

【Stable Diffusion Web UI】LoRAに追加学習する方法 | オリジナルLoRAの作り方
この記事では、Stable Diffusion WebUI(AUTOMATIC1111版・Forge版)において、追加学習をしてLoRAファイルを自作する方法を紹介しています。
30枚程度の画像を追加学習して、オリジナルのLoRAファイルを作成します。
目次[非表示]
- 1.Stable Diffusionとは
- 2.Stable Diffusion Web UI(AUTOMATIC1111版・Forge版)の使い方
- 3.LoRAとは
- 4.推奨環境
- 5.LoRAの学習方法
- 6.LoRA学習の環境構築
- 7.ファイルを格納するディレクトリの準備
- 8.LoRA学習に使用する教師データの準備
- 9.sd-scriptsのインストール
- 9.1.venv環境の作成
- 9.2.リポジトリ・ライブラリの準備
- 9.3.accelerate configの設定
- 10.stable-diffusion-webui-wd14-taggerのインストール
- 11.キャプションの作成・編集
- 12.datasetconfigファイルを作成する
- 13.Accelerateファイルを作成する
- 14.学習の実行
- 15.insufficient shared memory(shm)のエラーが出る場合
- 16.動作確認
- 17.もっと自由な画像生成を
- 18.まとめ
Stable Diffusionとは
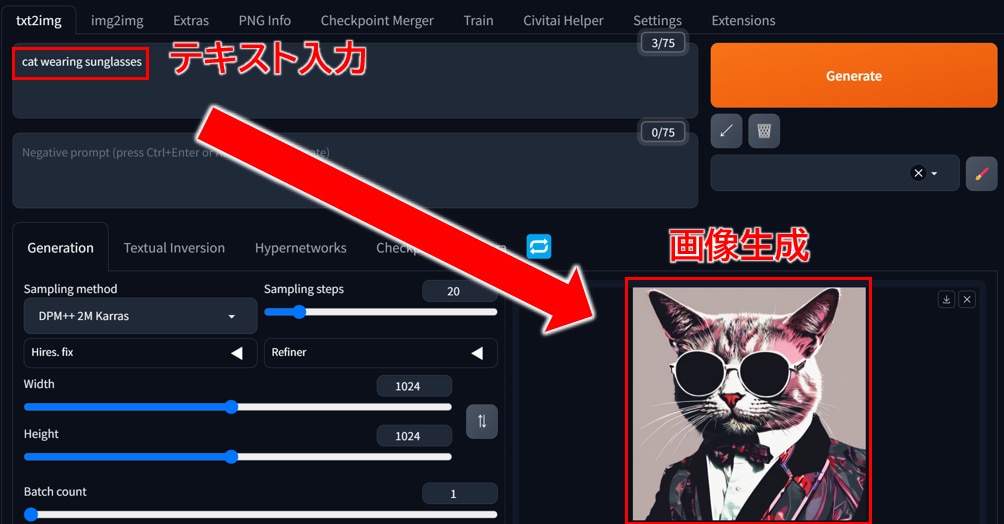
Stable Diffusionは、無料で使える画像生成AIです。テキストを打ち込むと、それに応じた画像が生成されるしくみです。人物や動物、風景など、さまざまな画像を生成できます。
例えば、「サングラスをかけた猫」と入力するとそのような画像が生成されます。生成する画像のスタイルも多様でイラストや写真、水彩画やアニメ調など、自分の好きなテーマでAIに生成してもらうことができます。

Stable Diffusion Web UI(AUTOMATIC1111版・Forge版)の使い方
Stable Diffusion Web UI(AUTOMATIC1111)は、ブラウザを通じて手軽に画像生成を行える無料のWEBアプリケーションで、Google Chromeなどの主要なブラウザで利用できます。
プログラミングを一切必要とせず、WEB UIによる簡単なグラフィカルな操作が可能です。Stable Diffusion Web UIをローカルPCにインストールして使用する、もしくはクラウドサーバーにインストールして使用します。
Stable Diffusion Web UI(AUTOMATIC1111版・Forge版)に関する全般的な使い方については、以下の記事でまとめていますので、あわせてご覧ください。
LoRAとは
Stable Diffusion Web UIのモデルにおいて「Checkpoint」と「LoRA」という似たような概念が使われます。
Checkpointは、モデルファイルの本体になります。一方のLoRAは追加学習ファイルと呼び、モデルファイル(Checkpoint)に対して追加学習を行った差分ファイルになります。差分を学習するためLoRAは非常に少ない計算量で作成できます。
Checkpointがモデルの本体だとすると、LoRAはパーツのような役割で、背景のLoRA、髪型のLoRA、服装のLoRAなど、複数のLoRAを1つのCheckpointに対して適用することができます。
CheckpointとLoRAはセットで使用するため、組み合わせを事前に把握しておく必要があります。
この記事ではモデルファイル(Checkpoint)に30枚の画像を追加学習して、LoRAファイルを作成します。
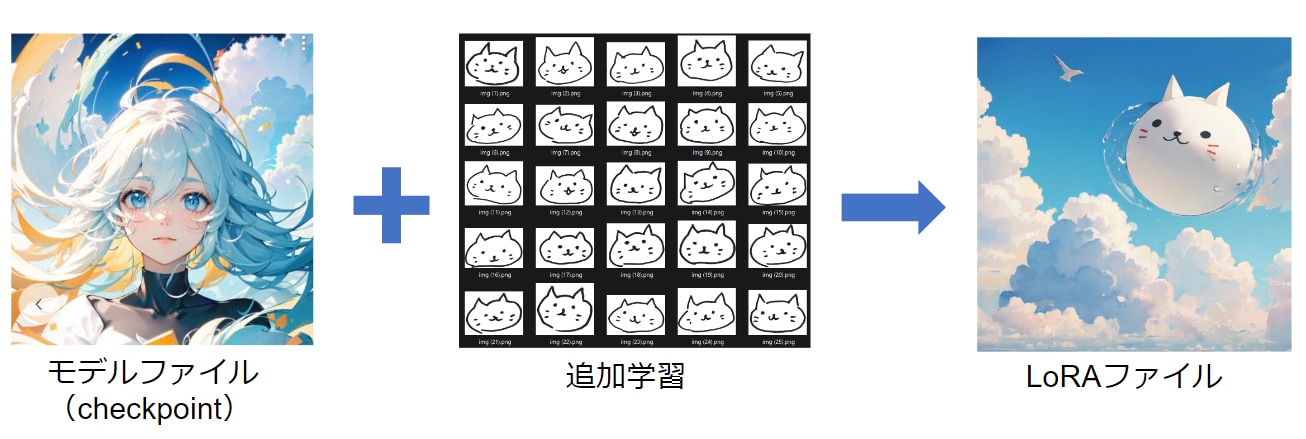
モデルファイルは、Ether Blu Mixというアニメ風のモデルファイルを使用しています。
モデルファイル(Checkpoint)の使い方は以下の記事で解説しています。
追加学習をせずに既存のLoRAファイルをそのまま使う方法は、以下の記事で解説しています。
推奨環境
LoRAの学習には多くの計算をするため、GPUメモリ(VRAM)が必要になります。
GPUメモリ(VRAM)16GB以上が推奨です。
この記事ではGPUSOROBANのA4000を搭載したインスタンスを使用します。
さらに学習速度を上げたい場合は、GPUメモリの大きいA100を搭載したインスタンスがおすすめです。
GPUSOROBANは、GPUサーバーをクラウドで使えるサービスです。
ローカルPCのスペックが低くても、クラウドに接続することで高性能なGPUを利用できます。
1時間50円からの業界最安級のコストで利用でき、構築した環境や画像データをクラウドに保存できます。
GPUSOROBANの詳しい情報は公式サイトをご覧ください。
LoRAの学習方法
LoRAを作成する方法は以下の3通りありますが、この記事ではDreamBooth(キャプション)方式を使います。
- DreamBooth(キャプション)
- DreamBooth(class+identifer)
- ファインチューン
DreamBooth(キャプション)の方式では、学習に「画像」と「キャプション」を使用します。
キャプションとは、学習させたくない内容をキーワードで指定するファイルです。
キャプションを使って学習を制御をかけることで、意図した画像を生成するモデルが作りやすくなります。
LoRA学習の環境構築
ここではLoRAの学習をする環境構築について解説します。
はじめにGPUSOROBANのインスタンスを作成・起動し、Stable Diffusion Web UIをインストールします。
GPUSOROBANのインスタンス作成方法およびStable Diffusion Web UIのインストール方法は、以下の記事をご覧ください。
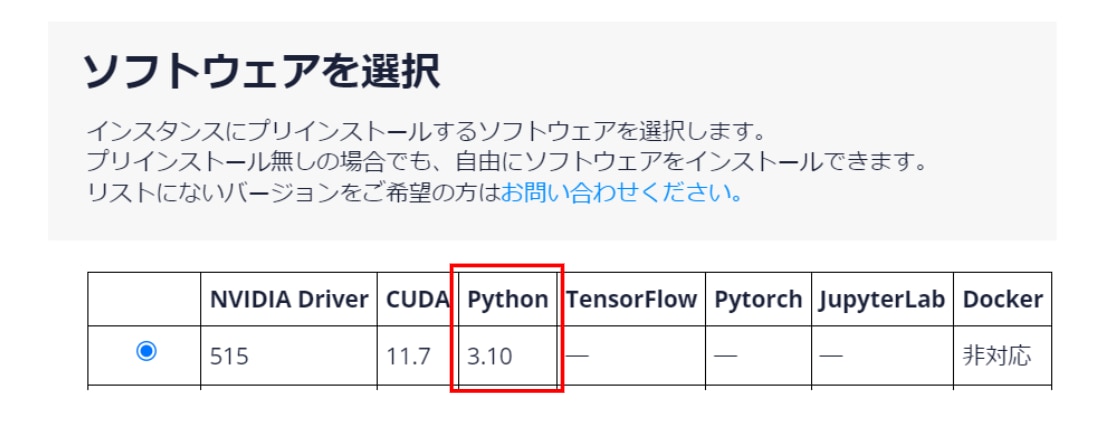
※インスタンス作成の際に[ソフトウェアの選択]でPython3.10を選択するようにしてください。
またLoRAの学習には、元になるモデルファイル(Checkpoint)が必要になりますので、あらかじめご用意ください。
モデルファイル(Checkpoint)の入手方法は以下の記事で解説しています。
ファイルを格納するディレクトリの準備
ホームディレクトリに移動します。
インスタンスに接続したら次のコマンドを実行して、LoRAの学習で使用するファイルの格納先を作成します。
![]()
次のコマンドを実行し、ディレクトリ階層が以下のようになっていることを確認します。

