
【画像生成AI】DCGANで手書き文字の生成
本記事では、GPUSOROBANのインスタンスを使った、DCGANによる画像生成の例を紹介します。
GPUSOROBANは高性能なGPUインスタンスが低コストで使えるクラウドサービスです。
サービスについて詳しく知りたい方は、GPUSOROBANの公式サイトを御覧ください。
目次[非表示]
- 1.DCGANとは
- 2.環境構築
- 3.学習に使う手書き文字画像の確認
- 4.各設定、データの前処理
- 5.Generatorのモデル構築
- 6.Discriminatorのモデル構築
- 7.画像の生成・表示
- 8.正解数の定義
- 9.学習の実行
- 10.誤差と正解率の推移
DCGANとは
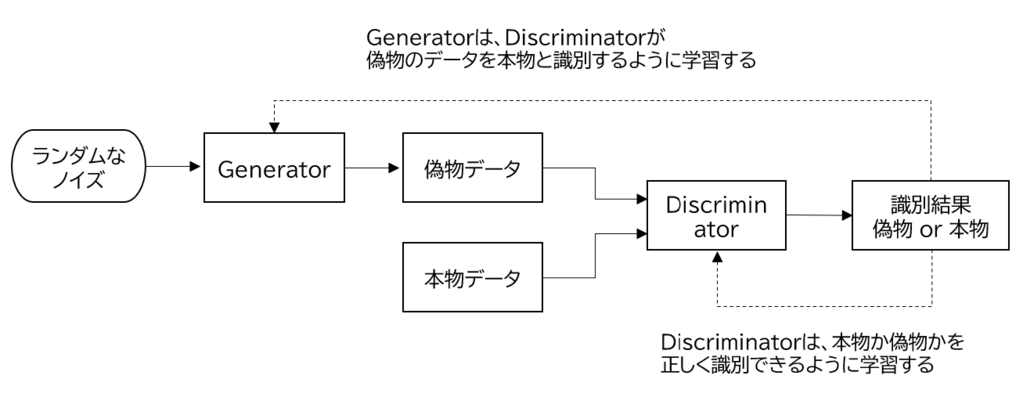
DCGANとは、Generator(生成器)とDiscriminator(識別器)の2つのモデルを互いに競わせるように学習して、生成を行うGANの派生モデルになります。
Generatorは、ランダムなノイズを入力として、Discriminatorが本物と誤認しするデータを生成できるように学習します。一方でDiscriminatorは、本物のデータとGeneratorが生成した偽物のデータを正しく識別できるように学習します。
下図は、GeneratorとDiscriminatorがどのように学習をしているかを示す概念図になります。
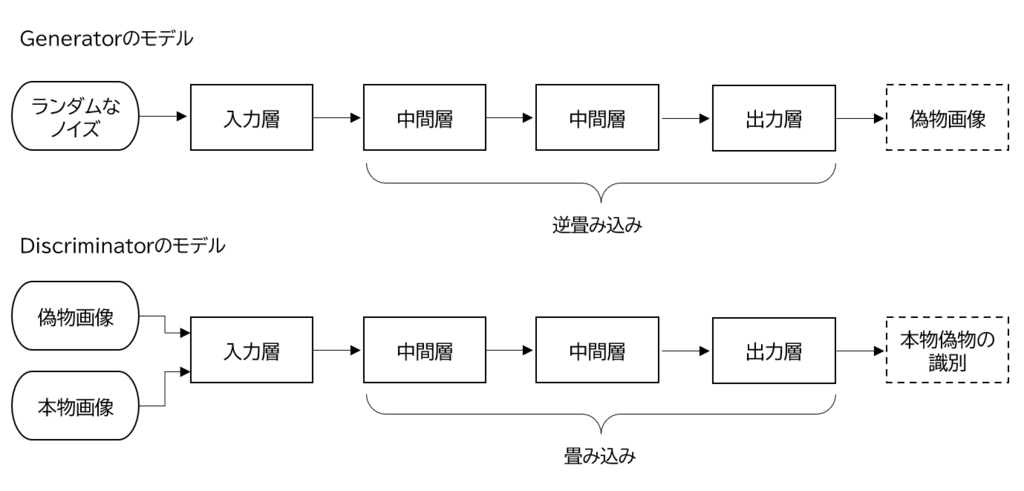
下図は本記事で実施する、手書き文字の画像を生成するモデルの構成になります。
DCGANの特徴として、Generatorに逆畳み込み層、Discriminatorに畳み込み層を使うことで、GANよりも自然な画像の生成をすることができます。
環境構築
環境はGPUSOROBANのインスタンスを使用します。GPUSOROBANは、高性能なGPUインスタンスが格安で使えるクラウドサービスです。インスタンスの作成方法、接続方法はこちらの記事を御覧ください。
インスタンス起動後、PyTorch、matplotlib、scikit-learn、JupyterLabの4つのライブラリをインストールします。
