

Stable Diffusion Web UIとは?使い方まとめ・ダウンロード方法 | 画像生成AI
この記事では、Stable Diffusion Web UI(AUTOMATIC1111版・Forge版)の概要から、あらゆる環境での使い方をまとめて紹介しています。
目次[非表示]
- 1.Stable Diffusionとは
- 2.Stable Diffusion Web UI(AUTOMATIC1111版・Forge版)とは
- 3.AUTOMATIC1111版とForge版の違い
- 4.Stable Diffusion WebUI(AUTOMATIC1111版・Forge版)のインストール
- 4.1.Windows(ローカルPC)にインストールする場合
- 4.2.Mac(ローカルPC)にインストールする場合
- 4.3.GPUクラウドサービスとは
- 4.4.Google Colabにインストールする場合
- 4.5.GPUクラウドサービス「GPUSOROBAN」にインストールする場合(Ubuntu)
- 5.txt2imgの使い方(テキストから画像生成する方法)
- 6.プロンプトの例・入れ方のコツ
- 7.img2imgの使い方(元画像+テキストから新しい画像を生成する方法)
- 8.モデルとは
- 9.モデルファイル(Checkpoint)の入れ方・使い方
- 10.追加学習モデルLoRAの使い方・作り方
- 11.Stable diffusion XI(SDXL)の使い方
- 12.VAEの入れ方・使い方
- 13.拡張機能の使い方
- 14.ControlNetの使い方
- 15.生成画像の表情のコントロール
- 16.Stable Diffusion Web UIの日本語化
- 17.バージョンをアップデート・ダウングレードする方法
- 18.Docker版Stable Diffusion Web UIを使う方法
- 19.Stable diffusion Onlineとは
- 20.著作権・商用利用・ライセンスについて
- 21.もっと自由な画像生成を
- 22.まとめ
Stable Diffusionとは
Stable Diffusionは、無料で使える画像生成AIです。テキストを打ち込むと、それに応じた画像が生成されるしくみです。人物や動物、風景など、さまざまな画像を生成できます。
例えば、「サングラスをかけた猫」と入力するとそのような画像が生成されます。生成する画像のスタイルも多様でイラストや写真、水彩画やアニメ調など、自分の好きなテーマでAIに生成してもらうことができます。

インストール不要でブラウザから簡単にStable Diffusionを使える「PICSOROBAN」
PCスペックを気にせず、簡単操作でStable Diffusionを利用できます。

今なら2,000ポイント分のPICSOROBANの画像生成をお試しいただけます。
Stable Diffusion Web UI(AUTOMATIC1111版・Forge版)とは
Stable Diffusion Web UI(AUTOMATIC1111版・Forge版)は、ブラウザを通じて手軽に画像生成を行える無料のWEBアプリケーションで、Google Chromeなどの主要なブラウザで利用できます。
プログラミングを一切必要とせず、WEB UIによる簡単なグラフィカルな操作が可能です。