(ディレクトリ階層)
TrainingData
├── source_inputs
├── regular_inputs
└── raw_outputs
LoRA学習に使用する教師データの準備
LoRAで学習するための教師データを用意します。
教師データに使う画像の数は20枚以上を推奨しています。
学習に使う画像の数が多いほうがよいですが、多すぎると過学習になる問題もあります。
画像サイズは512x512以上、アスペクト比は1:1が推奨です。
この記事では手書きの画像を30枚ほど用意しました。

用意したファイルを、インスタンスのディレクトリにアップロードします。

インスタンスへのファイルのアップロード方法は以下の記事をご覧ください。
sd-scriptsのインストール
LoRA学習を行うためのパッケージ「sd-scripts」をインストールします。
venv環境の作成
Stable Diffusion Web UIをインストールしたvenv仮想環境に、sd-scriptsをインストールすると依存関係でエラーが起こりますので、必ずvenv仮想環境を切り替えてからsd-scriptsをインストールしてください。
venv仮想環境(base)から出ます。

venv仮想環境(lora)を新しく作成します。
![]()
作成したvenv仮想環境(lora)に入ります。

(lora)user@<インスタンス名>:~$のように括弧内の名称が変わったら、venv仮想環境の切り替えが完了です。
リポジトリ・ライブラリの準備
ホームディレクトリに移動します。
パッケージをアップデートします。

sd-scriptsのリポジトリを複製します。

sd-scriptsのディレクトリに移動します。

必要なライブラリをインストールします。

インストールしたソフトウェアの各種バージョン確認を行います。
Pythonを起動し、バージョンが3.10であることを確認します。

次のコマンドを実行し、torchのバージョンが1.13であることを確認します。

torch.cuda.is_available()のコマンドを実行し、Trueが返されるとPyTorchからGPUが適切に認識されています。

[Ctrl] + [D]コマンドでPythonのインタラクティブモードから抜けます。
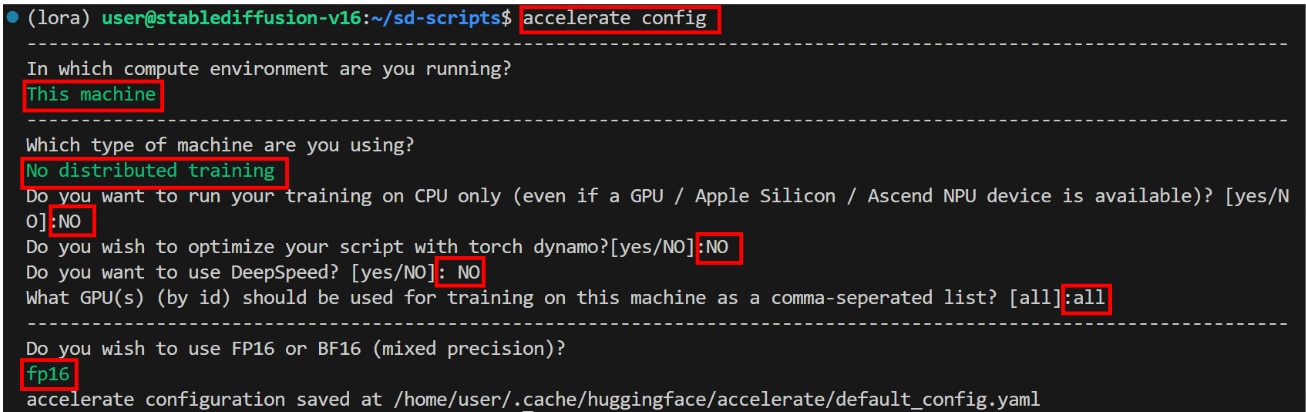
accelerate configの設定
ここではGPUの計算パラメーターのaccelerate configの設定をします。
ターミナルで次のコマンドを実行します。
以下の質問が開始されますので、カーソルキーで以下の項目を選び、Enterキーで次に進みます。
In which compute environment are you running?
Which type of machine are you using?
以下の質問がされますので、回答のとおりに[文字列]を入力し、[Enter]キーで次に進みます。
Do you want to run your training on CPU only (even if a GPU / Apple Silicon / Ascend NPU device is available)? [yes/NO]
Do you wish to optimize your script with torch dynamo?[yes/NO]
Do you want to use DeepSpeed? [yes/NO]
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list?
最後に以下の質問が表示されますので、カーソルキーで以下の項目を選び、Enterキーで次に進みます。
Do you wish to use FP16 or BF16 (mixed precision)?
ここまででsd-scriptsのインストールが完了です。
stable-diffusion-webui-wd14-taggerのインストール
LoRAで画像を学習する際に、学習させない内容をキーワードで定義するキャプションファイルを作成します。
画像の特徴をキーワードとして抽出するのは直感では難しいので、stable-diffusion-webui-wd14-taggerという拡張機能を使います。
この拡張機能により画像の特徴を表すキーワードを自動で生成できます。
次のコマンドを実行し、venv環境(base)に切り替えます。
※venv仮想環境を切り替えずにStable Diffusion Web UIを起動した場合、sd-scriptsで構築した環境が崩れる可能性がありますので、 必ずStable Diffusion Web UIをインストールしたときのvenv仮想環境に切り替えるようにしてください。

