
【LLM】大規模言語モデルBERTでニュース記事をカテゴリに分類
本記事ではGPUSOROBANのインスタンスを使い、事前学習済みBERTモデルをファインチューニングする方法を紹介します。
GPUSOROBANは高性能なGPUインスタンスが低コストで使えるクラウドサービスです。
サービスについて詳しく知りたい方は、GPUSOROBANの公式サイトを御覧ください。
目次[非表示]
- 1.BERTとは
- 2.環境構築
- 3.データセットの準備
- 4.モデルとTokenizerの読み込み
- 5.評価関数の定義
- 6.Trainerの設定
- 7.モデルの学習
- 8.結果の確認
BERTとは
BERTは、Bidirectional Encoder Representations from Transformers(トランスフォーマーによる双方向エンコーダ表現)の略称で、2018年にGoogleが提案した大規模言語モデル(LLM)です。
BERTは、Transformerと呼ばれるニューラルネットワークアーキテクチャを基にしています。Transformerは、Attentionを利用して文章内の単語間の関連性を学習することができるモデルであり、それによって長い文章でも文脈を理解できる特徴があります。
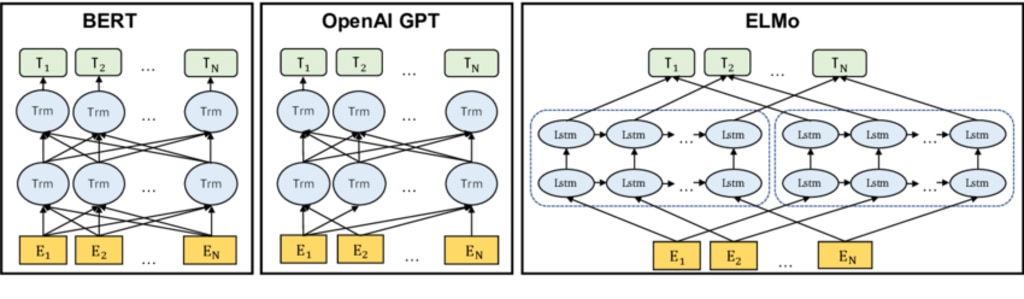
ChatGPTの大規模言語モデルであるGPTにもTransfomerが使われていることもあり、BERTとGPTのアーキテクチャは似ています。