AUTOMATIC1111版とForge版の違い
Stable Diffusion Web UI(Forge版)は、Stable Diffusion Web UI(AUTOMATIC1111版)と類似したWeb UIになります。 AUTOMATIC 1111版と比較して、Forge版はVRAMを節約でき、画像生成の速度が向上しています。
Forge版はAUTOMATIC1111版とほぼ同じ画面(WebUI)になりますので、AUTOMATIC1111と同じ操作感で利用できます。
Forge版に比べて歴史が長く、ドキュメントが豊富なAUTOMATIC1111版の方が、現時点では安定して使いやすいと思います。
一方でVRAM・GPUメモリの不足でお困り場合は、Forge版をおすすめしています。VRAMが6GB~8GBの場合は、Forge版の効果が見られますが、それ以上のVRAMを使用している場合は、目立った効果を感じられませんので、ご注意ください。
Stable Diffusion WebUI(AUTOMATIC1111版・Forge版)のインストール
Stable Diffusion Web UIの使い方として、ローカルPCにインストールする方法、もしくはクラウドサーバーにインストールする方法があります。
Stable DiffusionをローカルPCで使用する場合、ハイスペックなGPUを搭載したPCを用意する必要があります。画像生成AIは、膨大な計算を行います。その計算処理を担うのが主にGPUになります。
ハイスペックなGPUを搭載したPCでは、1枚の画像生成が1~2秒で完了します。GPUなしのPCでもStable Diffusionを動かすことができますが、1枚の画像生成に7分ほど時間がかかるので、実用的ではありません。
ハイスペックなPCの購入や運用面でハードルを感じる方は、インストール不要でブラウザから簡単に使える「PICSOROBAN」がおすすめです。
Windows(ローカルPC)にインストールする場合
Windows PCにStable Diffusion WebUIをインストールする場合の推奨スペックは次のとおりです。
- CPU:6コア以上
- メモリ(RAM):最低16GB 推奨32GB以上
- GPUメモリ(VRAM): 最低8GB 推奨16GB以上 ※Macの場合は最低M1チップ以上
- ストレージ(SSD):512GB以上
- OS:Windows
GPUメモリは16GB以上を推奨しています。Stable Diffusionは次々にバージョンが更新されていますが、SDXLモデルなど高画質化が進みGPUメモリの消費量が増える傾向になっています。PCを買う場合は後の増設することが難しいので、余裕を持ったGPU選択を推奨します。
Windows PCにStable Diffusion WebUI(AUTOMATIC1111版)をインストールする方法について、以下の記事で解説しています。
Windows PCに Stable Diffusion WebUI(Forge版)をインストールする方法は、以下の記事で詳しく解説しています。
Mac(ローカルPC)にインストールする場合
MacにStable Diffusion WebUIをインストールする場合の推奨スペックは次のとおりです。
- CPU:6コア以上
- メモリ(RAM):最低16GB 推奨32GB以上
- GPUメモリ(VRAM): M1チップ以上
