

【LLM】Google Gemmaのファインチューニング
Gemmaは、Googleが公開した軽量かつ高性能なLLMで、商用利用可能なオープンモデルです。
この記事では、Gemmaのファインチューニングの方法について紹介しています。
目次[非表示]
- 1.Gemmaとは
- 2.Gemmaのファインチューニング
- 3.GemmaのファインチューニングにはGPUが必要
- 4.Gemmaのモデル申請
- 5.実行環境
- 6.Jupyter Labを起動
- 7.パッケージのインストール
- 8.データセットの読み込み
- 9.モデルの設定
- 10.QLoRAの設定
- 11.トレーニングのパラメータ設定
- 12.ファインチューニングの実行
- 13.GPUメモリの解放
- 14.ファインチューニング後モデルでテキスト生成
- 15.LLMならGPUクラウド
- 16.まとめ
Gemmaとは
Gemmaは、Googleが公開したGeminiと同じ技術を活用した軽量なLLMモデルで、ローカルPCの環境でも動かすことができます。
Gemmaの性能は、MetaのLlama2など同規模のモデルを上回ると言われています。学習データから特定の個人情報や機密データを除外しており、安全性の高さも誇ります。
またGemmaはオープンモデルとして公開されており、利用規約に同意をすれば商用利用が可能です。
Gemmaの性能・安全性・商用利用・推論での使い方については以下の記事で詳しく解説しています。
Gemmaのファインチューニング
Gemmaのモデルを新しい領域やタスクに適応させるためにファインチューニング(追加学習)を行うことができます。
専門的な情報やローカルな情報など、未知のデータを使ってモデルをファインチューニングすることで、Gemmaベースの独自のモデルを作成できます。
この記事ではGemmaベースモデルに対してファインチューニングする方法を解説します。ファインチューニングをすることで、プロンプトに対して自然な応答ができるようになります。
GemmaのファインチューニングにはGPUが必要
Llama2でファインチューニングをする際には、大量の計算を行うためにGPUが必要です。
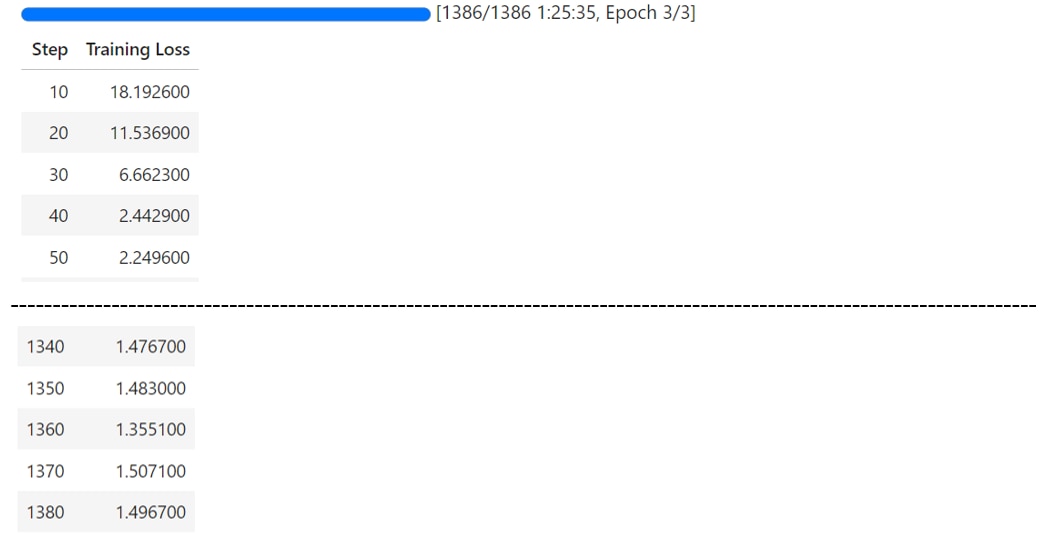
この記事では量子化を使って、精度を落とす代わりにモデルを軽量化して、1GPUで実行する方法を紹介してます。
モデル |
パラメータサイズ |
タイプ |
ファインチューニング手法 |
データセット |
GPUメモリ使用量 |
ファインチューニングの時間 |
使用したGPU |
google/gemma-7b |
70億 |
base model |
QLoRA |