OpenAI GPTのアーキテクチャ は、図中では黒矢印で示されているとおり、左から右への学習を最終層で連結する形です。一方でBERT のアーキテクチャの特徴はその名の示すとおり双方向(=Bidirectional)であり、全ての層で双方向の学習を行っています。
双方向の学習とは、単語や文の双方向からのコンテキストを考慮した学習を意味します。これにより、単語の意味や文脈をより豊かに理解することができます。単語の前後の情報を利用することで、単語の意味や解釈が異なる文脈においても正確に捉えることができます。
BERTの学習には事前学習とファインチューニングの2つのステップがあります。
事前学習は、大規模なテキストコーパスを使用してBERTモデルを事前に学習するプロセスです。この学習では、入力文の一部をマスクし、BERTが欠損した単語を予測するタスクや、文章の関係性を予測するタスクなどが用いられます。
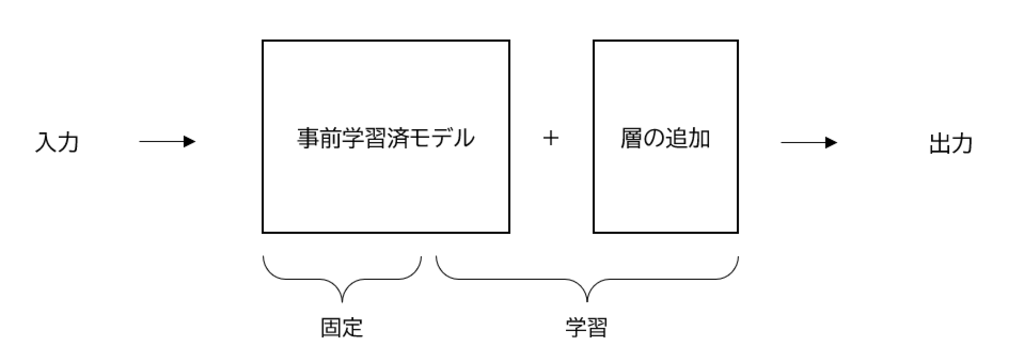
一方のファインチューニングは、特定のタスクのデータセットを利用して、事前学習したモデルに追加学習をします。タスクに応じた層の追加とタスクに適したデータセットでの学習を行います。ファインチューニングは学習済みモデルの一部も学習します。
ファインチューニングを行い、特定タスクへのモデルを適応させることで、パフォーマンスの向上が期待できます。
本記事ではBERTを使い、ニュースの分類をするモデルを実装をします。