- ストレージ(SSD):512GB以上
- OS:macOS
ローカルPC(Mac)にStable Diffusion WebUI(AUTOMATIC1111版)をインストールする方法について、以下の記事で解説しています。
ローカルPC(Mac)にStable Diffusion WebUI(Forge版)をインストールする方法について、以下の記事で解説しています。
GPUクラウドサービスとは
ハイスペックなPCの購入や運用面でハードルを感じる方は、GPUクラウドサービスがおすすめです。
GPU搭載のサーバーをクラウドで利用できるため、ハイスペックなPCを購入する必要はありません。PCを購入してしまうと後からスペックを上げることが難しいですが、クラウドサーバーであれば、時間単位で借りられて、スペックの変更も簡単です。
インターネット環境さえあれば、ローカルPCは低スペックでも問題なく、Wiidows・MacのどちらのPCからでも接続して利用できます。
GPUクラウドサービスでは、以下のようなサービスが提供されています。
- Google Colab
- GPUSOROBAN
- Amazon Web Service(AWS)
- Microsoft Azure(Azure)
- Google Cloud Platform(GCP)
Google Colabにインストールする場合
Google Colabratory(Colab)とは、Googleが提供しているブラウザからJupyter note book形式でPythonを実行できるサービスです。ColabにStable Diffusion Web UIをインストールして実行することができます。
Colabは一般的なクラウドサービスと異なり、あくまでも一時的に使うための簡易的なサービスなので、設定したモデルや拡張機能、生成した画像データを長時間に保存できなかったり、GPU使用量に限りがあるなど多くの制限がありますのでご注意ください。
Colabの制限には次のようなものがあります。
- 無料版のColabでStable Diffusion Web UIを使用するとColabの規約違反により警告がでて、BANされる可能性がある。
- 有料版のColab ProでStable Diffusion Web UIは使用できるが、GPUの使用時間が限定されている(コンピューティングユニットによる制限)
- 再起動もしくはセッションが切れによって、ランタイムがリセットされると、Colabに保存したモデル・拡張機能・画像データは全て削除される。Stable Diffusion Web UI側で設定した内容もリセットされるため、モデルや拡張機能の再インストールに時間がかかる
ColabにStable Diffusion WebUI(AUTOMATIC1111版)をインストールする方法について、以下の記事で解説しています。
ColabにStable Diffusion WebUI(Forge版)をインストールする方法について、以下の記事で解説しています。
GPUクラウドサービス「GPUSOROBAN」にインストールする場合(Ubuntu)
GPUSOROBANは、1時間50円から使える業界最安級のGPUクラウドサービスです。
AWSやGCP、AzureのGPUクラウドと比較して50%~70%安い料金で、ハイスペックなNVIDIA GPUが使えます。
