
NVIDIA H200とは?スペック・価格・導入するべき企業の特徴まで解説

「NVIDIAのH200とは?」「従来のH100となにが違う?」と疑問を持つ方も多いでしょう。生成AIや大規模言語モデル(LLM)の実用化が進む現在、企業の競争力は「どれだけ高速にデータを処理し、精度の高い推論・学習を行えるか」に左右されるようになりました。その中で注目を集めているのが、NVIDIAが提供する次世代GPU「H200」です。
そこで本記事では、
- H100との比較
- H200が持つ3つの特徴
- H200を導入するべき企業
を重点的にわかりやすく解説します。
「NVIDIA H200を試してみたい」「H200を低価格で使用したい」という方は、GPUSOROBANの利用を検討してみてください。GPUSOROBANでは、NVIDIA H200を搭載したGPUインスタンスを低コストで提供するクラウドサービスです。
用意するのはインターネット環境のみで、他社サービスと比較して最も安い料金設定で、上位機種のHGX H200を提供します。まずは30日間無料トライアルを活用してみてください。
NVIDIA H200とは?

出典:NVIDIA
NVIDIA H200は、NVIDIA社が2023年末に発表した最新世代のデータセンター向けGPUです。従来のH100 Tensor Core GPUの後継モデルであり、同社のHopperアーキテクチャを採用したHopper世代の新GPUとなります。
大容量かつ高速なメモリにより、大規模言語モデル(LLM)のような生成AIや科学技術計算(HPC)において、膨大なデータをGPU内に保持したまま高速処理できるように。
その結果、外部ストレージへのアクセス頻度が減り、AIモデルの推論・学習や科学計算のパフォーマンスが飛躍的に向上しています。
H200のスペック表
まずはH200の基本スペックを見てみましょう。H200はデータセンター向けの製品であり、主に2つのフォームファクター(形態)で提供されます。一つはNVIDIA HGX基板上に実装される高性能版(SXMモジュール)、もう一つはPCI Expressカード型のH200 NVL(後述)です。
以下は主なスペックの一覧です。
項目 | NVIDIA H200 Tensor Core GPU (SXM) |
アーキテクチャ | NVIDIA Hopper (第4世代 Tensor Core) |
GPUメモリ | 141GB HBM3e |
メモリ帯域幅 | 4.8TB/秒 |
FP64(倍精度演算性能) | 34 TFLOPS |
FP8 Tensorコア性能 | 3,958 TFLOPS |
消費電力(TDP) | 最大700W(SXMモジュール時) |
出典:NVIDIA
上記のように、H200は演算性能とメモリ性能を高めたGPUです。とくに141GBものHBM3eメモリを搭載した点は従来にない強みで、大規模AIモデルの処理や高精度な科学計算に威力を発揮します。
また、第4世代Tensor CoreやTransformer EngineといったHopper世代の最新テクノロジーを継承し、FP8など低精度演算にも対応することで、より省電力で高速なAI処理を可能にしています。
H200の価格
H200は一般的なPC向けGPUとは異なり単体販売されるケースは少ないものの、一部取り扱い業者での参考価格として約532.5万円(税込・最安値)ほどで提供されています。
実際の導入コストは、システム構成や契約形態によって変動しますが、H200を8基搭載したサーバー1台で数千万円規模の投資になることも珍しくありません。こうした高性能GPUは、完成品サーバーとして購入するか、クラウドサービス経由で利用するのが一般的です。
徹底比較|NVIDIA H200とH100の違い