ニュース記事のデータには、公開データであるlivedoorニュースコーパスを使用します。記事数は7367件から成り、各ニュース記事には下記の9種類のカテゴリが割り振られています。記事の内容をインプットし、適切なカテゴリを予測する問題になります。
<9種類のニュースカテゴリ>
トピックニュース
Sports Watch
ITライフハック
家電チャンネル
MOVIE ENTER
独女通信
エスマックス
livedoor HOMME
Peachy
環境構築
環境はGPUSOROBANのnvd4-80-1ulインスタンスを使用します。
nvd4-80-1ulは、NVIDIA A100を搭載した高性能GPUインスタンスです。機械学習を高速化するTensorコアや大容量GPUメモリ(80GB)が特徴です。後にGoogle ColaboのNVIDIA T4との学習時間を比較してみます。
GPUSOROBANのインスタンスの作成方法、秘密鍵の設置方法については、会員登録~インスタンス作成手順の記事をご覧ください。
インスタンスの作成と秘密鍵の設定が完了しましたら、アクセスサーバーおよびインスタンスに接続をします。
本記事ではJupyterLabおよびTensorBoardを使用するため、上記の手順書のインスタンス接続のコマンドと異なりますので、ご注意ください。
アクセスサーバーへの接続
インスタンスへの接続方法
インスタンス接続が完了しましたら、PyTorch、JupyterLabをインストールします。
(参考)PyTorchのインストール(Ubuntu)の記事
(参考)Jupyter Labのインストール(Ubuntu)の記事