※baseの仮想環境がない場合は、以下のコマンドでbaseの仮想環境を新規作成した上で、base環境に切り替えてください。
stable-diffusion-webuiのディレクトリに移動し、Stable Diffusion Web UIを起動します。

[Extensions]タブ、[Install from URL]タブを開き、[URL for extention’s git repogitory]に以下のURLを貼り付けて、[Install]ボタンをクリックします。
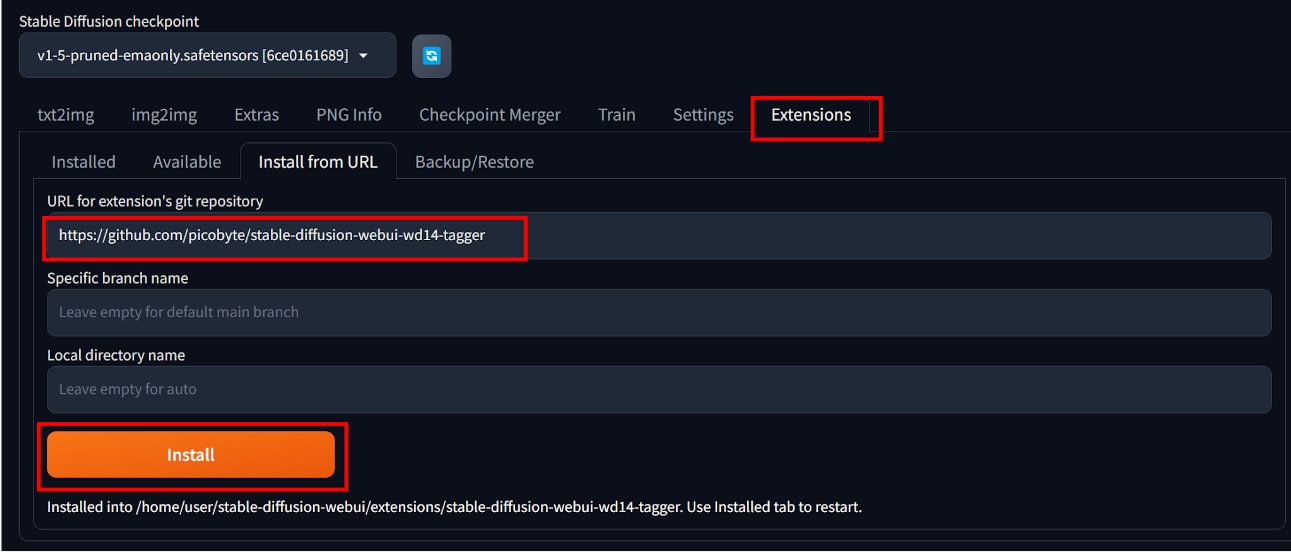
[Installed]タブを開き、[Apply and restard UI]ボタンをクリックし、Web UIを更新します。
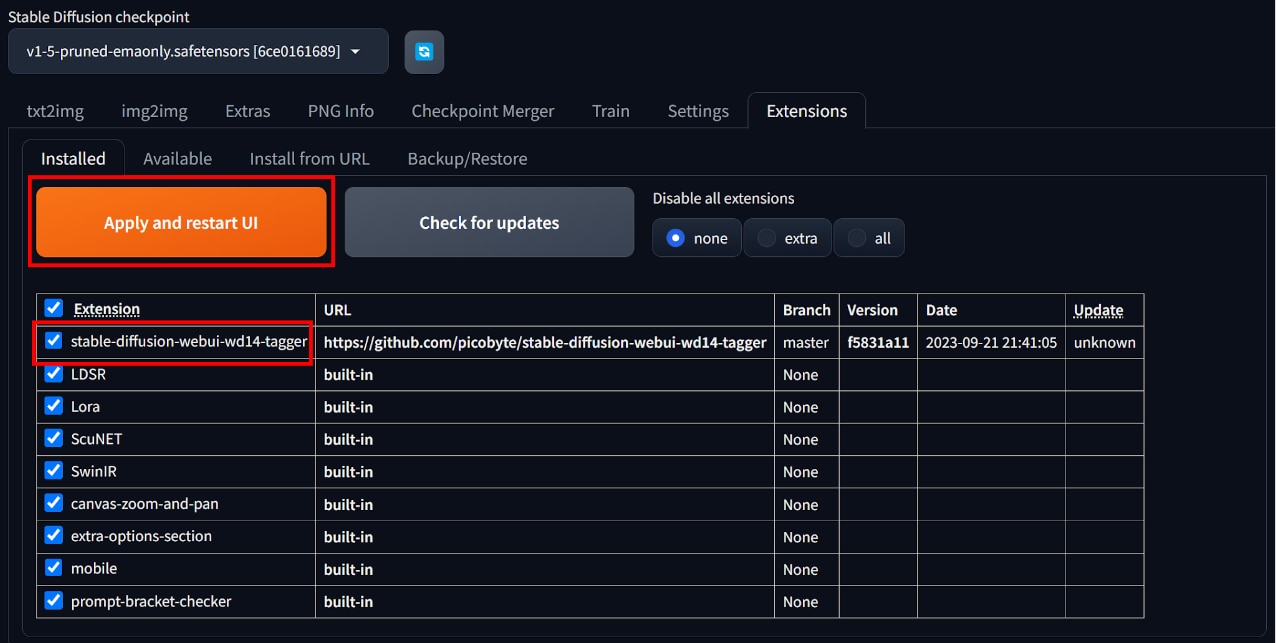
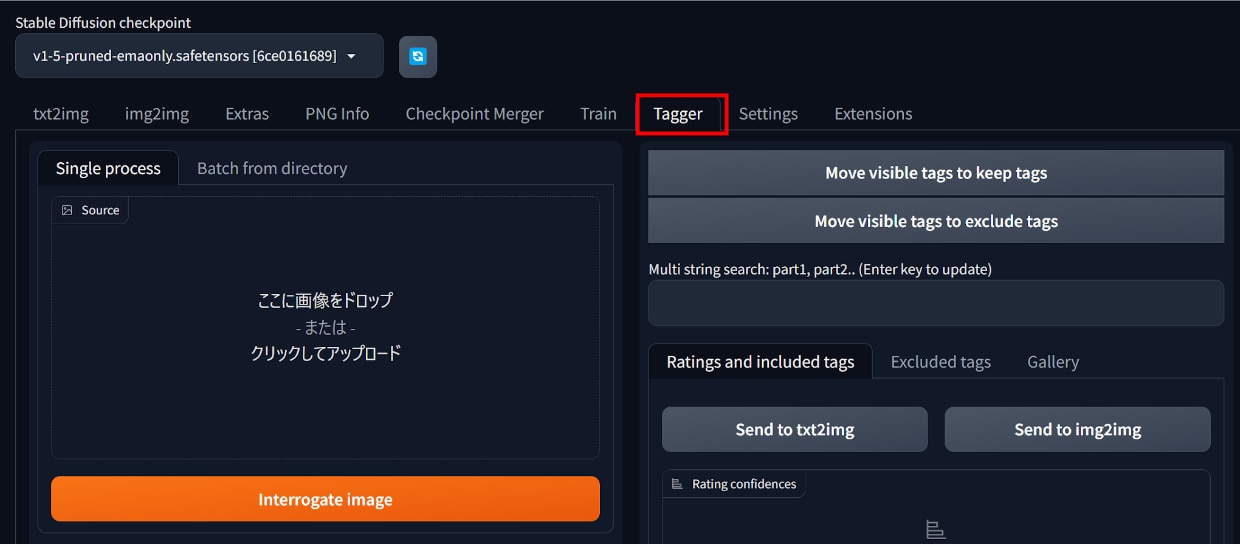
更新後に[Tagger]タブが表示されていたら、インストール完了です。
※以下の”toriato”が含まれるURLからでもwd14-taggerでもインストールをすることができますが、Stable diffusion Web UI v1.6では[taggar]タブが表示されないエラーが確認されています。
当該エラーが発生する場合は、以下のURLではなく、前述の"picobyte"が含まれるURLをご利用ください。
キャプションの作成・編集
ここでは学習に必要なキャプションファイルを作成・編集する方法を解説します。
キャプションの作成
キャプションを作成する方法は以下のとおりです。
初めにデータのインプットとアウトプットをするフォルダパスの指定をします。
[Tagger]タブ、[Batch from directory]タブを選択します。
[Input directory]に学習用の画像データを格納したフォルダパスを貼り付けます。