philschmid/dolly-15k-oai-style |
19.8GB |
1時間25分 |
NVIDIA A100 80GB x1 |
Gemmaのモデル申請
Gemmaのモデルを使うためには利用申請が必要になります。
Gemmaの利用申請の方法は、以下の記事で詳しく解説しています。
実行環境
この記事ではGPUクラウドサービス(GPUSOROBAN)を使用しました。
- インスタンス名:t80-1-a-standard-ubs22-i
- GPU:NVIDIA A100 80GB x 1
- OS :Ubuntu 22.04
- CUDA:11.7
- Jupyter Labプリインストール
GPUSOROBANはメガクラウドの50%以上安いGPUクラウドサービスです。 GPUSOROBANの使い方は以下の記事で解説しています。
Jupyter Labを起動
GPUSOROBANのインスタンスに接続したら、次のコマンドを実行し、Jupyter Labを起動します。
ブラウザの検索窓に"localhost:8888"を入力すると、Jupyter Labをブラウザで表示できます。
Jupyter Labのホーム画面で[Python3(ipykernel)]を選択し、Notebookを開きます。

Jupyter Labの詳しい使い方は以下の記事で解説しています。
インスタンスにプリインストールされたJupyter Labを使用する場合
Jupyter Labを新しくインストールして使う場合
パッケージのインストール
JupyterLabのNotebookのコードセルで次のコマンドを実行し、PyTorchをインストールします。
次のコマンドを実行し、必要なパッケージをインストールします。
上記のパッケージのインストールが完了したら、Flash attentionをインストールします。
Flash attentionは、Transformerの処理を効率化して学習を高速化します。
HuggingFaceにログインするためのパッケージをインストールします。
HuggingFaceにログインします。
token = "*************"には、HuggingFaceで発行したアクセストークンが入ります。
HuggingFaceでアクセストークンを発行する方法は以下の記事で解説しています。
データセットの読み込み
モデルのトレーニングにはデータセット[philschmid/dolly-15k-oai-style]を使用します。
15,000以上のプロンプトと応答がペアになったデータセットです。
モデルの設定
必要なライブラリをインポートします。
4bit量子化の設定をします。
量子化により精度を落とす代わりにモデルを軽量化して、GPUメモリを節約できます。