PyTorchのインストールについては、こちらの記事をご参照ください。
matplotlibとscikit-learnについては、下記のコマンドでインストールします。
JupyterLabを使用する場合は、こちらの記事を参考にJupyterLabのインストールから起動までを実行してください。
学習に使う手書き文字画像の確認
DCGANに用いる学習用のデータを用意します。
scikit-learnから、8×8の手書き数字の画像データを読み込んで表示します。
次ような画像が表示されます。こちらが学習で使うデータになります。
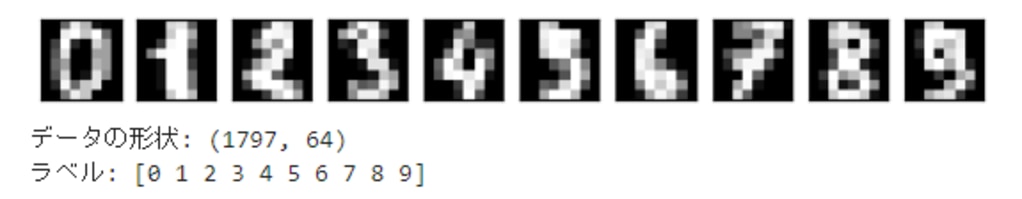
各設定、データの前処理
DCGANに必要な各種パラメータの設定から、データの読み込み、前処理を行います。
Generatorのモデル構築
Pytorchのnnモジュールを使って、Generatorのモデルを構築します。
Generatorでは逆畳み込み層を3層重ねた構成で、ノイズから画像を生成します。
逆畳み込み層はPytorchのConvTranspose2dにより実装します。
出力層の活性化関数には、Discriminatorへの入力を-1から1の範囲にするためにtanhを使います。
Discriminatorのモデル構築
PyTorchのnnモジュールを用いて、Discriminatorのモデルを構築します。
Discriminatorでは、畳込み層を3層重ねて画像の特徴を抽出します。
最後の層の活性化関数には、0から1までの値で本物かどうかを識別するためにsigmoid関数を使います。
逆伝播での勾配消失問題に対処するために、活性化関数にLeakyReLUを使用しています。通常のReLUでは負の入力で、0が出力されるため、微分ができず勾配消失に陥る可能性があります。LeakyReLUは負の入力に対し、微小な負の値を出力することができます。微分値が常に0にならないので、勾配消失問題の対処が可能です。
画像の生成・表示
画像を生成して表示するための関数を定義します。
画像は、学習済みのGenertorにノイズを入力することで生成されます。