[Output directory]に出力先のフォルダパスを貼り付けます。
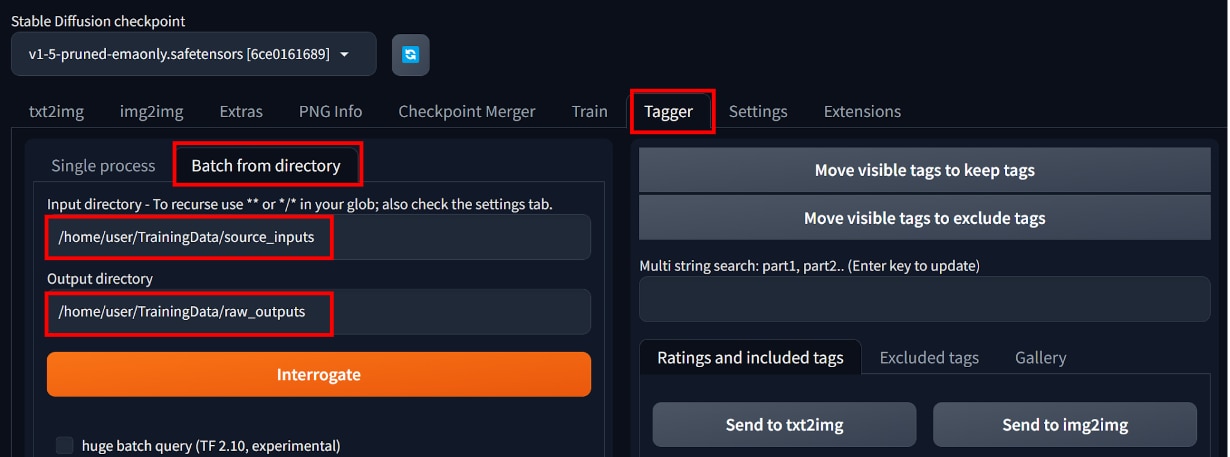
次に画面の下の方にある[Additional tags(split by comma)]に任意のトリガーワードを入力します。
トリガーワードは作成したLoRAを呼び出すためのプロンプトとして使用します。
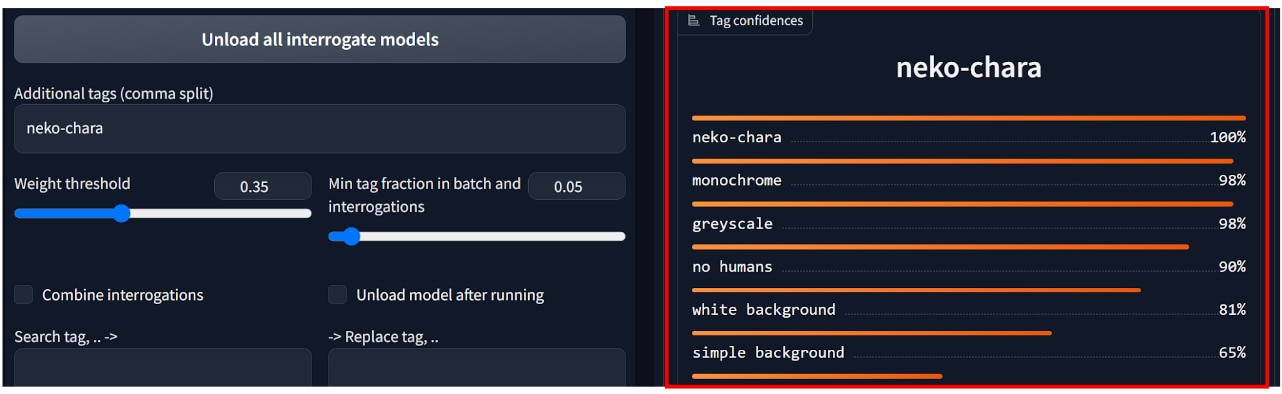
今回は猫のキャラクターを扱うためトリガーワードを[neko-chara]としました。
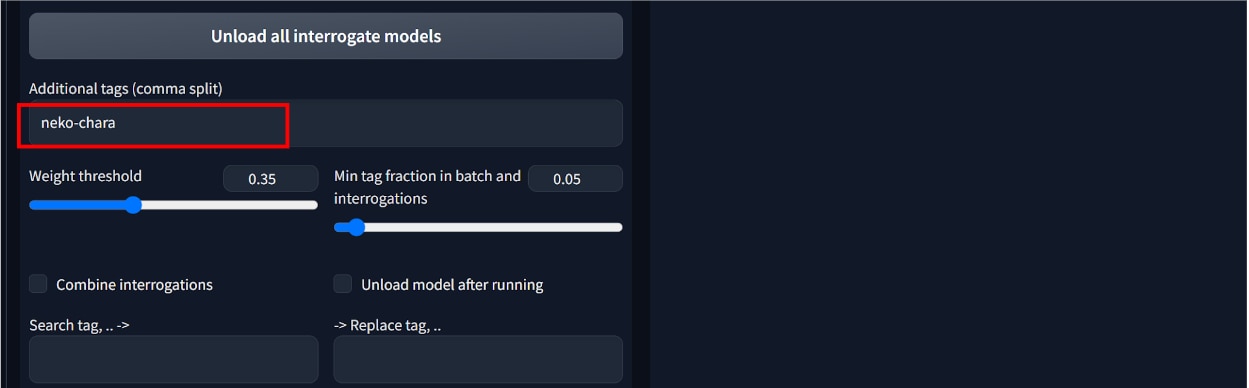
最後に[Interrogate]ボタンをクリックします。
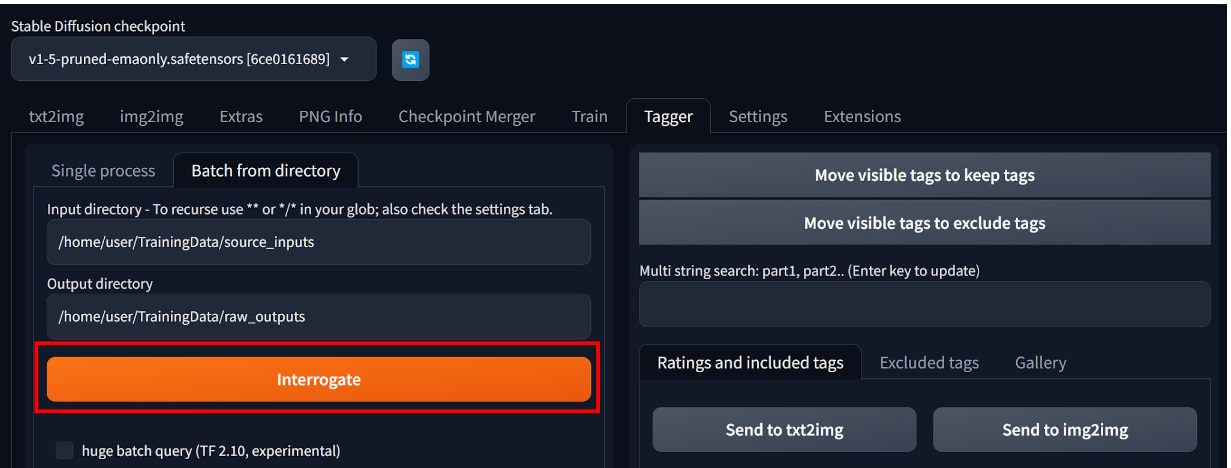
次のような表示がされたら、キャプションファイルの作成が完了です。
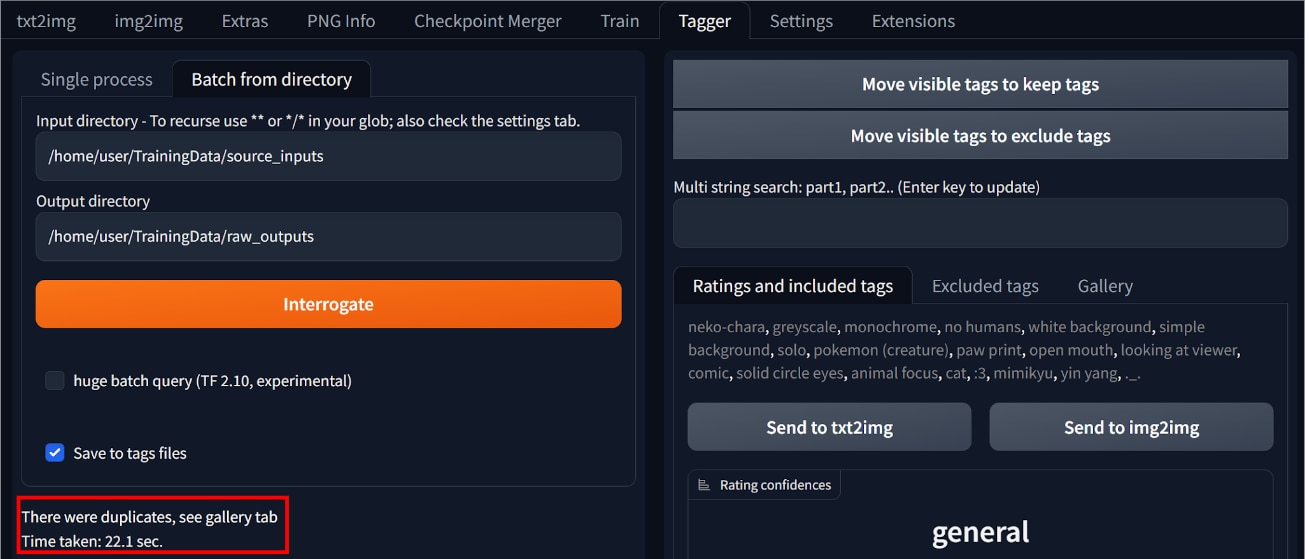
キャプションの編集
キャプションは、学習させたくない内容を指定するものです。
作成したキャプションファイルには、学習に必要なキーワードが含まれているため、そのままでは使えません。
キャプションファイルに記述されているキーワードを編集する必要があります。
まず以下のディレクトリからキャプションファイルを確認してみます。
[Stable-diffusion-webui] > [TrainingData] > [raw_outputs]
拡張子.txtのテキストファイルをエディタ等で開きます。(この記事では、VScodeのエディタを使用しています。)
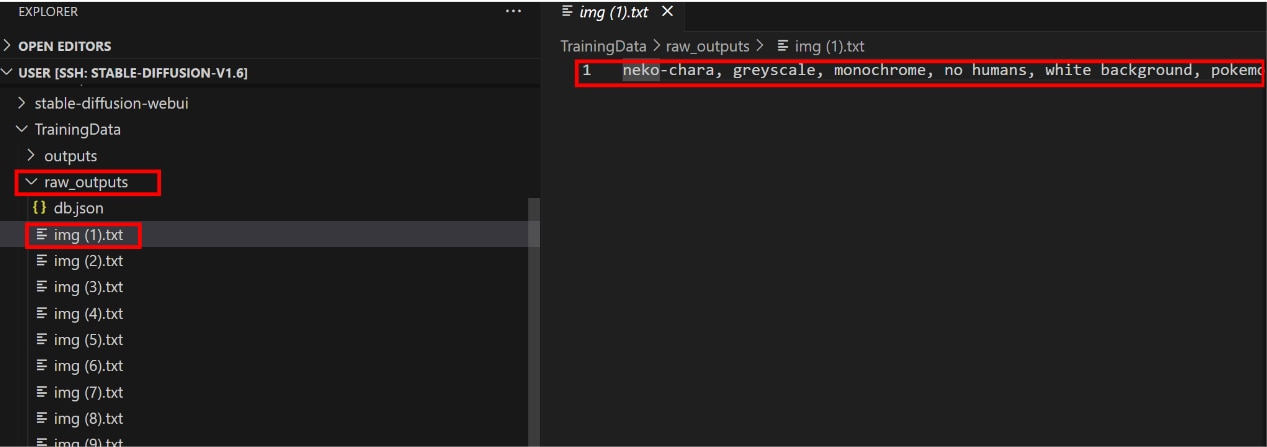
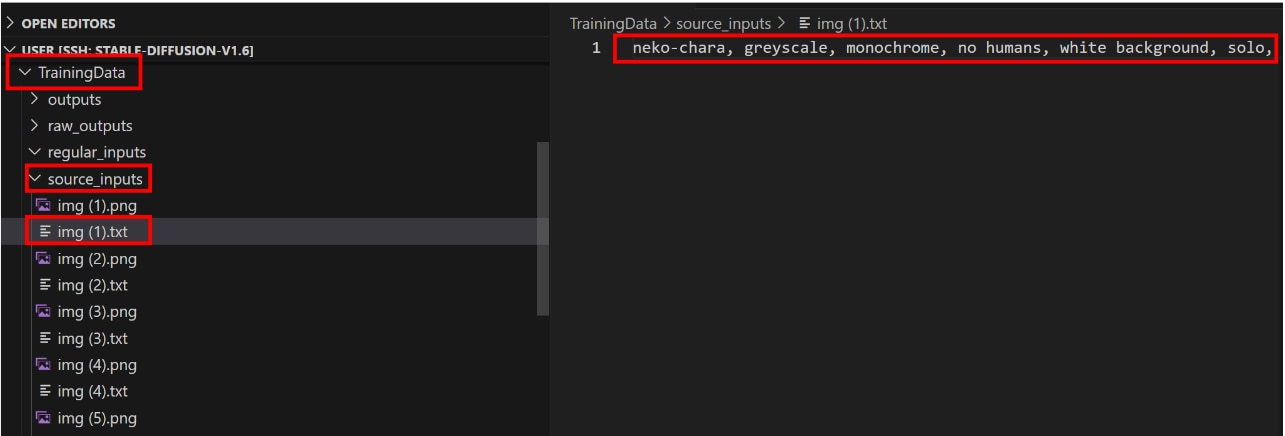