次に、H200が前世代H100からどのように進化したのか、性能面とコストパフォーマンス面の違いを徹底比較します。H100も2022年登場の当時最先端GPUでしたが、H200ではメモリを中心に多くの改良が加えられています。ここでは2つの視点で比較します。
- コストパフォーマンス
- 性能
コストパフォーマンス
H200は高価なGPUですが、コストパフォーマンス(費用対効果)は向上していると言えます。なぜなら、1基のH200で処理できる仕事量がH100より大きく、必要なGPU枚数や消費電力量を削減できる可能性があるからです。
例えば、大規模なLLMの推論を行う場合、従来は80GBメモリのH100を複数台連結しなければモデル全体を載せられないケースがありました。しかしH200では141GBの大容量メモリによって単一GPUでより大きなモデルを扱えるため、場合によっては「H100を16基搭載したサーバー2台分」の仕事が「H200を8基搭載したサーバー1台」で済むこともあります。
GPU台数やサーバー台数が削減できれば、その分ハードウェア導入費用や電力・冷却コストも削減できるため、トータルの投資対効果が向上するわけです。
性能
性能面では、H200は各種ベンチマークや仕様上でH100を大きく上回る数値を示しています。主なスペックの違いを以下の表にまとめます。
項目 | H100 | H200 | 向上率・特徴 |
GPUアーキテクチャ | Hopper | Hopper + HBM3e | メモリSubsystem強化(HBM3e採用) |
GPUメモリ容量 | 80GB | 141GB | 約1.76倍 |
メモリ帯域幅 | 3.35TB/秒 | 4.8TB/秒 | 約1.4倍 |
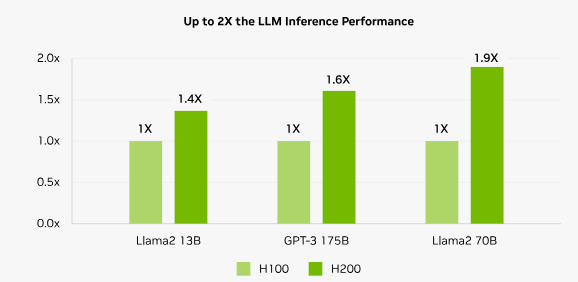
LLM推論性能 | 1.0(基準) | 最大1.9 | 最大1.9倍 |
出典:NVIDIA
表から分かるように、H200ではメモリ容量と速度が大幅アップしていることが大きなポイントです。これにより、大規模モデルの全データをオンメモリで処理できるため推論や学習の効率が上がります。
NVIDIAの社内テストでは、LLM(Llama2 70B)の推論処理でH200がH100に対し最大1.9倍のスループットを示したと報告されています。
 出典:NVIDIA
出典:NVIDIA
さらにH200はHPC(高性能計算)の分野でも威力を発揮しており、最新のx86系CPUと比較すると最大110倍もの性能差を示すケースがあります。これは具体的に言うと、科学技術計算や物理シミュレーションなどCPUでは時間のかかる処理が、H200を用いることで桁違いに高速化できることを意味します。
NVIDIA H200が持つ3つの特徴

