
【文字起こしAI】Whisperによる自動文字起こし
本記事ではGPUSOROBANのインスタンスを使ったWhisperによる音声入力からの文字書き起こしを紹介します。
GPUSOROBANは高性能なGPUインスタンスが低コストで使えるクラウドサービスです。
サービスについて詳しく知りたい方は、GPUSOROBANの公式サイトをご覧ください。
目次[非表示]
- 1.Whisperとは
- 2.Whisperのアーキテクチャ
- 3.Encoderの前処理
- 4.Encoder
- 5.Decoderの前処理
- 6.Decoder
- 7.環境構築
- 8.録音データの文字起こし
Whisperとは
Whisperは、ChatGPTで有名なOpenAIが公開した音声認識モデルです。このモデルは音声データをテキストに変換することができ、テキストの書き起こしや他言語への翻訳などが可能です。約68万時間もの膨大な音声データをインターネットから収集し、これに基づいて学習を行いました。その結果、日本語を含む99言語において高精度な音声認識を実現しています。大規模かつ多様なデータセットで学習したことにより、アクセントやノイズ、専門用語への対応も優れています。
Whisperのアーキテクチャ
Whispeの中核は、EncoderとDecoderから構成されるTransfomerモデルです。TransfomerのモデルはChatGPTにも使われています。Encoderは音声入力から潜在表現を取得し、Decoderは潜在表現からテキストを出力します。アーキテクチャの各要素について、それぞれ説明します。
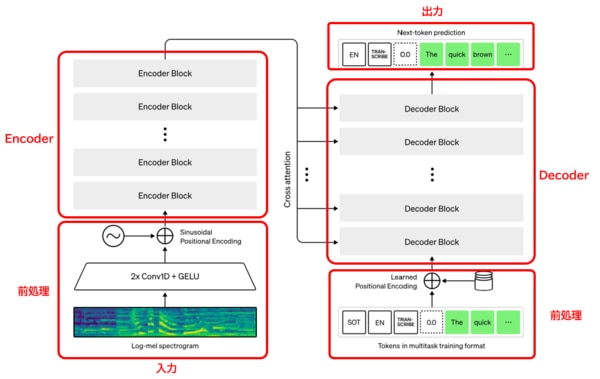
参考:https://openai.com/research/whisper
Encoderの前処理
Encoderの前処理では、「Log-mel spectrogram」による音声信号のメル尺度変換、「Embedding」による音声信号のベクトル変換、「Positinal Encoding」による位置情報の付加を行います。
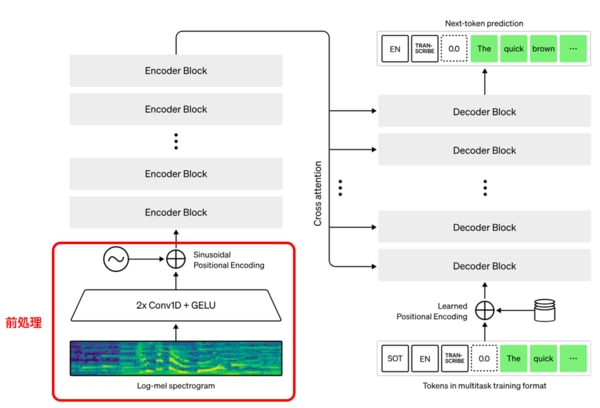
音声ファイルは、Log-mel spectrogramで音声信号の周波数成分をメル尺度に変換します。メル尺度は人間の聴覚特性に基づいて設計された尺度であり、周波数軸を非線形にスケーリングすることで音の高さの知覚的な特性を表現します。Log-mel spectrogramでは、以下の図のように周波数(Hz)、時間(Time)、強度(db)で表されます。
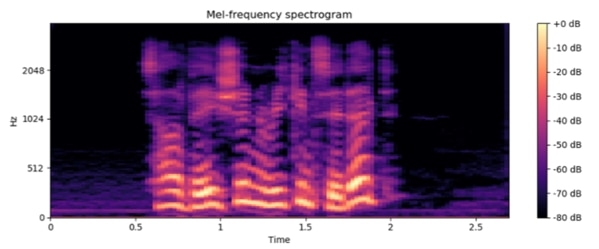