Google ColabのようにGPU使用量の制限やランタイムリセット時にデータが削除される制限がありません。
GPUに特化したシンプルなサービスで、クラウドサーバー(インスタンス)の設定は3分程度で完了します。データ転送料やストレージコストもインスタンス利用料に含まれており、明瞭な料金体系になります。国内最上位のNVIDIAエリートパートナーに認定され、日本人による技術サポートも無料で受けられます。
GPUクラウドサービス「GPUSOROBAN」にStable Diffusion Web UI(AUTOMATIC1111版)をインストールする方法について、以下の記事で解説しています。
Stable Diffusion WebUI(Forge版)をGPUSOROBANにインストールする方法は、以下の記事で詳しく解説しています。
txt2imgの使い方(テキストから画像生成する方法)
Stable Diffusion Web UIの「txt2img」は、テキストをインプットして画像を生成する機能です。
入力するテキストのことをプロンプト(呪文)と呼びます。プロンプトは、生成したい画像の内容をテキストで指示するためのものです。逆に生成したくない要素は、ネガティブプロンプトにテキストを打ち込んで指示ができます。
試しにtxt2imgで画像生成をしてみましょう。
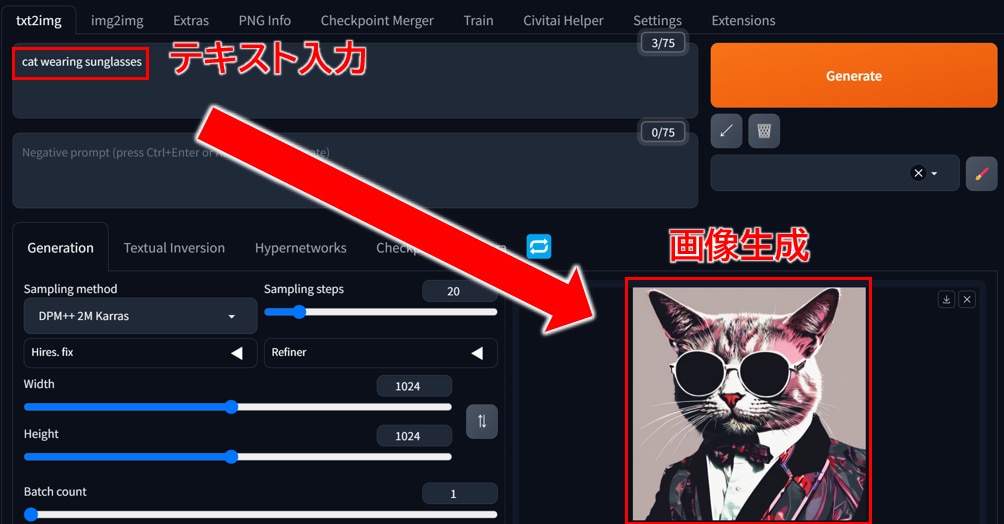
[txt2img]タブを開き、[Prompt]に"cat wearing sunglasses"というテキストを入力します。
ネガティブプロンプトに"missing face"を追記して、[Generate]ボタンをクリックすると、プロンプトのとおりに「サングラスをかけた猫」の画像が表示されます。
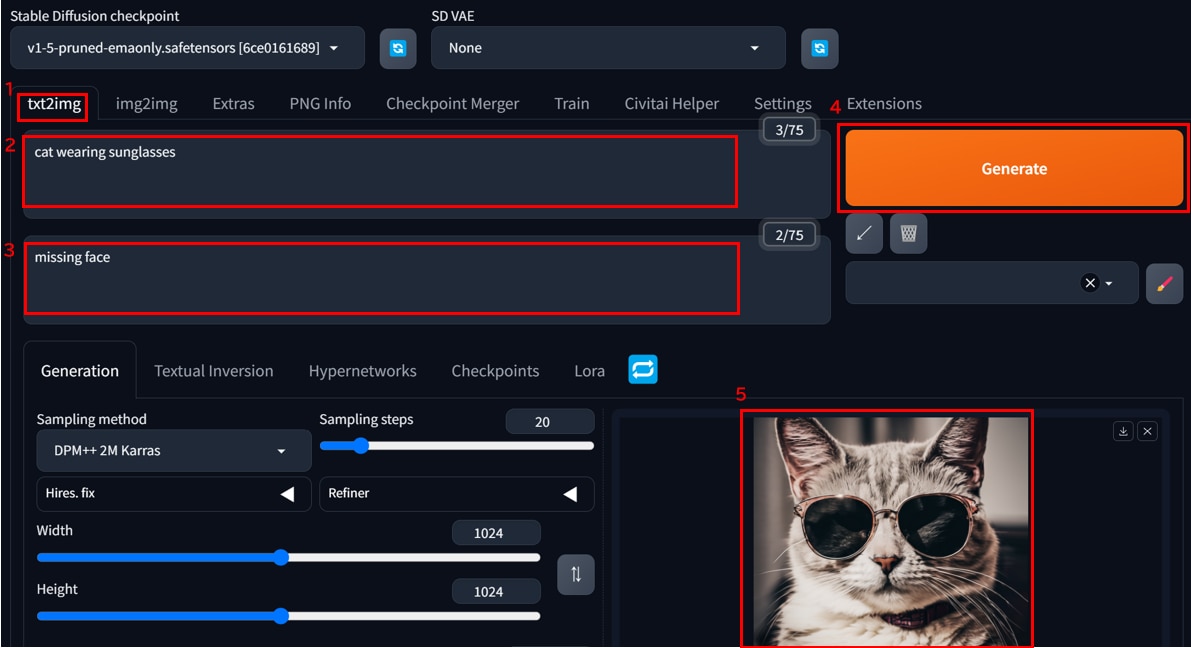
ネガティブプロンプトに入力した”missing face”では、顔が見切れないようにテキストで制御をかけています。
プロンプトの例・入れ方のコツ
テキストで生成する画像を指示するプロンプトについて、基本的な仕様やポイントについて説明します。
基本的な仕様は以下のとおりです。
- プロンプトは英語で記述します。
- プロンプトは文章形式でも、カンマ区切りの単語の羅列でもOKです。
- 順番が前の方のプロンプトのほうが画像生成への影響が強くなります。
- (テキスト)のように丸括弧をつけると、そのテキストの影響が強くなります。
(代表的なプロンプト)
プロンプトの種類 | プロンプト例 | 効果 |
画質 | best quality, 8k,masterpiece | 画質を指定する |
画風 | photo,painting,watercoloer | 画風を指定する(写真、絵、水彩画など) |
構図 | close up, from above | 構図を指定する(顔中心に写す、上から写すなど) |
被写体の数 | 1cat,1woman | 被写体の数を指定する |
容姿 | coat,tall,short hair | 服装や体型、髪型などの容姿を指定する |
ポーズ | standing,sit,hands up | ポーズを指定する |
背景 | room, cafe, no background | 背景を指定する |
(代表的なネガティブプロンプト)
ネガティブ プロンプトの種類 | ネガティブプロンプト例 | 効果 |