モデルとトークナイザーの設定をします。
モデルはgemma-7bのベースモデルを使用します。
パイプラインの設定をします。
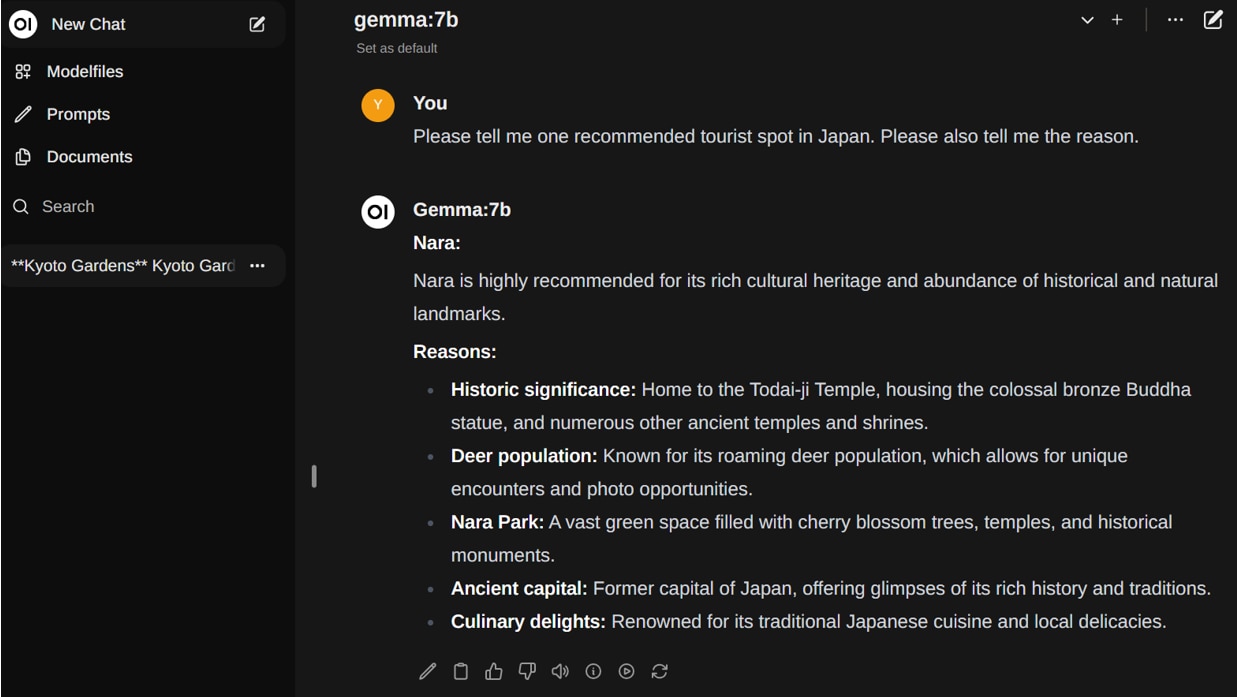
ファインチューニング前のモデルでテキスト生成(推論)をテストしてみます。
ファインチューニング前のモデルでは、プロンプトにうまく応答ができていないことが確認できます。
QLoRAの設定
QLoRAの設定をします。QLoRAとは、事前学習済みモデルに対して一部のパラメータのみを更新する計算効率の高い手法です。
さらに事前学習済みモデルを量子化してロードするため、GPUメモリを節約できます。
トレーニングのパラメータ設定
トレーニングのパラメータ設定を行います。
ファインチューニングの実行
SFTTranerを使ってファインチューニングを実行します。
SFTTrainerは、モデルに対して教師ありファインチューニングをするTrainerです。
GPUメモリの解放
ファインチューニングが完了したら、モデルとTrainerの設定、キャッシュの削除によりGPUメモリを解放します。
ファインチューニング後モデルでテキスト生成
ファインチューニング後のモデルでテキスト生成を行うための設定をします。
プロンプトを実行します。
ファインチューニング後のモデルでは、プロンプトに対してうまく応答ができています。
LLMならGPUクラウド
LLMを使用する際には、モデルサイズやタスクに応じて必要なスペックが異なります。
LLMで使用されるGPUは高価なため、買い切りのオンプレミスよりも、コストパフォーマンスが高く柔軟な使い方ができるGPUクラウドをおすすめしています。
GPUクラウドのメリットは以下の通りです。
- 必要なときだけ利用して、コストを最小限に抑えられる
- タスクに応じてGPUサーバーを変更できる
- 需要に応じてGPUサーバーを増減できる
- 簡単に環境構築ができ、すぐに開発をスタートできる
- 新しいGPUを利用できるため、陳腐化による買い替えが不要
- GPUサーバーの高電力・熱管理が不要
コスパをお求めなら、メガクラウドと比較して50%以上安いGPUクラウドサービス「GPUSOROBAN」がおすすめです。
大規模なLLMを計算する場合は、NVIDIA H100のクラスタが使える「GPUSOROBAN AIスパコンクラウド」がおすすめです。
まとめ
この記事では、Gemmaベースモデルをファインチューニングする方法を紹介しました。
モデルをファインチューニングすることで、Gemmaベースの独自のモデルを作成できます。
Gemmaに関する詳細は以下の記事で解説していますので、あわせてご覧ください。