引用:https://arxiv.org/abs/2109.07916
Embedding(埋め込み層)では、spectrogramデータから得られた一つ一つの単語をベクトル表現に変換します。
Positional Encodingは、文中における単語の位置情報をモデルに付加する役割を持ちます。トークン埋め込み層とアテンション層だけでは各トークンの位置情報を埋め込めないため、Position
Encodingを用います。
Position Encodingがない場合、["私", "の", "趣味", "は", "盆栽", "だ"]と["盆栽", "の", "趣味", "は", "私", "だ"]が、同じのものになってします。Position Encodingで足し合わされる値は、Sin関数で表現されるため、得られる波形が位置や次元に対してユニークになり、単語間の相対的な位置関係が得られる特徴があります。
Encoder
Encoderは、Encoder blockの多層で構成されています。Encoder blockの中身は主にSelf-attentionで構成されます。self-atterntionは、Self-AttentionはTransformerの根幹をなす機構であり、文章中の単語同士の関連度をスコア化するものです。このAttentionの機構は、ChatGPTの中核でもあり、Attentionに関する論文である「Attention is all you need」(必要なのはAttentionだけである)は、自然言語処理の業界に衝撃を与えました。
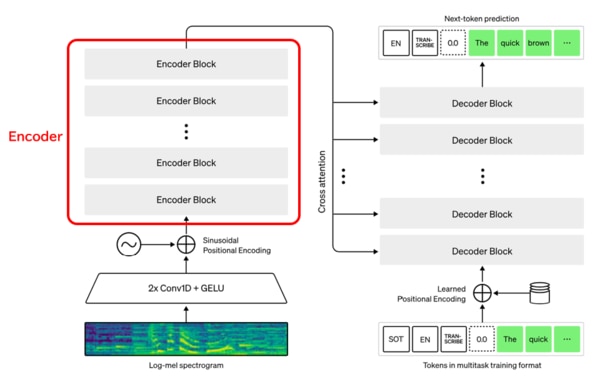
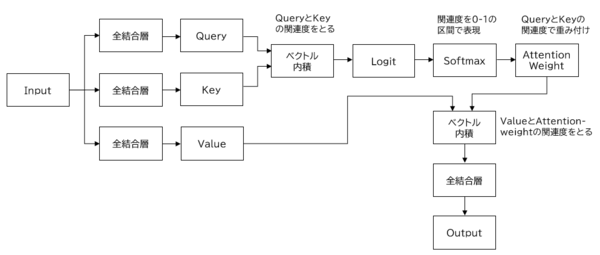
Self-attentionは、Query、Key、Valueに同じデータをインプットする構造になっており、入力した単語同士がどこに注目度(関連度)が高くなるかを測るものです。
まずQueryとKeyのベクトル内積(のようなもの)で関連度を測り、この関連度をAttention Weightという形で表現し、次にAttention WeightとValueの関連度をベクトル内積で測るプロセスになります。
例えば、["木", "を", "精神的", "に", "鑑賞", "する", "こと", "が", "盆栽", "の", "奥深さ", "だ"]という文章をインプットするとき、“盆栽”をQueryとした場合、関連度が高いKeyは”木”になります。”盆栽”と”木”の内積によって表現されるAttention Weightに対して、関連度が高いValueは”鑑賞”になります。
このようなイメージでself-attentionは単語同士の関連度を計算しています。