低品質防止 | low quality,worst quality | 低品質を防ぐ |
変形防止 | bad ears,bad mouth,bad eyes | パーツの変形を防ぐ |
文字除外 | text,signature,stamp | 画像に文字が入ること防ぐ |
画風除外 | painting,sketches,watercolor | 特定の画風になることを防ぐ |
被写体の数除外 | two shot | 被写体が2つになることを防ぐ |
(プロンプトの例)
4k,photo,close up, 1cat,wearing sunglasses,room
(ネガティブプロンプトの例)
worst auality,low quality,bad ears,text,painting,sketches,watercolor,two shot
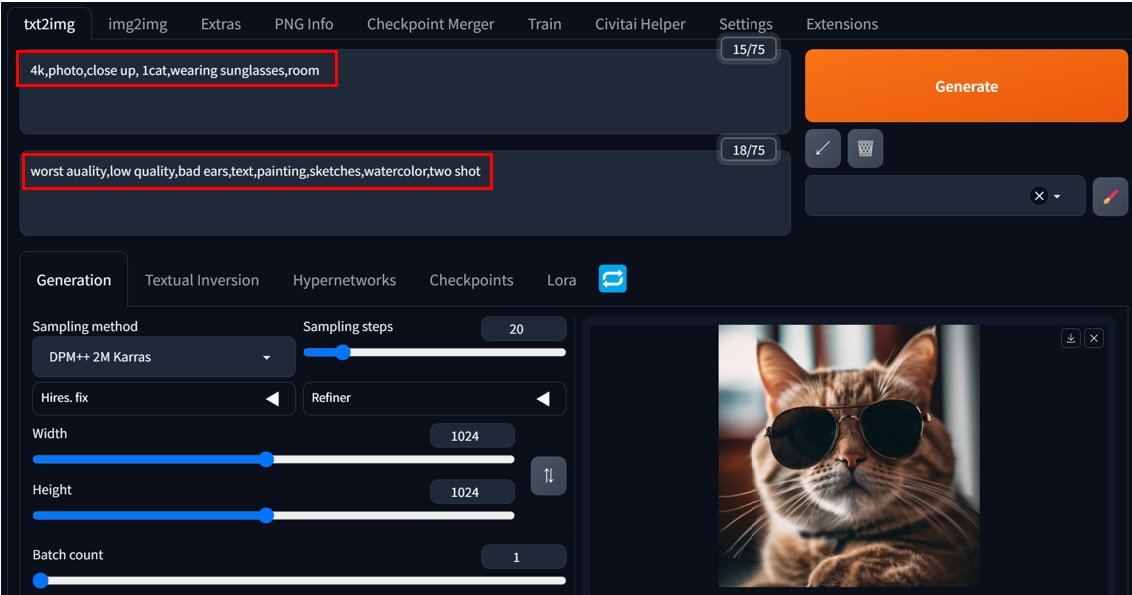
プロンプトの使い方、プロンプトの一覧は以下の記事で詳しく解説しています。
img2imgの使い方(元画像+テキストから新しい画像を生成する方法)
Stable Diffusionでの画像生成には、txt2imgが主に使われています。しかしテキストをベースにしているため、思い通りの画像を作ることが難しい場合があります。そんな悩みを解決してくれるのが、「img2img」です。
img2imgでは、元画像をベースに新しいイラストを生成するため、より細かなニュアンスを反映させることができ、より理想に近いイラストを作成することができます。
img2imgの使い方は以下のとおりです。
[img2img]タブを開きます。
[Generation]>[img2img]にベースとなる元画像をドラッグ&ドロップでアップロードします。
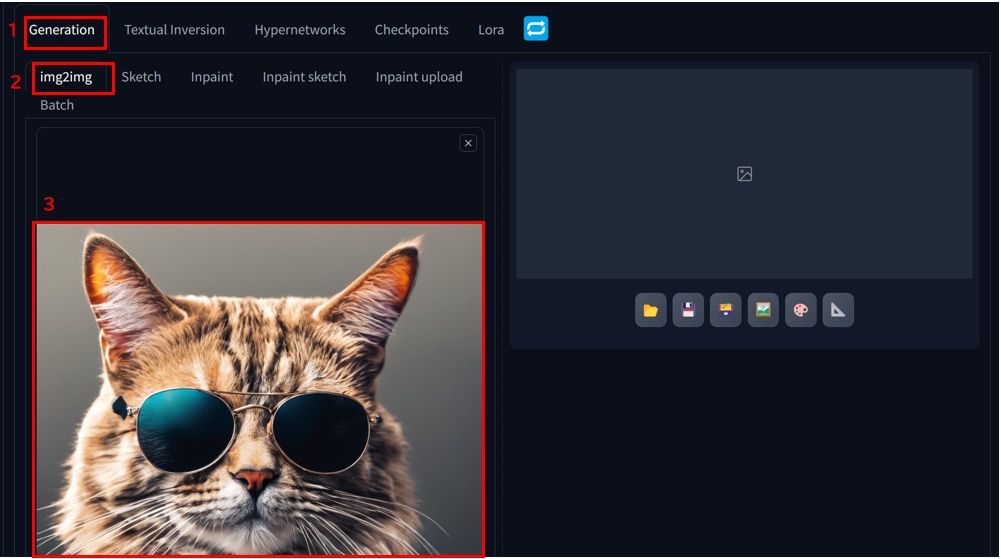
[Prompt]に”cartton”と入力し、[Generate]ボタンをクリックします。
ベース画像の要素を含んだアニメ風の猫の画像が生成されました。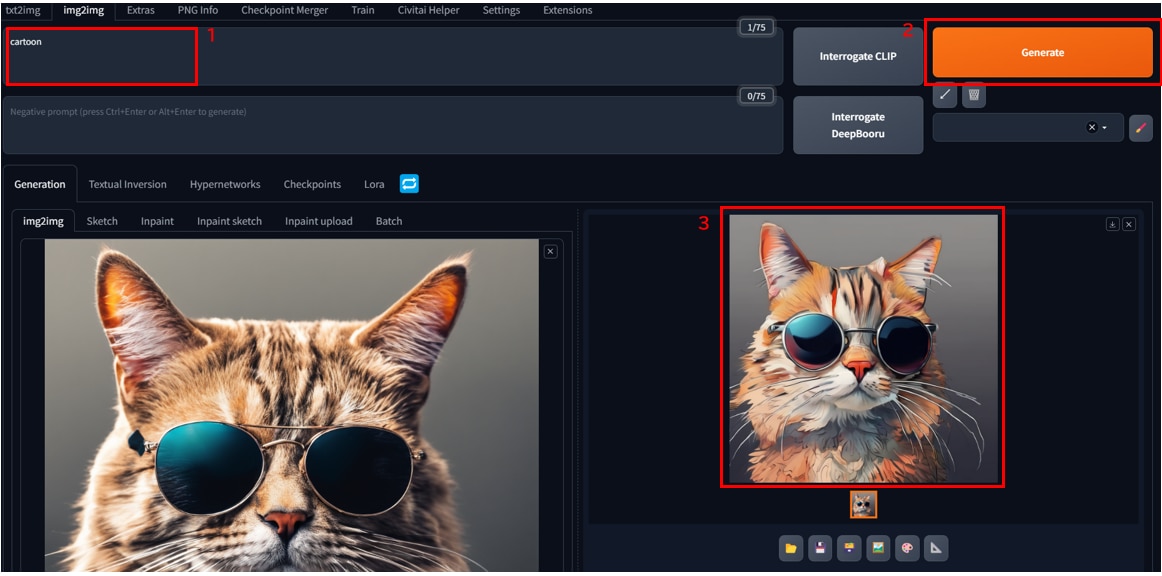
このようにimg2imgは、自分のイメージに寄せて画像を生成したい場合に便利です。
img2imgの詳しい使い方は、以下の記事で詳しく解説しています。
モデルとは
Stable Diffusion Web UI ではあらかじめ設定したモデルのもと、プロンプトに合わせて画像が生成されます。モデルによって実写風や、アニメ調、油絵など様々な特徴があり、生成される画像の雰囲気やスタイル、画風に影響します。生成したい画像に近いモデルを使うことで、想定したイメージに近い画像を生成することができます。

モデルファイル(Checkpoint)の入れ方・使い方
Stable Diffusion Web UIでモデルを使用するには、「Checkpoint」と呼ばれるモデルファイルを設定する必要があります。
モデルファイルはHugging FaceやCivitaiで配布されており、無料でダウンロードできます。
Stable Diffusion WebUIをインストールしたPCにモデルファイルを格納したら、モデルが使えるようになります。
モデルファイル(Checkpoint)の詳しい使い方は以下の記事で解説しています。
実写・アニメ系モデルのおすすめを以下の記事で紹介しています。