画像は16×16枚生成されますが、並べて一枚の画像にした上で表示されます。
正解数の定義
Discriminatorによる識別の正解数を、カウントする関数を定義します。
Discriminatorの精度の計算に使用します。
学習の実行
構築したDCGANのモデルを使って、学習を行います。
Generatorが生成した偽物の画像には正解ラベル0、本物の画像には正解ラベル1を与えてDiscriminatorを学習します。その後にGeneratorを学習しますが、この場合の正解ラベルは1になります。
損失関数には、二値の交差エントロピー誤差を使用し、オプティマイザーにはAdamを使用しています。
下図は、未学習(Epoch:0)時点の出力画像になります。完全なノイズで数字の形をしていません。

下図は、学習途中(Epoch:20)時点の出力画像になります。若干数字のような形になってきています。

下図は、学習完了(Epoch:200)時点の出力画像になります。正解データに近い画像が生成されています。

参考までに正解データはこちらです。
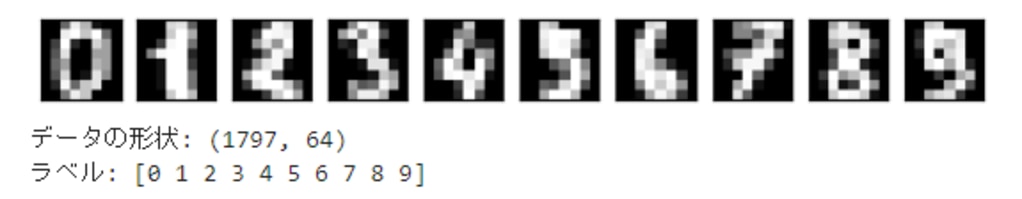
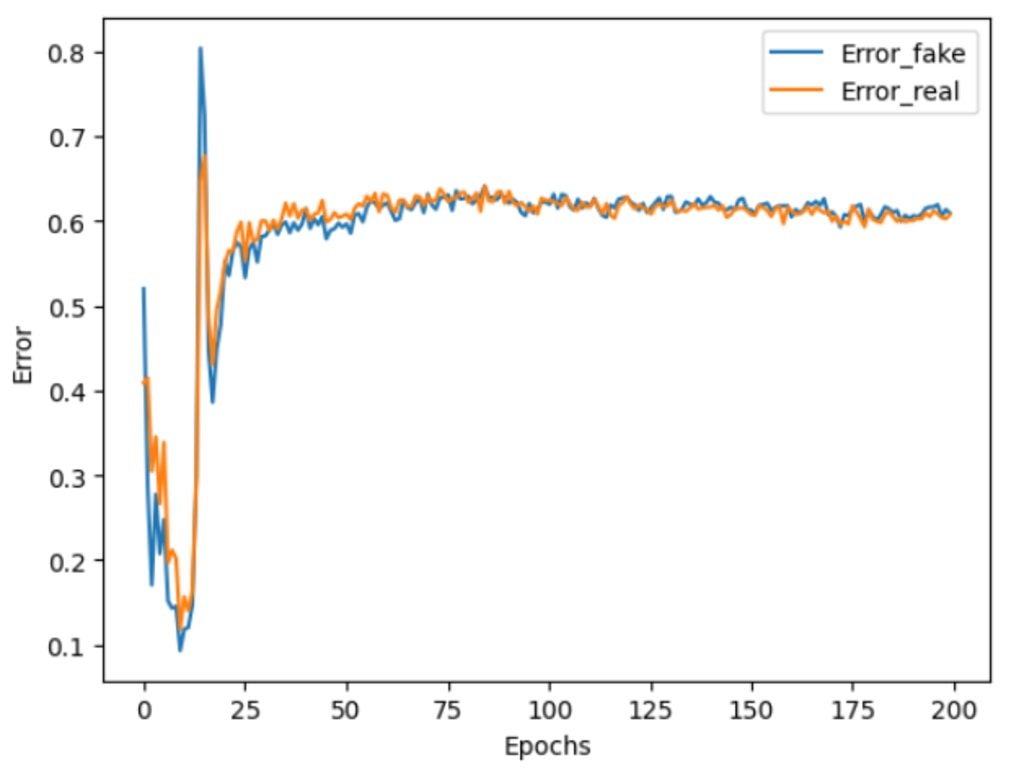
誤差と正解率の推移
学習中における、誤差と正解率の推移を確認します。
Discriminatorに本物画像を識別した際の誤差の推移と、偽物画像の識別した際の誤差の推移をグラフに表示します。併せて正解率の推移も表示します。
誤差の推移
正解率の推移
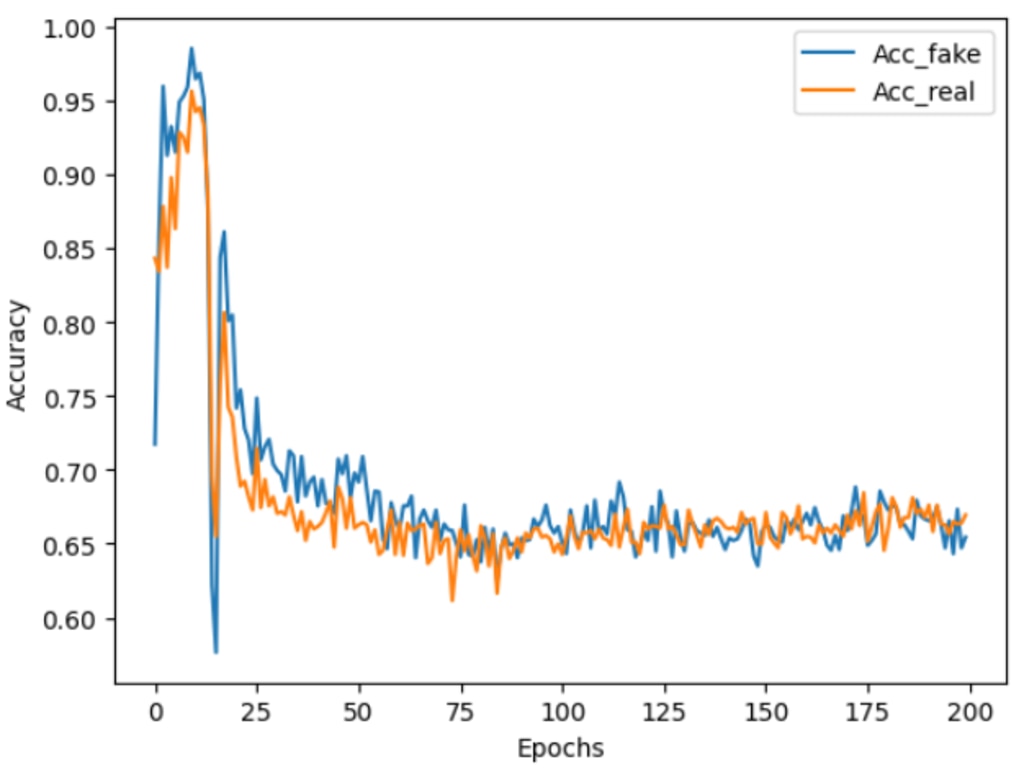
DCGANで画像生成をして、GeneratorとDiscriminatorが競合するように学習し、その結果生じた均衡のなかで、本物らしい画像が形作られていくことが確認できました。
本環境には、GPUSOROBANのインスタンスを使用しました。
GPUSOROBANは高性能なGPUインスタンスが低コストで使えるクラウドサービスです。
サービスについて詳しく知りたい方は、GPUSOROBANの公式サイトを御覧ください。