Self-attentionを使うことで、同一文章内の類似度が獲得され、特に多義語や代名詞などが実際に何を指しているかが理解しやすくなりました。
Decoderの前処理
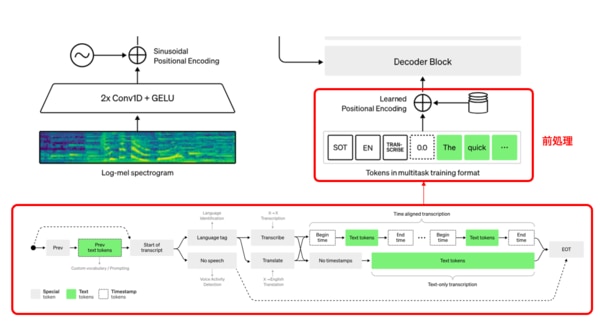
同じ音声信号の入力においても、書き起こし、翻訳、音声検出、言語識別などの様々なタスクがあるため、Decoderとしては、まず何のタスクをすべきか決定する必要があります。そのためDecoderの前処理では、次のような決定をします。
入力音声に音声が含まれるかを確認し、音声が含まれない場合はNo speechトークンを予測します。入力音声の音声が含まれる場合、言語固有のトークンを予測し、言語識別をします。次に優先タスクが書き起こしである場合は、Transcribeトークンを予測します。優先タスクが翻訳である場合は、Translateトークンを予測します。最後にnotimestampsトークンを含めることで、タイムスタンプを予測するかどうかを決めています。
まとめると想定されるすべてのタスクの流れは次のパターンになります。
・入力音声 → 音声なし
・入力音声 → 言語識別 →文字起こし→ タイムスタンプ
・入力音声 → 言語識別 →文字起こし→ タイムスタンプなし
・入力音声 → 言語識別 →翻訳→ タイムスタンプ
・入力音声 → 言語識別 →翻訳→ タイムスタンプなし
これらの情報にPositional Encoderで位置情報を付加して、Decoderに渡します。
参考:https://openai.com/research/whisper
Decoder
DecoderはEncoderおよび前処理されたデータをインプットし、潜在表現からテキストの出現確率を予測して出力します。
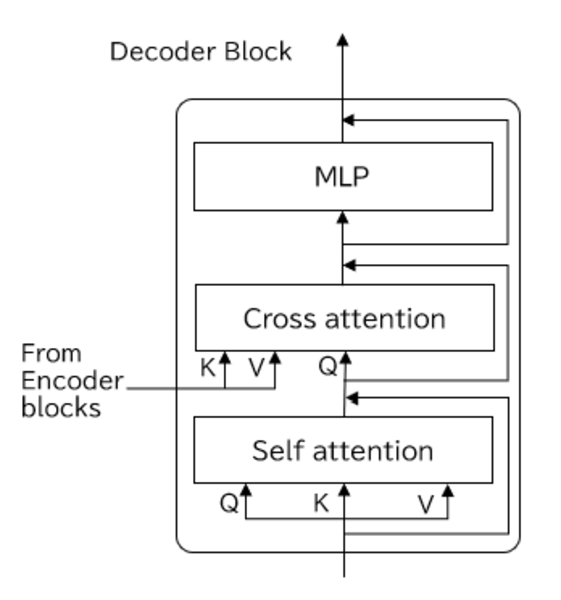
Decoderは多層のDecoder blockから構成され、Decoder blockの中身も主にself-attentionになります。
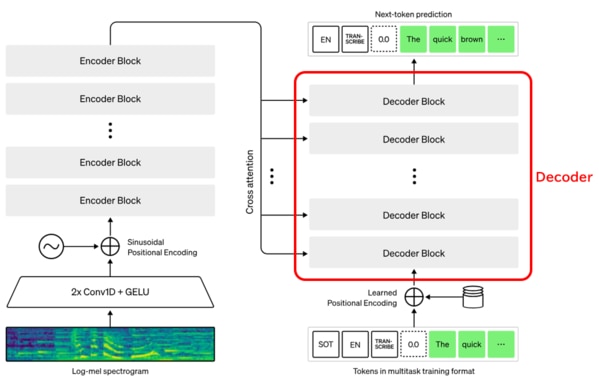
Decoder Blockには、self-attentionに加えて、Cross-attentionという機構があります。
Cross-attentionのしくみはSelf-attentionと似ていますが、入力がEncoderと前の層のSelf-attentionになる点が異なります。EncoderからはKey,Valueが渡され、前の層のSelf-attentionからはQueryが渡されます。
環境構築
環境はGPUSOROBANのs16-1-aインスタンスを使用します。