追加学習モデルLoRAの使い方・作り方
「LoRA」とは追加学習モデルのことを指し、使い方はモデル「Checkpoint」に近いです。
モデル「Checkpoint」と追加学習モデル「LoRA」の違いは何でしょうか?
Checkpointは、モデルファイルの本体になります。一方LoRAは、追加学習ファイルと呼ばれ、モデルファイル(Checkpoint)に対して追加学習を行った差分ファイルになります。
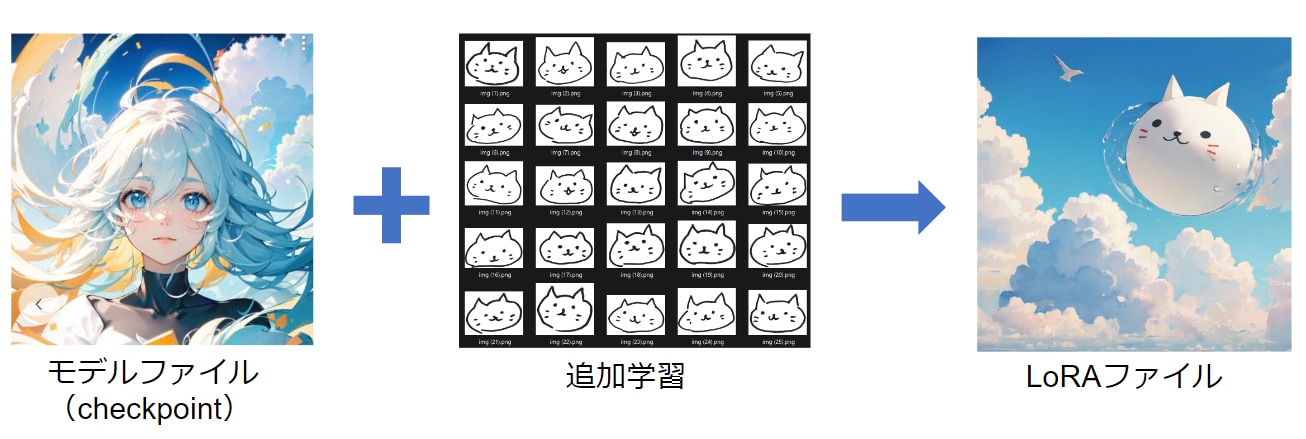
Checkpointがモデルの本体だとすると、LoRAはパーツのような役割で、背景のLoRA、髪型のLoRA、服装のLoRAなど、複数のLoRAを1つのCheckpointに対して適用することができます。
LoRAの設定方法は、モデルファイルとほぼ同じです。
LoRAファイルをCivitaiもしくはHugging Faceからダウンロードし、Stable Diffusion WebUIをインストールしたPCにLoRAファイルを格納したら、LoRAが使えるようになります。
LoRAの詳しい使い方は以下の記事で解説しています。
また既存のLoRAファイルを使うだけでなく、画像データを追加学習させてオリジナルのLoRAファイルを作ることもできます。
LoRAの学習では、計算量が比較的少なく済むため、20枚ほどの画像データで学習することが可能です。
オリジナルのLoRAの作り方は以下の記事で解説しています。
Stable diffusion XI(SDXL)の使い方
Stable Diffusion XL(SDXL)とは、Stability AI社が開発したStable Diffusionの最新版のモデルです。SDXLは従来のStable Diffusionに比べて、高解像度の画像生成が可能になりました。

SDXLの特徴は以下のとおりです。
- BaseモデルとRefinerモデルの2段階の画像処理を行い高画質な画像を生成できる
- 幅広いスタイルの画像を生成できる
- コントラストや影などが改善されて鮮やかな描写ができる
- 指や文字などをきれいに生成できる
Stable Diffusion XLの詳しい使い方は以下の記事で解説しています。
VAEの入れ方・使い方
VAEは、高次元の画像を低次元の潜在表現(ベクトル)に変換して、その後再び高次元の画像に変換するしくみです。画像生成AIでは非常に多くの計算をします。
高次元の画像をそのまま計算すると処理の量が多すぎて時間がかかるので、低次元の潜在空間(ベクトル)という形に変換をして、データサイズを圧縮し計算量を減らして処理をします。その後、潜在表現(ベクトル)から高次元の画像に戻して出力します。
Stable Diffusion Web UIで使われるVAEは、画像を鮮明にする効果があります。VAEを導入すると同じプロンプトでも画質が良くなり、モヤがかかったような、あるいは輪郭が少しぼやけたような画像を鮮明にしてくれます。

VAEの詳しい使い方は以下の記事で解説しています。
拡張機能の使い方
拡張機能(Extension)とは、Stable Diffusion WebUIに追加する便利機能のことです。拡張機能を使って便利な機能を追加していくことで、画像生成を効率化したり、クオリティを向上することができます。
