奨しています。
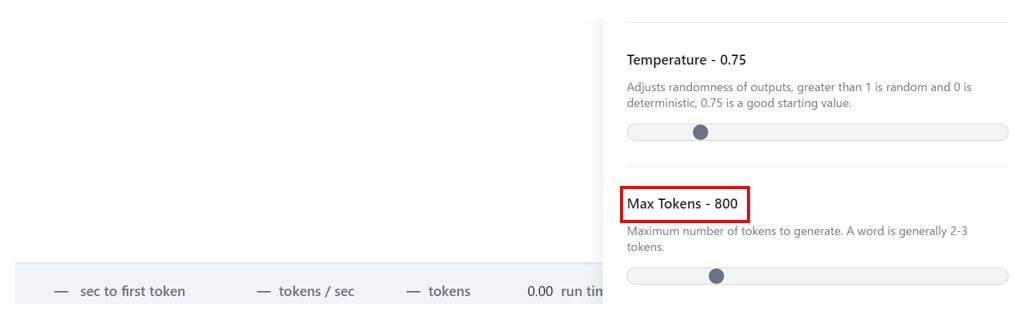
Max Tokensの設定
[Max Tokens]では、生成されるトークンの数の最大値を指定します。
生成されるテキストが途中で切れてしまう場合は、Max Tokensを上げて生成するテキストの量を増やすことができます。
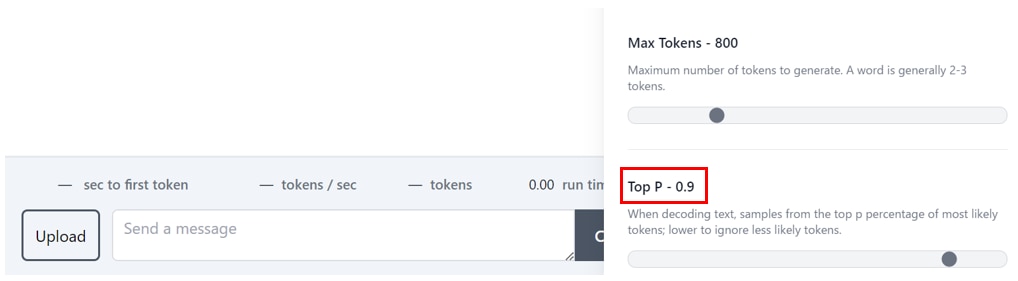
Top Pの設定
[Top P] は、確率分布からトークンを選ぶ際に、上位一定割合のトークンのみを生成対象として、それ以外を足切りするときに使うパラメータです。
Top Pの値を高くとると生成されるテキストの多様性を高めることができますが、生成の再現性が低くなります。
Top Pの値を低く設定すると、生成候補が少なくなり、生成の再現性が高くなります。
特殊なケースでない限りは0.8~1に設定することを推奨します。
Top PとTemperatureは似ているように見えますが、Top Pは、次に生成されるトークンの候補範囲を限定し、Temperatureはトークンの生成確率の大きさを調整する役割を持ちます。
ここまでで[Settings]の設定が完了です。
テキスト生成
[Send a message]にプロンプトを入力して、[Chat]ボタンを押すと、テキストが生成されます。
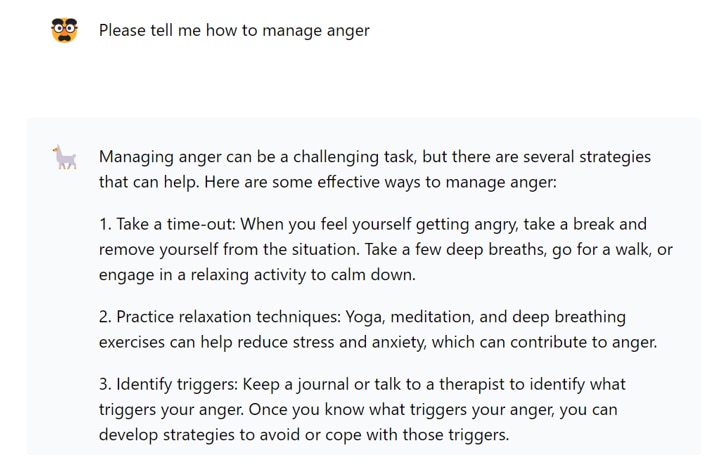
プロンプト
生成結果
日本語翻訳
生成AI・LLMならGPUクラウド
Llama2やその他のLLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Llama2をブラウザで使う方法について紹介しました。
Llama2は無料で使えて商用利用可能な利便性の高いモデルでありながら、ChatGPTと同等以上の性能があります。
Llama2に関する詳細な情報は、以下の記事でまとめて紹介していますので、あわせてご覧ください。