ここからは、H200がもたらす具体的なメリットを3つの観点から解説します。
- 高速なAI推論でビジネスの意思決定を加速する
- 大規模データ処理を圧倒的なスピードで実行
- 電力コストと運用コストを同時に削減
特徴 | 01 |
高速なAI推論でビジネスの意思決定を加速する
H200の登場により、生成AIモデルの推論速度は飛躍的に向上しました。前述の通り、例えば大規模言語モデルの推論ではH100比で最大約2倍近いスループットを達成。これは、ChatGPTのような高度なAIから回答や分析結果を得るまでの時間が半分程度になると言うことです。
ビジネス現場において、AIがリアルタイムに近い形でインサイト(洞察)を提供できれば、意思決定のスピードも格段に上がるでしょう。また、H200では単体で141GBものメモリがあるため、より大きなモデルを1枚のGPU上に収めて推論実行できる可能性が広がります。その結果、複数GPU間の通信を最小限に抑え、レイテンシー(遅延)の低い推論が実現可能です。
実際、NVIDIAはH200搭載システム(8GPU)なら、従来は16基のH100を要していたLLM推論を単一ノードで処理できるケースがあるとしています。これはシステム構成の簡素化と応答速度の向上の両面で利点です。
以下の記事では、AI・機械学習に強いNVIDIAのGPUを10個紹介していますので、あわせてチェックしてみてください。
特徴 | 02 |
大規模データ処理を圧倒的なスピードで実行
H200はAIだけでなく、大規模データの処理や科学技術計算(HPC分野)でも性能を発揮します。例えば、シミュレーションや解析系のワークロードでは、高い演算精度と大容量メモリが要求されますが、H200はどちらもトップクラスの性能を備えています。
倍精度演算性能は34TFLOPSとH100世代から据え置かれているものの、先述したようにメモリ性能の大幅向上により、メモリ帯域幅に起因するボトルネックが緩和。その結果、データ転送を伴うような処理で全体のスループットが向上しており、HPC系のアプリケーションでもH100を上回る性能を示します。
実際、NVIDIAの発表によればH200は最新のCPUサーバーと比べて最大110倍もの速度で演算をこなすことができます。H200のような高性能GPUを用いれば、従来は時間のかかったデータ集計や特徴抽出処理をバッチで一気に片付けることも可能です。
特徴 | 03 |
電力コストと運用コストを同時に削減
H200は高性能化を実現しつつも、電力効率の改善によって結果的に電気代や運用コストの削減にも寄与します。前述のように、H200はH100と同程度のTDPで倍近い性能を発揮できるため、ワットあたり性能が向上しています。データセンター全体で見れば、同じ処理を行うのに必要な電力量が減ることになるため、電力コストの低減(省エネ)につながります。
特に近年は生成AIブームでGPUサーバーの台数が増大しており、消費電力や空調コストが課題となっている企業も多いでしょう。H200の導入はコスト課題に対する一つの解決策となりえます。
上記のようにH200は発売されているGPUの中でもトップクラスの性能を誇ります。ですが、導入には500万円前後と予算が足りないという企業も多いでしょう。そこでGPUSOROBANの活用を検討してみてください。
GPUSOROBANは業界最安級の価格でH200を提供。設備投資や初期費用もかからないので、低価格でH200のクラウド導入が可能です。まずは以下のリンクから30日間の無料トライアルを実施してみてください。
NVIDIA H200を導入するべき企業

以上の特徴を踏まえ、どのような企業・組織がH200の導入に適しているかを3つの特徴から解説します。
- 生成AI・LLMを本番環境で活用したい企業
- 大量データを扱うシミュレーション・科学計算を行う企業
- AI基盤のコスト最適化とエネルギー効率を重視する企業
生成AI・LLMを本番環境で活用したい企業
自社サービスに生成AIや大規模言語モデルを組み込み、本番環境で安定的に提供したい企業にはH200が適しています。推論性能が大幅に向上しているうえ、大容量メモリによって巨大モデルを分割せずに扱いやすいです。そのため、
リアルタイム処理が求められるチャットボットや検索
画像生成サービス
でも高い応答性を維持できます。また、一般的な空冷サーバー環境でも運用しやすい設計や企業向けサポートが用意されているため、インフラ構築のハードルを下げながら信頼性の高いAI基盤を整備可能です。
AIを単なる実験で終わらせず、収益に直結するプロダクトとして展開したい企業におすすめです。
大量データを扱うシミュレーション・科学計算を行う企業
自動車や航空機の設計、創薬、材料開発、気象解析など、大規模な計算処理を必要とする企業や研究機関にもH200は適しています。広帯域メモリと高い演算性能により、従来は数日かかっていた解析を大幅に短縮できる可能性があり、試行回数の増加によって研究開発のスピード向上が期待できます。
さらに高精度計算にも対応しているため、精度を維持したまま処理効率を高められる点も重要です。計算リソース不足がボトルネックとなり、新しいアイデアを検証できない環境では、H200の導入が技術革新を加速させる基盤となるでしょう。
AI基盤のコスト最適化とエネルギー効率を重視する企業
大規模なAIインフラを運用する企業にとって、H200は性能だけでなくコスト効率の面でも魅力があります。処理能力が高いため、同じワークロードをより少ないGPUで実行できる可能性があり、結果として電力消費や設備コストの削減につながります。
また、高密度構成により限られたデータセンタースペースを有効活用できる点もメリットです。さらに企業向けソフトウェアやサポートが提供されていることで運用負荷を軽減でき、人的コストの抑制も期待できます。
長期的なTCOの改善と環境負荷の低減を両立したい企業にとって、戦略的な投資先といえるでしょう。
NVIDIA H200に関するよくある質問