代表的な拡張機能の一つにControlNetというものがありますが、キャラクターのポーズや構図を自由に調整することができます。プロンプトによる指定では、思っていたポーズと違う画像が生成されることもあります。
ControlNetの拡張機能を使うことで、参考画像のポーズと類似した画像を生成することができます。写真やイラスト、手書きの絵からポーズや輪郭を型取りして、指定できるため、かなり厳密に参考画像のポーズを再現することが可能です。
拡張機能の詳しい使い方は下記の記事で解説しています。
ControlNetの使い方
ControlNetはStable Diffusionの拡張機能の一つで、キャラクターのポーズや輪郭を参考画像から指定できる機能です。
プロンプトによる指定では、思っていたポーズと違う画像が生成されることもあります。
ControlNetの拡張機能を使うことで、参考画像のポーズと類似した画像を生成することができます。
写真やイラスト、手書きの絵からポーズや輪郭を型取りして、指定できるため、かなり厳密に参考画像のポーズを再現することが可能です。

ControlNetの詳しい使い方は、以下の記事で解説しています。
生成画像の表情のコントロール
生成する画像の表情をコントロールする方法について、以下の記事で紹介しています。
Stable Diffusion Web UIの日本語化
Stable Diffusion Web UIを日本語化する手順は以下のとおりです。
- [Extension]タブを開きます。
- [Available]タブを開きます。
- [localization]タブからチェックを外します。
- [Load form]ボタンをクリックします。
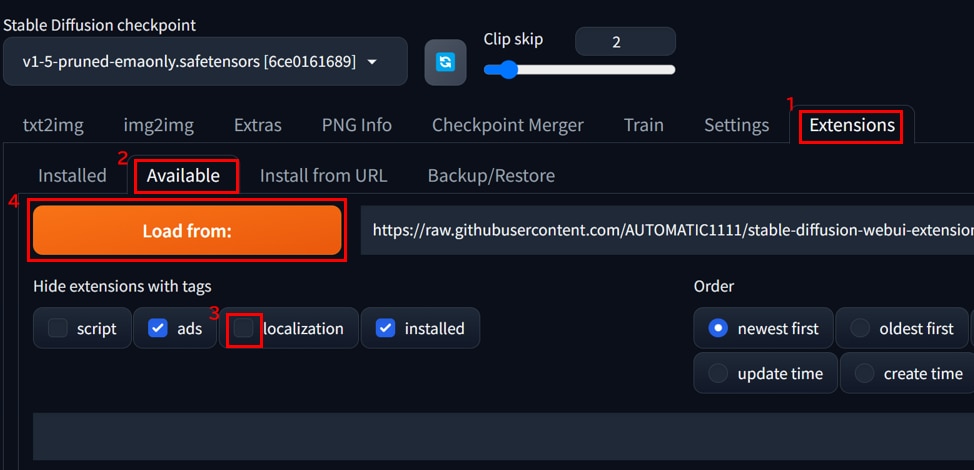
リストに[jp_JP Localization]と表示されるので、[Install]ボタンを押します。
[Setting]タブを開きます。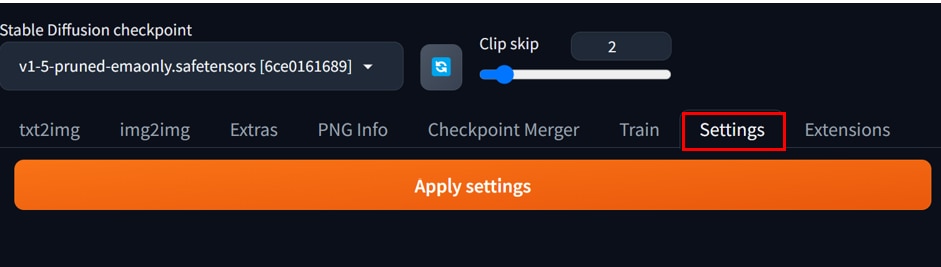
サイドバーから[User interface]をクリックします。
[Localization]の欄で、[更新]アイコンをクリックし、その後[プルダウンメニュー]から[ja_JP]を選択します。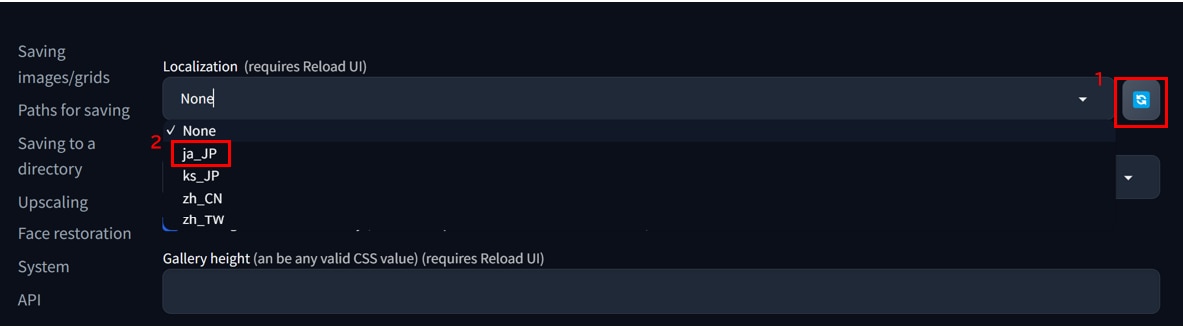
[Apply setting]ボタンを押した後、[Reload UI]ボタンを押すとUIに日本語設定が反映されます。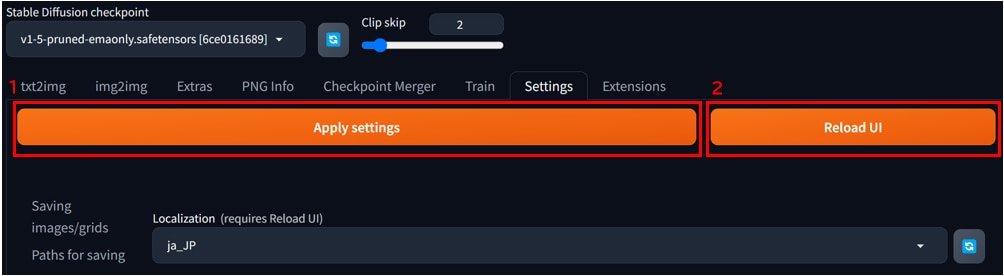
以上で日本語設定が完了です。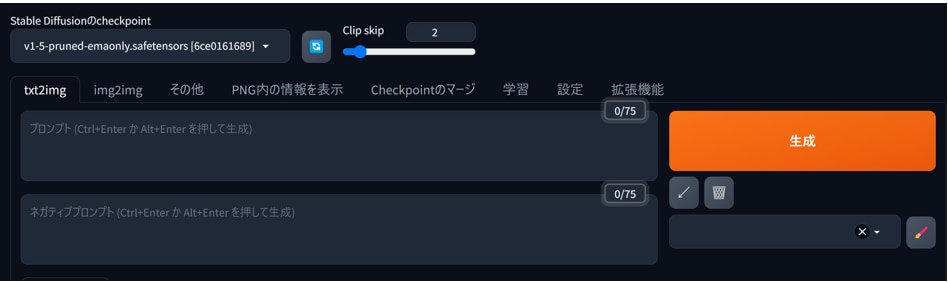
バージョンをアップデート・ダウングレードする方法
Stable Diffusion WebUIは、アップデートが頻繁に行われ、新しいバージョンが次々に提供されています。新しいバージョンでは新機能が追加されているため、基本的にはアップデートをしていくことを推奨します。
ただし、新しすぎるバージョンではバグが発生しやすかったり、拡張機能やモデルとのバージョンがマッチしないこともありますので、状況に応じてバージョンを合わせることも必要になります。
Stable Diffusion Web UIのバージョンをアップデート・ダウングレードする方法は以下の記事で解説しています。
Docker版Stable Diffusion Web UIを使う方法
