

【Llama2】Text generation web UIのインストール・使い方
この記事では、Text generation web UIからLlama2の日本語モデルを使って、テキスト生成する方法を解説しています。
目次[非表示]
- 1.Text generation web UIとは
- 2.Llama2とは
- 3.実行環境
- 4.インスタンスに接続する際の注意
- 5.パッケージのインストール
- 6.リポジトリのクローン
- 7.Text generation web UIの起動
- 8.2回目以降の起動
- 9.モデルの設定
- 10.テキスト生成
- 11.生成AI・LLMならGPUクラウド
- 12.まとめ
Text generation web UIとは
Text generation web UI とは、言語生成AI(LLM)のモデルをGUIで使用できるツールです。
無料でインストールすることができ、Web UIの起動後は、コーディング不要でテキスト生成ができるようになります。

Llama2とは
Llama2(Large Language Model Meta AI 2/ラマツー)とは、Facebookを運営するMeta社が開発した言語生成AI(LLM)で、OpenAI社のChatGPTに匹敵するの性能を持っています。
Llama2の特徴としては、軽量モデルで高性能、そして無料で使えるオープンソースであるため、開発者にとって扱いやすいモデルになっています。
Llama2の詳細については、以下の記事で解説しています。
実行環境
この記事ではGPUクラウドサービス(GPUSOROBAN)を使用しました。
- インスタンス名:t80-1-a-exlarge-ubs22-h
- GPU:NVIDIA A100 80GB x 1
- OS :Ubuntu 22.04
- CUDA:11.7
GPUSOROBANはメガクラウドの50%以上安いGPUクラウドサービスです。
GPUSOROBANの使い方は以下の記事で解説しています。
インスタンスに接続する際の注意
Text generation web UIではポート7860を使用するため、インスタンス接続の際に以下のポートフォワードの設定が必要になりますのでご注意ください。
コマンドプロンプトからインスタンスに接続する場合
2つめに開いたコマンドプロンプトで以下のコマンドを実行します。
VSCodeからインスタンスに接続する場合
.ssh/configファイルに、[LocalForward 7860 localhost:7860]を含めます。
パッケージのインストール
以下のコマンドを実行し、パッケージをアップデートします。

必要なライブラリをインストールします。

リポジトリのクローン
Text generation web UIのリポジトリをインスタンスにクローンします。

Text generation web UIの起動
Text generation web UIを起動します。初回起動は、パッケージのインストールを伴うため時間がかかりますが、2回目以降はすぐに起動できます。

NVIDIAのGPUか問われるので、Aを入力して[Enter]を押します。
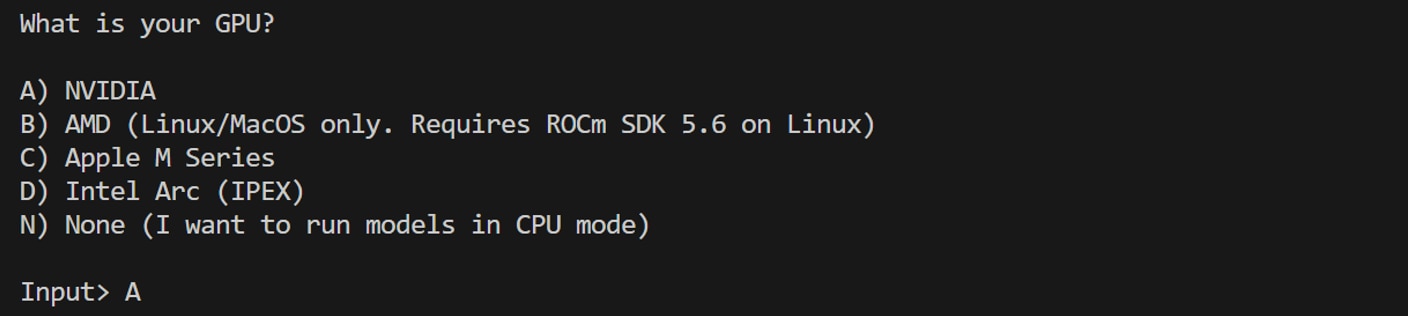
CUDA 11.8を利用するか問われますので、Yを入力して[Enter]を押します。