例として[img(1).txt]を開いてみます。
キャプションファイルの先頭にはトリガーワード(neko-chara)が表示され、続いて画像[img(1).txt]の特徴を抽出したキーワードがカンマ区切りで並んでいます。
これらのキーワードから学習させたいものを削除します。
※キャプションは学習させたくないものを指定するファイルのため、ここでは学習させたいキーワードを削除する点にご注意ください。
学習させたいキーワードの削除後は、以下のようにトリガーワードと学習させたくないキーワードだけが残ります。
キャプションファイルは学習用画像の枚数の分だけ生成されているため、全てのファイルを手動でキーワード編集していては日が暮れてしまいます。
この記事ではスクリプトを使って自動的ににキャプションファイルの編集を行います。
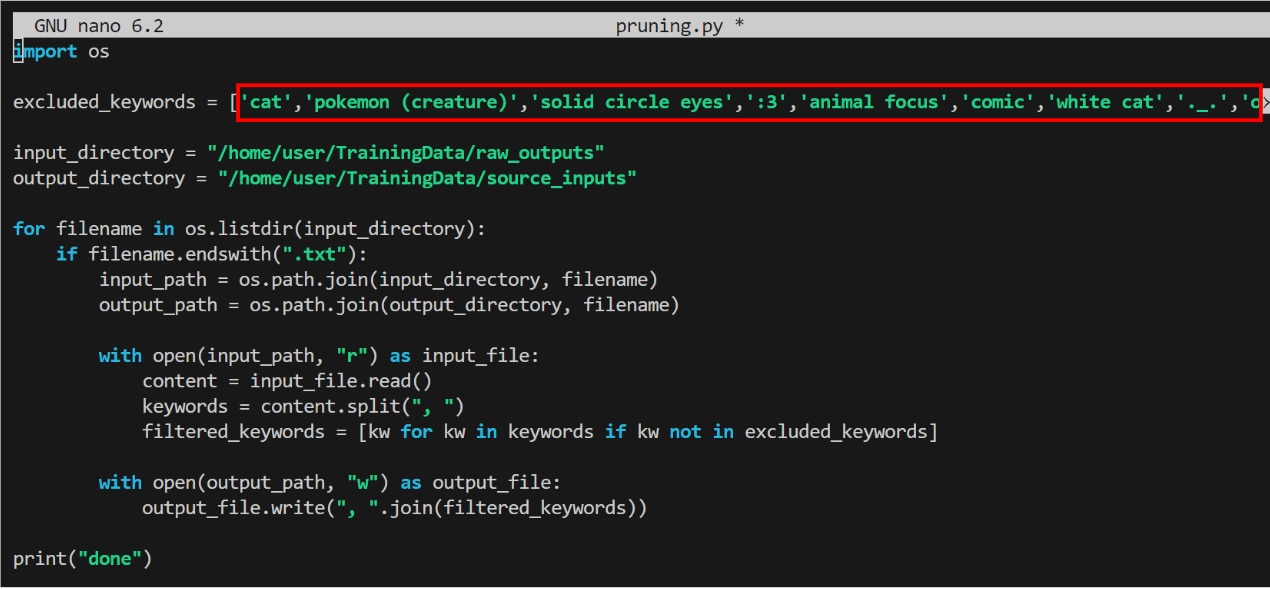
このスクリプトは、指定のディレクトリの中のキャプションファイルから、指定したキーワードを削除するプログラムになっています。
まず除外するキーワードはWeb UIの[tagger]タブの[Tag confidences]を参照します。
[Tag confidences]では、全てのキャプションファイルのキーワードが集計されていますので、この中から学習させたいキーワードを控えておきます。
次のコマンドでPythonファイルを作成し編集します。
![]()
以下のスクリプトをコピーして開いたファイルに貼り付けます。
[excluded_keywords]に学習させたいキーワード(=キャプションファイルから削除するキーワード)を入力します。
編集を終えたら[Ctrl]+[S]キーでファイルを保存し、[Ctrl]+[X]でファイルを閉じます。
python pruning.pyを実行し、全てのキャプションファイルから指定したキーワードを削除します。