最後に、NVIDIA H200に関してよくある質問を紹介しています。導入を検討する上で疑問に思いやすいポイントについて整理しておきましょう。
Q. | NVIDIA H200の後継は? |
|---|---|
A. | NVIDIA H200の後継は、B200です。B200は、アーキテクチャの刷新によってさらなる性能向上と電力効率の最適化が図られています。H100比で学習性能最大3倍、リアルタイム推論性能最大15倍もの飛躍を遂げ、エネルギー効率も劇的に改善されているのが特徴です。 また、B200について詳しく知りたい方は以下の記事でも詳しく解説していますので、あわせてご覧ください。 |
Q. | H200はどこで購入・利用できますか? |
|---|---|
A. | H200は一般消費者向けには直接販売されておらず、主に法人向けにサーバーメーカーやクラウドサービス経由で提供されています。購入したい場合、NVIDIAの認定パートナー企業からH200搭載サーバーやワークステーションを調達する形になります。 NVIDIA H200を手軽に使用したい場合は、GPUSOROBANへお問い合わせください。 |
H200を低価格で使用できるGPUSOROBAN

最後に、GPUSOROBANについて紹介します。GPUSOROBANは、高性能GPUを安価かつ手軽に利用できるクラウドサービスで、NVIDIA H200もラインナップに含まれています。
自社でH200を購入・設置するのが難しい場合でも、GPUSOROBANを活用すれば低コストでH200を活用可能です。以下ではGPUSOROBANの特徴を3つのポイントに分けて解説します。
圧倒的なコストパフォーマンスの良さ
GPUSOROBANの魅力は、圧倒的に安い料金設定にあります。GPUSOROBANのGPUクラウドはAWSなど他社クラウドと比べて利用料金が大幅に安く設定されており、データ転送料も無料です。
特にH200のような高性能GPUインスタンスは大手クラウドだと高額ですが、約3割程度のコストで同等以上のGPU性能を使える計算で、コストパフォーマンスは抜群です。
GPUメモリはH100の「1.7倍」
GPUSOROBANが提供するH200インスタンスの強みとして、GPUメモリ容量の大きさが挙げられます。GPUSOROBANのH200インスタンスはNVIDIAのHGX H200プラットフォームを採用しており、8基のH200 GPU計1,128GBものHBM3eメモリを搭載しています。
この1,128GBという数字は、同じ8GPU構成のH100インスタンスと比べて実に1.7倍に相当します。これほど巨大なGPUメモリ空間を単一インスタンスで利用できるクラウドサービスは珍しく、大規模なLLMやディープラーニングモデルの推論・学習でもメモリ不足に悩まされる心配がほとんどありません。
1台からクラスタ構成を専有利用
GPUSOROBANはコスト面だけでなく、使い勝手や性能面でも優れた特徴を持っています。その一つが、物理サーバーを専有できるインスタンスであることです。
GPUSOROBANのGPUインスタンスはマルチテナント型ではなく、利用者ごとに専用の物理GPUサーバーを割り当てる方式をとっています。そのため、他ユーザーの影響を受けることなく、常に安定した性能を発揮できます。セキュリティ面でも、リソースを占有している方がデータ漏洩のリスクを低減できるメリットがあります。
上記のようにGPUSOROBANはNVIDIA H200をコスト面・利用面など多角的に高品質なサービスを提供しています。
NVIDIA H200をまずは試してみたい
予算が少なくH200の導入ができない
といった悩みがある方は、ぜひGPUSOROBANの利用を検討してみてください。
NVIDIA H200を搭載したGPUマシンがすぐに使える!
NVIDIA H200をクラウドで利用でき、面倒な構築作業なしですぐに利用開始できます。
生成AI・LLM学習・シミュレーションなど大規模計算に最適。オンプレミスや他社クラウドと比べても圧倒的に低コストで、最新GPUを手軽に利用できます。
無料トライアルも準備していますので、お気軽にお問い合わせください。