Jupyterを起動したら、下記のライブラリをインストールします。
データセットの準備
ニュース記事のデータセットを準備します。
次のコマンドでlivedoorニュースコーパスをダウンロードします。
ダウンロードしたファイルを解凍し、解凍後のディレクトリについて、カテゴリーの数とカテゴリー名を表示します。

ニュースカテゴリー数は9であることが分かります。
また出力されたカテゴリは、冒頭で紹介したlivedoorのニュースカテゴリに対応しています。
topic-news : トピックニュース
sports-watch : Sports Watch
it-life-hack : ITライフハック
kaden-channel : 家電チャンネル
movie-enter : MOVIE ENTER
dokujo-tsushin : 独女通信
smax : エスマックス
livedoor-homme : livedoor HOMME
peachy : Peachy
続いてニュース記事が格納されているディレクトリ内のニュース記事のテキストファイルを読み込み、テキストとそれに対応するラベル(カテゴリ)をセットとして格納します。

出力結果は、ニュース記事のファイル数は7367件で、ニュース記事カテゴリのディレクトリが9つであることを表しています。
次にデータを学習データとテストデータに分割し、csvファイルとして保存します。

モデルとTokenizerの読み込み
日本語の事前学習済みBERTモデルと、これに紐づいたTokenizerを読み込みます。