キーワードを削除したキャプションファイルは、[TrainingData] > [source_inputs]のディレクトリに格納されています。
datasetconfigファイルを作成する
LoRAの学習におけるパラメーターを指定するdatasetconfigファイルを作成する手順を解説します。
次のコマンドを実行してディレクトリを移動し、datasetconfigファイルを作成し編集します。
以下の内容をコピーして開いたファイルに貼り付けます。
image_dirの行に学習に使用する画像ファイルのディレクトリパスを指定します。
num_repeatsは繰り返し学習する回数になります。

編集が完了したら、[Ctrl]+[S]キーで保存し、[Ctrl]+[X]キーでファイルを閉じます。
Accelerateファイルを作成する
LoRAの学習を実行するaccelerate.shファイルを作成する方法を解説します。
次のコマンドを実行し、ディレクトリを移動してaccelerate.shファイルを作成し編集します。
(accelerate.shファイルの編集画面)
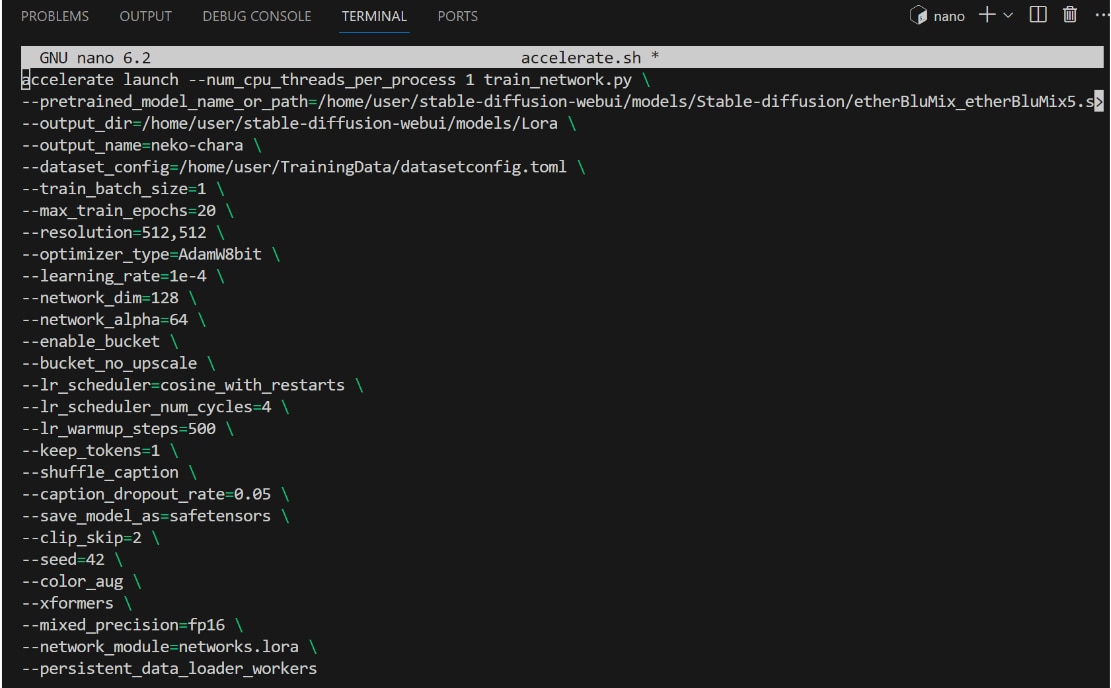
(主要なコマンドの説明)
編集が完了したら、[Ctrl]+[S]キーで保存し、[Ctrl]+[X]キーでファイルを閉じます。
学習の実行
用意したファイルを使って学習を実行します。
次のコマンドを実行し、venv仮想環境を(lora)に切り替えます。