[Running on local URL: http://127.0.0.1:7860]の表示が完了したら、起動完了です。

Webブラウザの検索窓に”http://127.0.0.1:7860”を入力するとtext generation web UIの画面が表示されます。
2回目以降の起動
2回め以降の起動は、以下のコマンドを実行します。
モデルの設定
web UIでモデルを設定する手順は以下のとおりです。
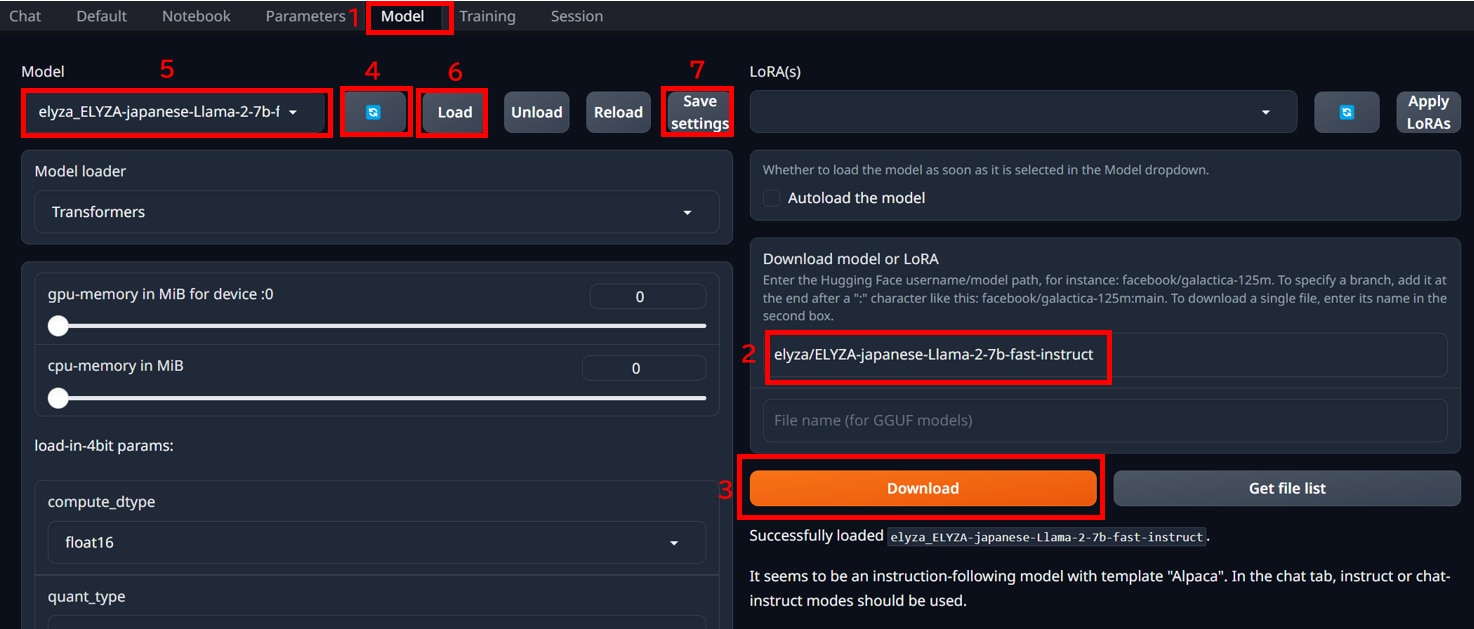
1.[Model]タブをクリックします。
2.[Download model or LoRA]にmodel_idを入力します。
この記事では、[elyza/ELYZA-japanese-Llama-2-7b-fast-instruct]をセットしました。
model_idはHuggigng Faceから探すことができます。
3.[Download]ボタンを押して、[Done!]の表示がでたらダウンロードが完了です。
4.[Model]の[更新]アイコンをクリックします。
5.[プルダウンメニュー]から[elyza/ELYZA-japanese-Llama-2-7b-fast-instruct]を選択します。
6.[Load]ボタンを押します。
7.[Save settings]ボタンを押します。
テキスト生成
web UIの[Chat]タブを開き、[テキストボックス]に”プロンプト”を入力し、[Gererate]ボタンをクリックします。
モデル「ELYZA-japanese-Llama-2-7b-fast-instruct」は、Llama2の日本語学習をしたモデルであるため、日本語での出力にも対応しています。
生成AI・LLMならGPUクラウド
Llama2やその他のLLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力や熱を管理をするための設備投資が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Text generation web UIからLlama2の日本語モデルを使って、テキスト生成する方法を紹介しました。
Text generation web UIは、無料でインストールすることができ、Web UIの起動後は、コーディング不要でテキスト生成ができるようになります。
Llama2に関する詳細な情報は、以下の記事でまとめて紹介していますので、あわせてご覧ください。