Dockerとは、コンテナ仮想化を用いたアプリケーションの実行環境です。
Dockerを使うことで環境構築の手間を削減することができ、環境の持ち運びが簡単になります。
Docker版Stable Diffusion Web UIの使い方は、以下の記事で解説しています。
Stable diffusion Onlineとは
Stable DiffusionをWEBブラウザで利用できる無料のサービスです。Stable Diffusionの画像生成を体験する簡易的なサービスです。
Stable Diffusion Onlineはデモ用のサイトのようなもので、画像生成に非常に長い時間がかかります。実用的に画像生成をしたい場合は、この記事で紹介したStable Diffusion Web UI(AUTOMATIC1111)を使うことをおすすめします。
Stable Diffusion Onlinkeの使い方は以下の記事で解説しています。
著作権・商用利用・ライセンスについて
Stable Diffusionで生成した画像の商用利用は基本的に可能とされています。
Stable Diffusionでは生成された画像について権利を主張しないと公式に発表しており、プライバシーに関わる情報や、誤情報を広めるなど、人に危害を与えるような場合を除いて、生成した画像を商用利用することが認められています。
ライセンスに「CreativeML Open RAIL-M」と表示されているものであれば、基本的に利用可能のようです。
CreativeML Open RAIL-Mのライセンス規約は以下のページに記載されています。
ライセンス規約を要点すると以下の通りになります。
許可:クレジット表記なしでこのモデルを使用する
許可:このモデルで生成された画像を商用利用する
許可:商用画像生成サービスにこのモデルを使用する
許可:このモデルを使用したマージモデルを共有する
禁止:このモデルおよびマージモデルを販売する
禁止:このモデルのマージモデルに異なる権限を設定する
モデルそれぞれにライセンスがあり、CivitaiやHuggingFaceのモデルのページに記載がありますので、モデルの使用前に確認するようにしましょう。
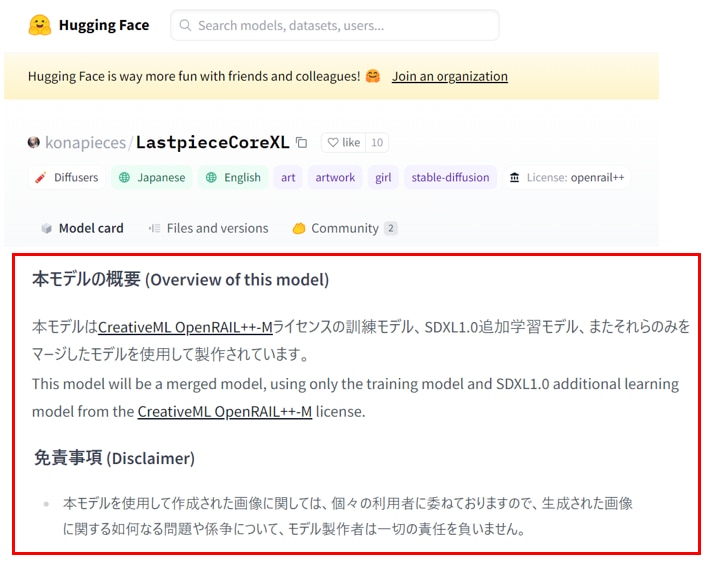
Hugging Faceでのライセンス・注意事項の例
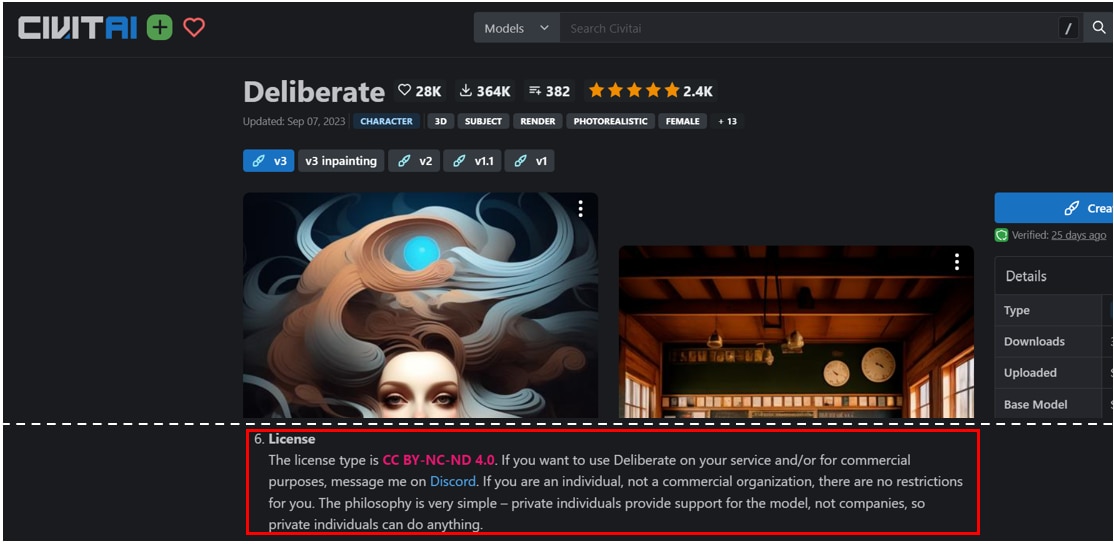
Civitaiでのライセンス・注意事項の例
もっと自由な画像生成を
Stable Diffusionで、以下のような悩みをお持ちではありませんか?
- インストールするのが面倒
画像生成が遅い
- GPUメモリ(VRAM)が足りない
ソフトウェアの更新や管理が手間
高速かつ格安に画像生成がしたいなら、インストール不要でブラウザで使える「PICSOROBAN」がおすすめです!
今なら約2時間分無料でPICSOROBANの画像生成をお試しいただけます。
まとめ
この記事では、Stable Diffusion Web UIの使い方を紹介しました。Stable Diffusion Web UIは、無料のソフトウェアでありながら、カスタマイズ性が高く、モデルや拡張機能の組み合わせによって、高度な画像生成が可能になります。
Stable Diffusion Web UIに関する記事は、以下のページにまとめていますので、併せてご覧ください。