次のコマンドを実行し、ディレクトリを移動します。

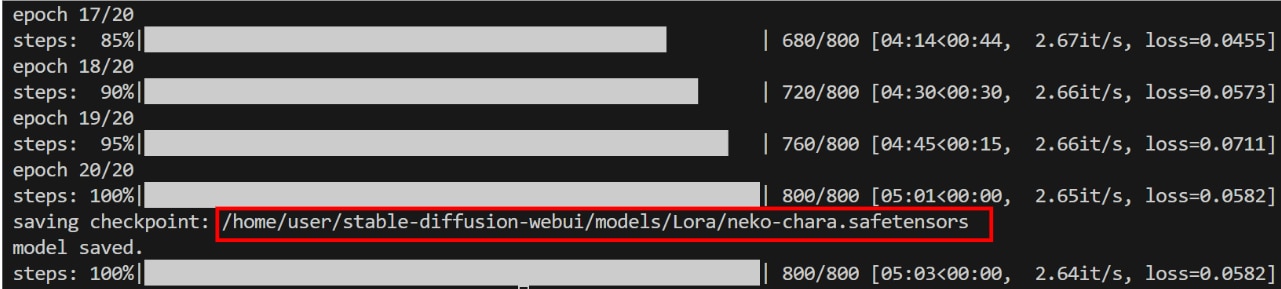
次のコマンドを実行し、accelerate.shファイルを実行します。
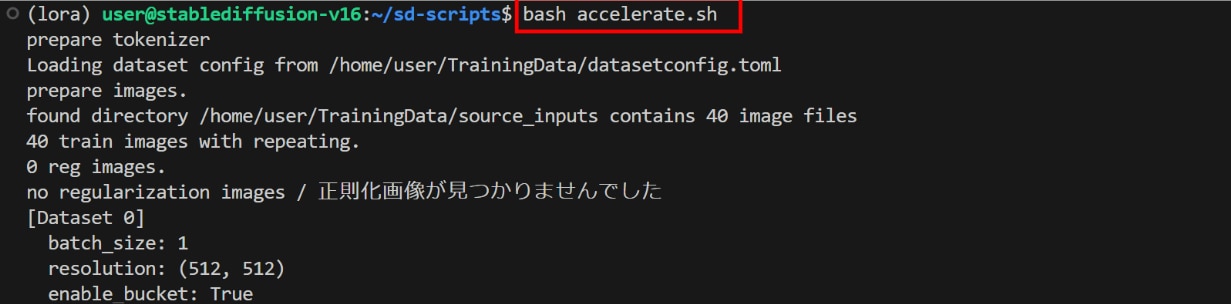
以下の表示がされたら、LoRAファイルの作成が完了です。
insufficient shared memory(shm)のエラーが出る場合
次のエラーが出る場合、shared memory(shm)の不足の可能性があります。
ここではshm不足の対処法を解説します。
次のコマンドでshmのサイズを確認します。
shmのサイズが64M(=64MB)になっていることが確認できます。

次のコマンドでfstabファイルを開いて編集します。
![]()
開いたfstabファイルに以下の内容をコピペします。

defaults,size=4G(=4GB)がshmに割り当てられるサイズになります
4Gの値は変更可能で、shmに割り当てるサイズを任意に調整できます。
編集が完了したら、[Ctrl] + [S]キーで変更を保存し、[Ctrl] + [X]でファイル編集モードから抜けます。
次のコマンドで上記で変更した内容をファイルシステムに反映させます。
![]()
次のコマンドで変更した結果を確認します。
shmのサイズが4.0G(=4GB)になっていることが確認できました。