BertForSequenceClassificationは、BERT学習済みモデルに分類レイヤーを追加した構成となり、テキスト文の分類タスクに対応するものです。BertJapaneseTokenizerは、日本語の文を単語(トークン)に分割し、それぞれのトークンに対してIDを割り当てます。IDを割り当てることにより、テキストデータが数値データとして処理され、モデルが理解できるようになります。
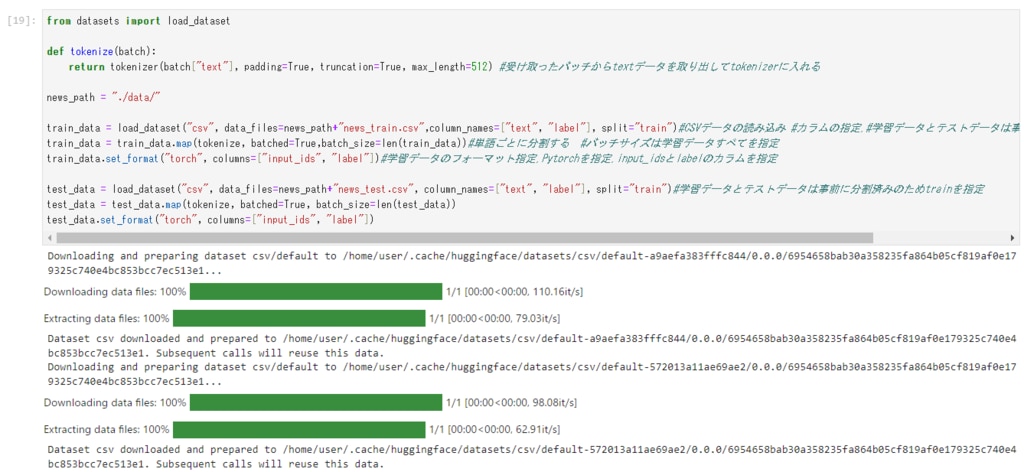
datasetsモジュールを使用して、ニュース記事のデータセットを読み込み、tokenizerでトークン化(単語分割)を行い、データフォーマットの指定をします。
評価関数の定義
sklearn.metricsを使用し、モデルを評価するための関数を定義します。
accuracy_scoreは、分類モデルの予測結果の正解率(accuracy)を計算します。全サンプルのうち、予測結果と実際の正解クラスが一致する数の割合が正解率になります。

Trainerの設定
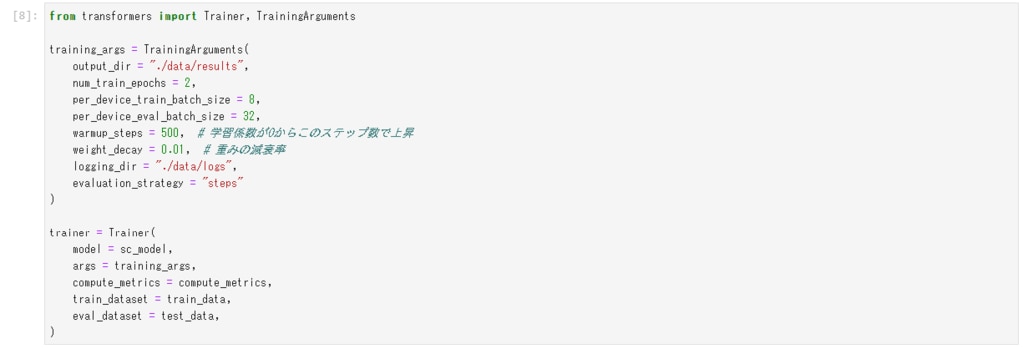
学習を行うTrainerの設定を行います。TrainerはHuggingfaceが提供するモデル学習と評価を簡単に行うためのクラスです。
Trainerでは、学習モデルや評価関数、データセットなどの指定を行います。TrainingArgumentsでは、ハイパーパラメータを指定するものです。エポック数やバッチサイズ、学習率スケジューラ、重みの減衰率などを指定しています。