s16-1-aインスタンスは、NVIDIA A4000を搭載した高性能GPUインスタンスです。機械学習を高速化するTensorコアを搭載し、NVIDIA T4の2倍以上高速な演算性能を持ちます。
GPUSOROBANのインスタンスの作成方法、秘密鍵の設置方法については、会員登録~インスタンス作成手順の記事をご覧ください。
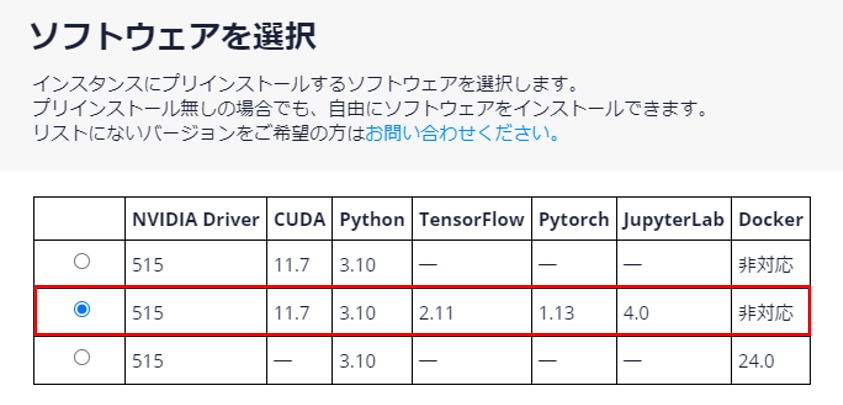
インスタンス作成時に以下のプリインストールが含まれるソフトウェアを選択してください。
- Python 3.10
- PyTorch 1.13
- Jupyter Lab
インスタンスの作成と秘密鍵の設定が完了しましたら、アクセスサーバーおよびインスタンスに接続をします。
本記事ではJupyterLabを使用するため、上記の手順書のインスタンス接続のコマンドと異なりますので、ご注意ください。
アクセスサーバーへの接続
インスタンスへの接続方法
Jupyterを起動後に、音声入力するデータをインスタンスにアップロードし、ファイルを確認します。
インスタンスにファイル転送する方法は以下の記事で解説しています。

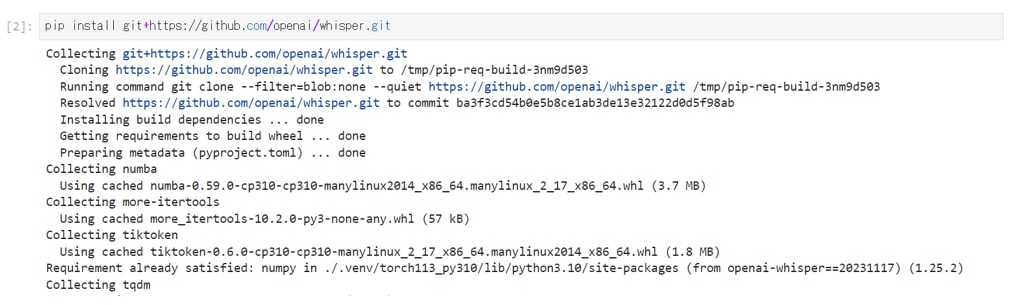
GitHubでOpenAIが公開しているWhisperのパッケージをインストールします。
パッケージをアップデートします。
音声ファイルのフォーマットを変換するffmpegをインストールします。
Whisperをインポートします。

WhisperのLargeモデルを読み込みます。

Whisperのモデルサイズは 5 つあり、モデルのサイズが大きいほど精度が高くなる一方で速度が遅くなるトレードオフの関係です。
今回は精度の高いLargeモデルを選択しました。

引用:https://github.com/openai/whisper
録音データの文字起こし
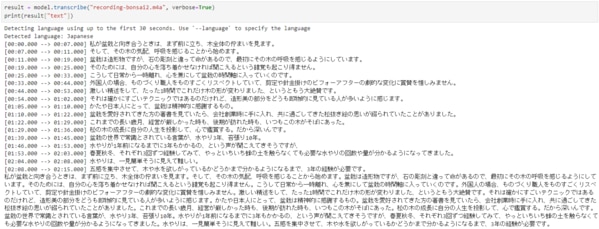
録音時間2分程度の音声ファイルを入力し、文字起こしを行います。
出力結果を見ると、ほぼ完璧な文字起こしができていました。実行時間は、1文につき最大8秒くらいで処理できています。
verbose=Trueを指定することで1文ごとの時間も表示できるため、議事録の修正する際に、録音データを確認する作業でも活用できそうです。
Whisperによる文字書き起こしの説明は以上になります。
本環境には、GPUSOROBAN(高速コンピューティング)のインスタンスを使用しました。
高速コンピューティングは高性能なGPUインスタンスが低コストで使えるクラウドサービスです。
サービスについて詳しく知りたい方は、公式サイトをご覧ください。