動作確認
作成したLoRAファイルを確認してみます。
次のコマンドでディレクトリを移動し、作成したLoRAファイルを確認します。

この記事では[neko-chara.safetensors]が作成したLoRAファイルになります。
venv仮想環境を(base)に切り替えます。

ディレクトリを移動し、Stable Diffusion Web UIを起動します。

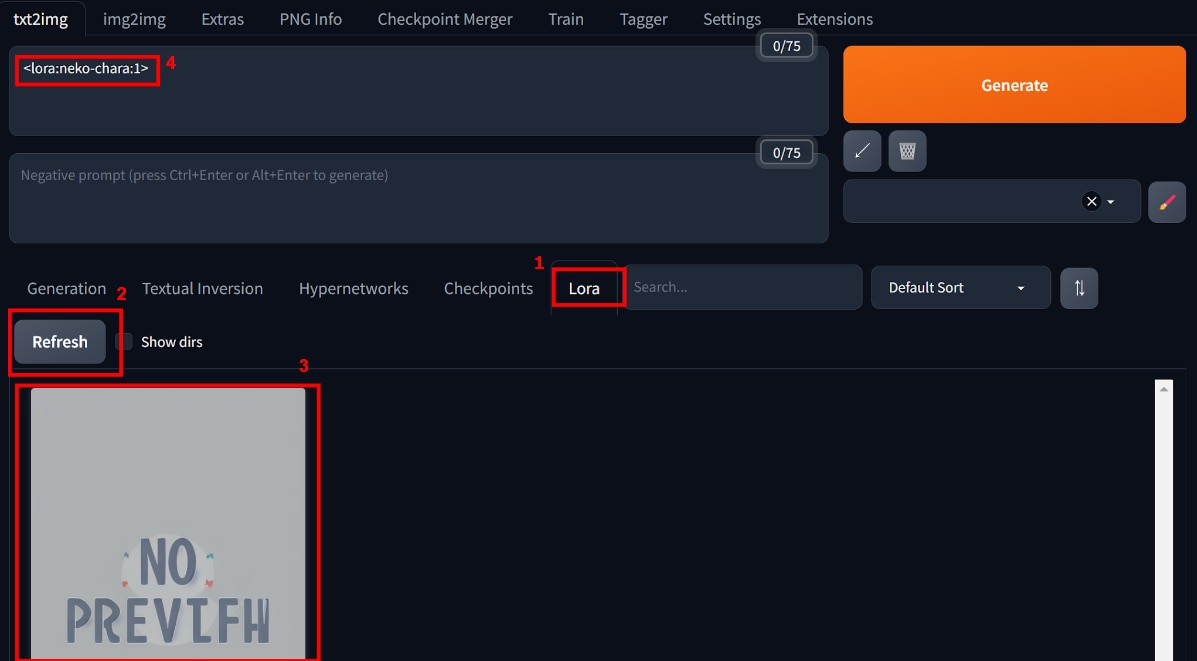
[Lora]タブを開き、[Refresh]ボタンを押すと[LoRAファイルのサムネイル]が表示されます。
[サムネイル]をクリックすると、[Prompt]に<lora:neko-chara:1>というトリガーワードが表示されます。
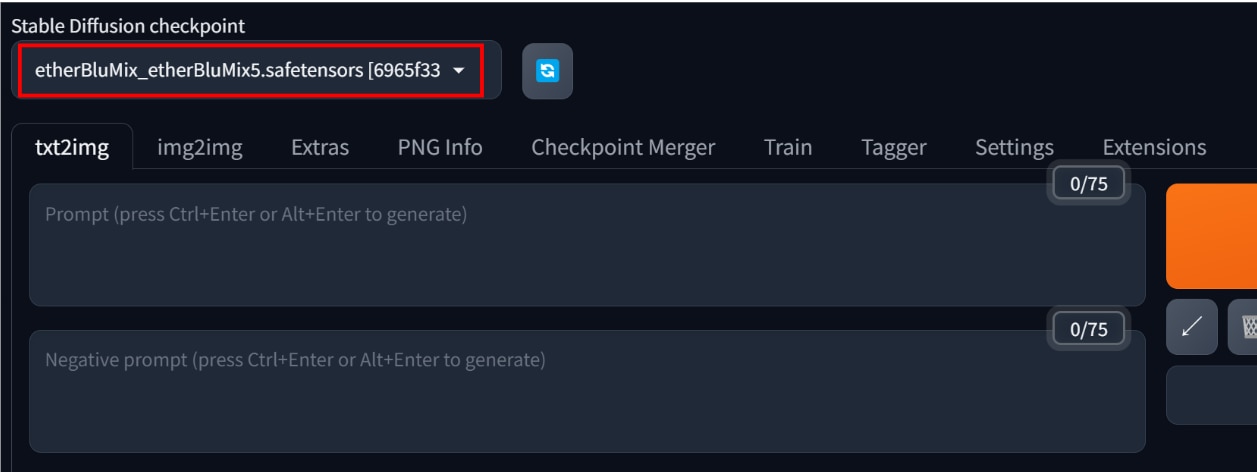
LoRAの元になるモデルファイル(Checkpoint)の設定をします。LoRAは追加学習をしたファイルであるため、元になるモデルファイルと組み合わせて使う必要があります。
[Stable Diffusion checkpoint]のプルダウンメニューからモデルを選択するとセットされます。
この状態で[prompt]、[Negative prompt]にテキスト入力し、[Generate]を押して画像を生成します。
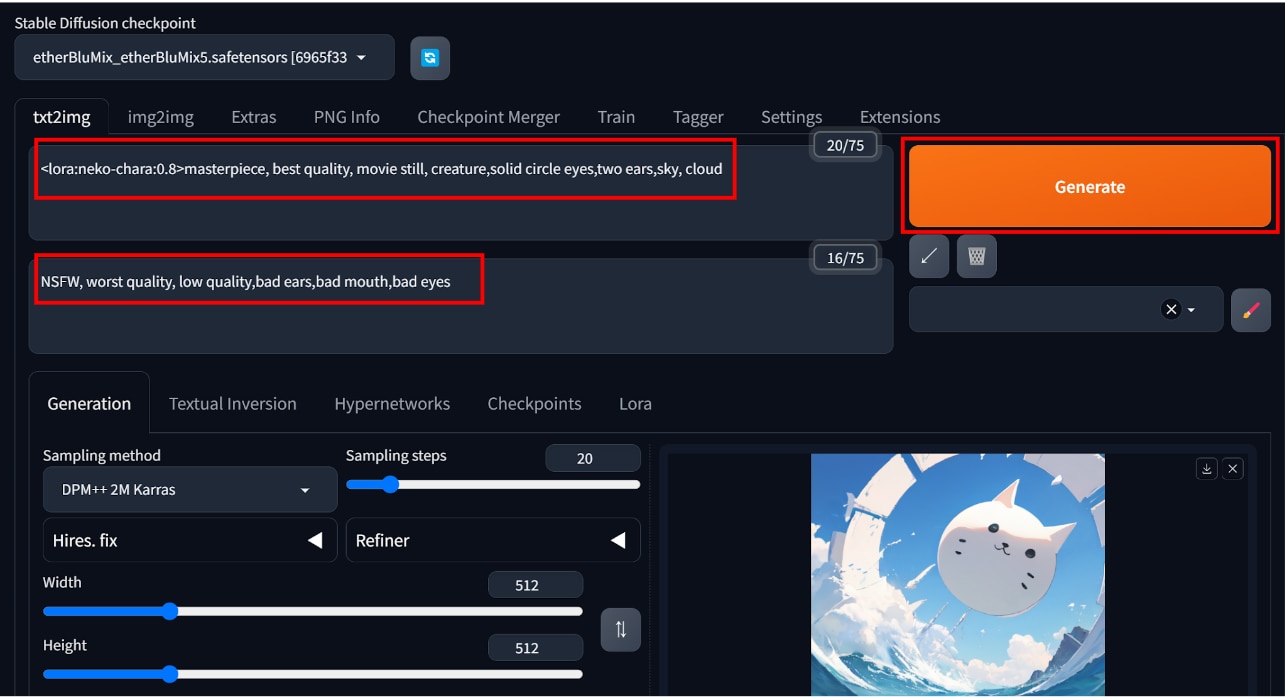
学習データの特徴を捉えた画像が生成されていることが確認できました。

参考までにこの記事で使用したパラメーターは以下のとおりです。
もっと自由な画像生成を
Stable Diffusionを実行する環境で、以下のような悩みをお持ちではないでしょうか?
- 画像生成が遅い
- 使いたいGPUが使えない
- GPUメモリ(VRAM)が足りない
- ランタイムがリセットされる度にデータが消えるため、設定のやり直しが大変
- 画像データのバックアップが面倒
- Web UIの起動に時間がかかる
- コンピューティングユニットの制限がストレス
- 動作が不安定
制限を気にせず、高速かつ格安に画像生成がしたいなら、GPUクラウドサービス「GPUSOROBAN」がおすすめです。
まとめ
この記事では、LoRAファイルの作り方について紹介しました。
オリジナルのLoRAファイルを作ることで、意図した画像を生成しやすくなります。
Stable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。