モデルの学習
上記の設定に基づきファインチューニングを行います。
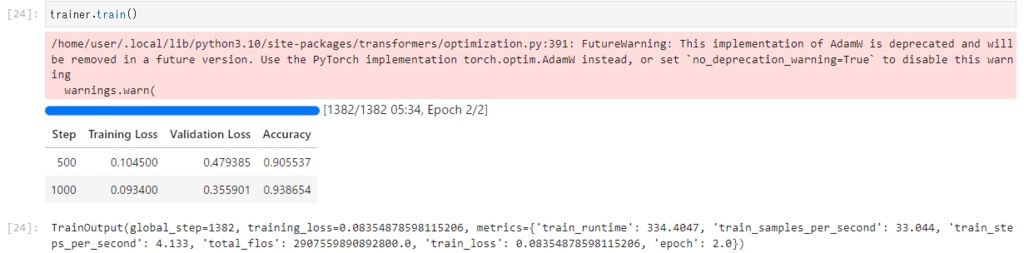
GPUSOROBANのnvd4-80-1ulインスタンスでは、5分34秒で学習が完了しました。
Google Colaboと比較するためにバッチサイズを8に設定しましたが、バッチサイズを上げてさらに学習時間を短縮することもできます。
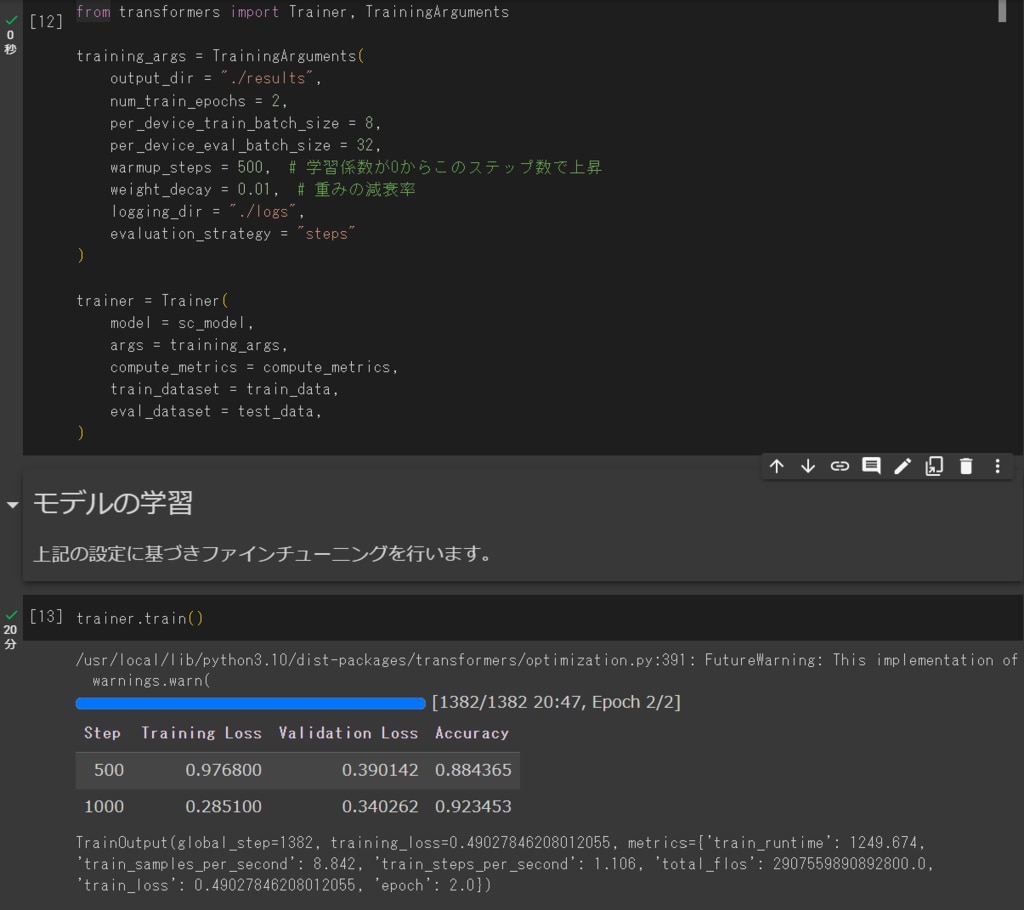
一方Google ColaboのNVIDIA T4インスタンスでは、学習の完了までに20分47秒かかりました。
(Google colaboの学習結果↓)
続いてTrainerのevaluate()メソッドによりモデルを評価します。
評価の結果は後のTensorBoardでグラフとともに確認します。

結果の確認
TensorBoardを使って、logsディレクトリに格納された学習過程を表示します。
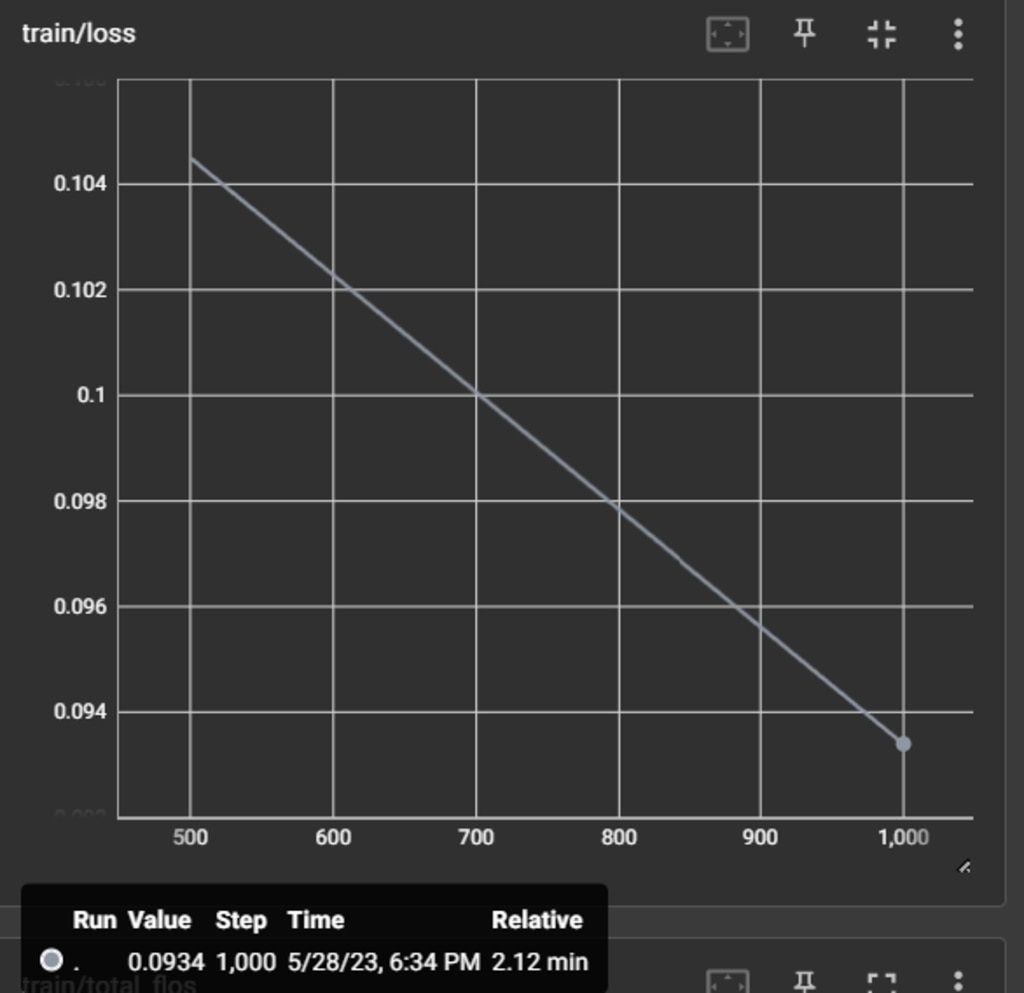
学習時の誤差(loss)は、0.934になりました。
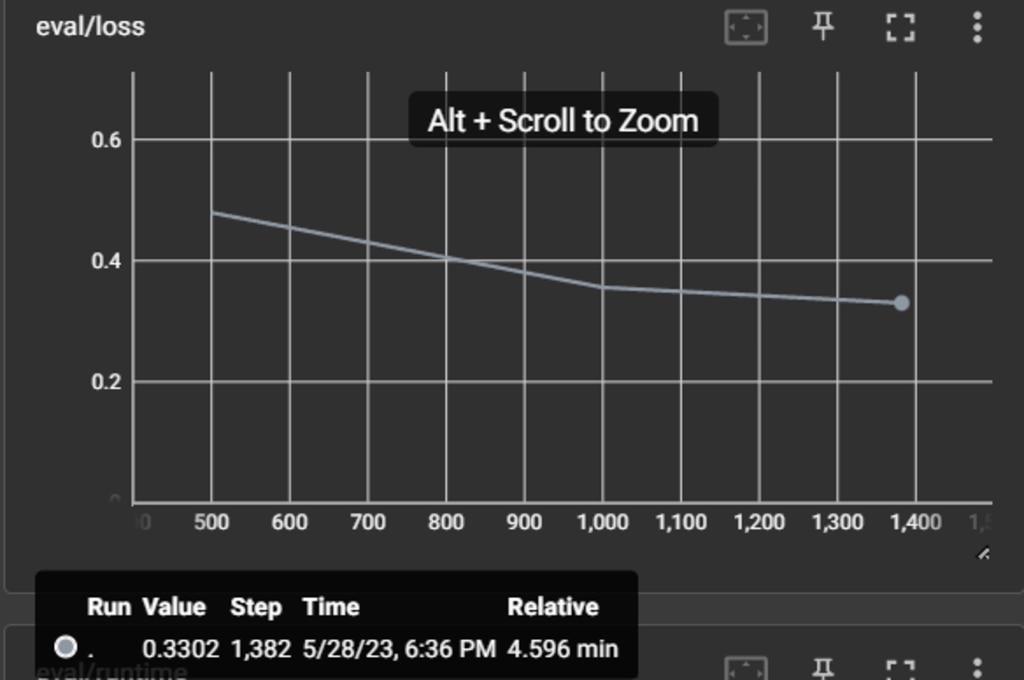
評価時の誤差(loss)は0.33です。
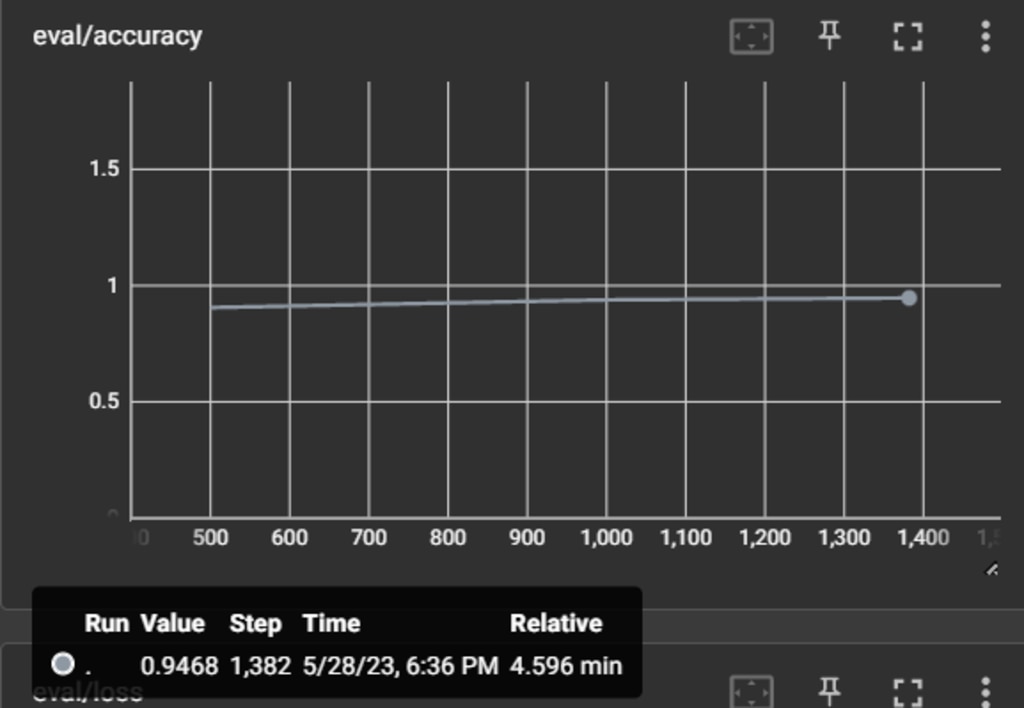
評価時の精度(accuracy)は0.94であるため、分類の精度が94%になることが分かります。
学習済みのモデルを保存します。

読み込んだモデルを使いニュースを分類します。
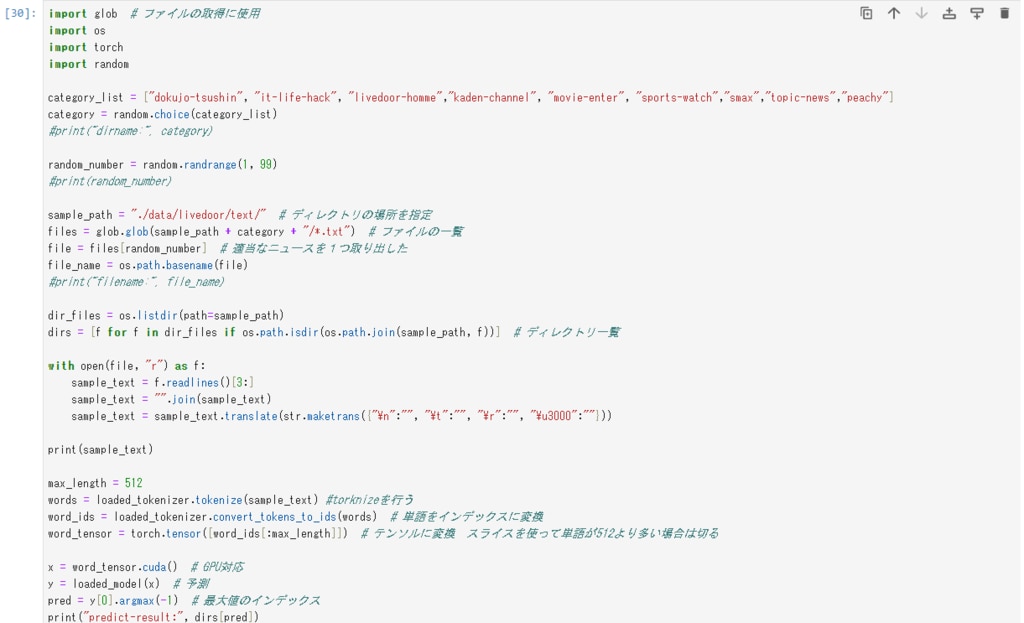
以下にニュースの分類結果をいくつか紹介します。
次の記事は、movie-enter(MOVIE ENTER )のカテゴリに分類されています。
記事の内容は映画になっているので、記事内容とカテゴリは一致していることが分かります。

次の記事は、dokujyo-tsushin(独女通信 )のカテゴリに分類されています。
独女通信は独身女性の心理を取り上げるニュースとのことで、記事内容とカテゴリは合っています。

次の記事は、kaden-channel(家電チャンネル)のカテゴリに分類されています。
家電に関する記事内容になりますので、カテゴリと一致しています。

次の記事は、sports-watch(Sports Watch)のカテゴリに分類されています。
記事の内容はスポーツに関することですので、正しく分類されています。

次の記事は、it-life-hack(ITライフハック)のカテゴリに分類されています。
ITサービスに関する事が書かれているため、カテゴリと一致しています。

BERTでニュース記事のカテゴリを分類する実装の説明は以上になります。
本環境には、GPUSOROBANのインスタンスを使用しました。
GPUSOROBANは高性能なGPUインスタンスが低コストで使えるクラウドサービスです。
サービスについて詳しく知りたい方は、GPUSOROBANの公式サイトをご覧ください。


